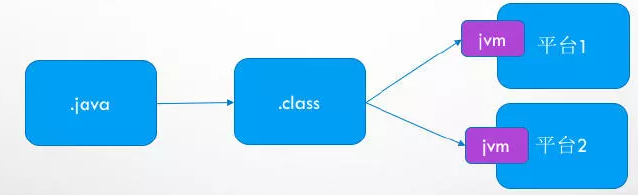
极品上门女婿秦浩还以这个图为例,从.java到.class是编译过程,从.class到机器码是解释过程。下面对其进行分别优化。在优化过程中,对编译阶段的优化主要是对前端编译器的优化,在运行阶段的优化,主要是对即时编译器的优化。
| 编译器优化 |
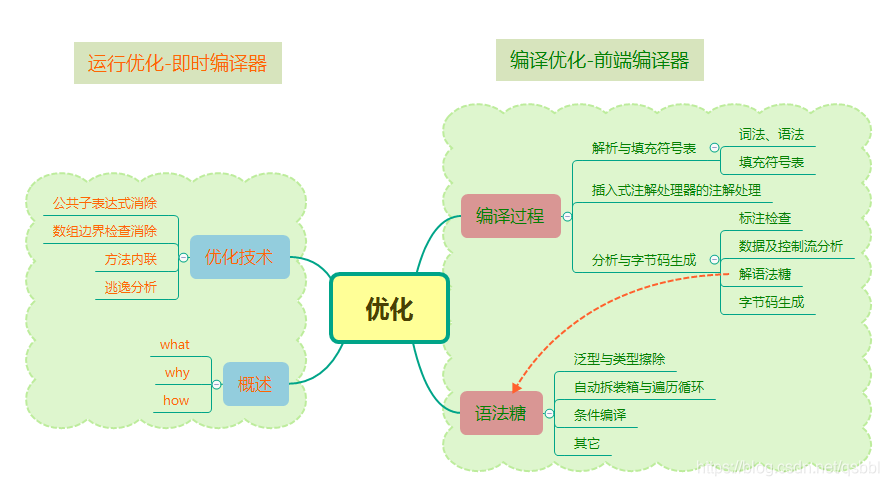
编译过程

以上为javac的编译过程图,以下为javac编译过程的主体代码。
下面对其步骤进行详细解读
1、解析与填充符号表
词法分析
将蜜婚娇妻爱逃跑源代码的字符流转变为标记(Token)集合,标记是编译过程中的最小元素,如a,=,b,int。
语法分析
根据Token序列构造抽象语法树。以后编译器基本不会再对源码文件进行操作了,后续的操作都是建立在抽象语法树上。抽象语法树是一种用来描述程序代码语法结构的树形表示方式,节点代表代码中的一个语法结构,例如鱼跃龙门张牧修饰符,返回值等。
填充符号表
符号表是由一组符号地址和符号信息构成的表格,用于编译的不同阶段。如在语义分析中,用于语义检查和产生中间代码;在目标代码生成阶段,用于地址分配的依据。
2、注解处理器
这部分是插入式注解处理器在编译期间对注解进行处理的过程。其可以对语法树进行修改,一旦公子强娶进行了修改,编译器将回到上面的第一步进行重新处理,每一次循环称为一个Round,也就是上图中的回环过程。
3、语义分析与字节码生成
在经过语法分析后,生成的语法树是一个结构正确的源程序的抽象,但无法保证源程序是符合逻辑的。语义分析的任务是对结构上正确的源程序进行上下文有关性质的审查。比如鉴绿茶专家男主下面代码中的错误只能在语义分析阶段检查出来。
boolean a=false; char b=2; int c=a+b
此阶段包括如下4个步骤:
标注检查
变量使用前是否已被摄政王妃娇宠日常声明、变量与赋值之间的数据类型是否能够匹配等。还有一个常量折叠,即把a=1+2变为a=3。所以在代码中的a=1+2和a=3并不会增加程序运行期cpu指令的运算量。
数据及控制流分析
检查程序局部变量在使用前是否有赋值,方法的每条路径是否都有返回值,是否所有的受查异常都被正确处理了等问题。在类加载时也有一个数据及控制流分析,其目的基本是一致的,但校验的范围不同,有些校验项只有在编译期或运行期才能运行。
解语法糖
语法糖是在计算机语言中添加某种语法,修仙之论路人甲的修仙日常其对语言的功能没有影响,但是能提高程序的可读性。语法糖包括泛型,自动拆装箱等。虚拟机运行时不支持这些语法,它们在编译阶段还原回基础语法结构。这个过程称为解语法糖。
字节码生成
将之前步骤生成的信息(语法树、符号表)转化成字节码写到磁盘中,然后添加和转换了少量的代码。如把字符串的加操作替换为StringBuffer或StringBuilder的append()操作。
至此,Class文件生成了。
语法糖
语法糖是java中添加某种语法,对语言的功能没有影响,但是可以增加程序的可读性。包括泛型、内部类、枚举类等。

1、泛型与类型擦除
泛型可用于类、接口和方法的创建中,用于对放入集合元素的类型的约束。泛型只在程序源码中存在,在编译阶段有解语法糖的步骤,所以在.Class文件中,已经变为了原来的原生类型了。乡野桃花这个过程叫做类型擦除。
泛型擦除前:
public static void main(String[] args){
Map<String,String> map=new HashMap<>();
map.put("姓名","小明");
map.put("性别","男");
sout(map.get("姓名"));
sout(map.get("性别"));
}
泛型擦除后:
public static void main(String[] args){
Map map=new HashMap();
map.put("姓名","小明");
map.put("性别","男");
sout((String)map.get("姓名"));
sout((String)map.get("性别"));
}
所以ArrayList和ArrayList在运行期时是同一个类。
2、自动拆装箱、循环遍历
这些是java中使用最多的语法糖。编译前:
public static void main(String[] args){
List<Integer> list=Arrays.asList(1,2,3,4);
int sum=0;
for(int i:list){
sum +=i;
}
System.out.println(sum);
}
编译后:
public static void main(String[] args){
List list=Arrays.asList(new Integer[] {
Integer.valueOf(1),
Integer.valueOf(2),
Integer.valueOf(3),
Integer.valueOf(4)});
int sum=0;
for(Iterator localIterator=list.iterator();localIterator.hasNext();){
int i=((Integer)localIterator.next()).intValue();
sum +=i;
}
System.out.println(sum);
}
可见,他的手很撩人自动拆装箱在编译后被转化为了对应的包装和还原方法,如Integer.valueOf()和Integer.intValue()。
遍历循环则把代码还原为了迭代器的实现。
3、条件编译
根据布尔常量值的真假,编译器会把分支中不成立的代码块消除掉。
public static void main(String[] args){
if(true){
sout("block 1");
}else{
sout("block 2");
}
}
编译后,代码变为:
public static void main(String[] args){
sout("block 1");
}
| 运行期优化 |
一般情况下,我们将.java编译成.class,.class再解释成机器码。但是也有特殊的情况。有些代码调用比较频繁,比如某个方法或代码块的运行特别频繁,为了提高程序的执行效率,在运行时,虚拟机会把这个代码直接编译成机器码,并进行各种层次的优化。这样的代码称为热点代码。完成这个任务的编译器被称为即时编译器。但是其并不是虚拟机必需的部分。
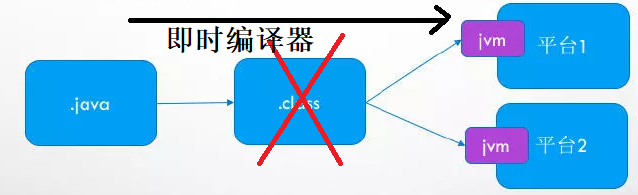
即时编译器的概述
(1)为什么虚拟机要使用解释器和编译器并存的架构?
虚拟机里包含着解释器和编译器。当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。
当程序运行环境中内存资源限制较大,可以使用解释执行节约内存,反之可以使用编译来提升效率。
(2)为什么虚拟机要实现两个不同的即时编译器?
虚拟机中内置了两个即时编译器,分别为Client Compiler和Server Compiler,又称为C1和C2。
默认只使用其中的一个,至于选择哪个,取决于虚拟机会根据自身版本和宿主机器的硬件性能自动选择运行模式。用户也可以使用“-client”、“-server”进行指定。
(3)程序何时使用解释器执行?何时使用编译器执行?
虚拟机生活系神豪有一个分层编译策略。
第0层:程序解释执行,解释器不开启性能监控功能,可触发第1层编译
第1层:也称为C1编译,将字节码编译为本地代码,进行简单、可靠的优化,如有必要将加入性能监控的逻辑。
第2层:也称为C2编译,将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
(4)哪些程序代码会被编译为本地代码?如何编译为本地代码?
热点代码包括如下两类,其均把整个方法作为编译对象。
a、被多次调用的方法
b、被多次执行的循环体
热点探测是用来判断一段代码是否为热点代码,其方式有两种:
a、基于采样
b、基于计数器。HotSpot使用的是这种。它为每个方法准备了两类计数器:统计方法被调用次数的方法调用计数器和统计一个方法中循环体代码执行次数的回边计数器。
(5)如何从外部观察及时编译器的编译过程和编译结果?
可以使用 -xx:+PrintCompilation 查看哪些方法被即时编译器编译了。
优化技术有哪些?
虚拟机的即时编译器在生成代码时,采用了如下的代码优化技术。
- (1)公共子表达式消除
如果一个表达式E已经计算过了,那如果再次出现E时就不会再对它进行计算。比如:
int d=(a*b)*12+c+(c+b*a)
如果这段代码交给javac编译器,则不会进行任何优化。如果交给即时编译器,会被进行如下步骤的优化:
第一步:消除公共子表达式
int d=E*12+c+(c+E)
第二步:代数化简:
int d=E*13+c*2
(2)数组边界检查消除
数组边界检查是什么?
如果有一个数组foo[],在java语言中访问数组元素foo[i]的时候,系统将会自动进行上下界的范围检查,检查i是否满足0≤i≤foo.length这个条件。
那怎么进行消除呢?
a、把运行期检查提到编译期完成。如foo[3],只要在编译期根据数据流分析来确定foo.length的值,并判断下标“3”没有越界,执行的时候就不用判断了。
b、隐式异常处理。这种思路通常用于空指针检查和算符运算中除数为零的情况。
if(foo!=null){
return foo.value;
}else{
throw new NullPointException();
}
被隐式异常处理优化后,变为如下代码:
try{
return foo.value;
}catch(segment_fault){
uncommon_trap();
}
除了数组边界检查消除,还有自动装箱消除、安全点消除、消除反射等。
- (3)方法内联
把目标方法的代码“复制”到发起调用的方法之中,避免发生真实的方法调用。
public int add(int x1, int x2, int x3, int x4) {
return add1(x1, x2) + add1(x3, x4);
}
public int add1(int x1, int x2) {
return x1 + x2;
}
运行一段时间后JVM会把add1方法去掉,并把代码翻译成:
public int add(int x1, int x2, int x3, int x4) {
return x1 + x2 + x3 + x4;
}
(4)逃逸分析
当一个对象在方法中被定义后,它可能被外部方法所引用,比如作为调用参数传递到其它方法中,这称为方法逃逸。同理,如果被外部线程访问到,它就称为线程逃逸。
对变量进行相应分析就叫做逃逸分析。如果能证明别的方法或线程无法通过任何途径访问到这个对象,则可以为这个变量进行一些优化。
优化的手段有栈上分配、同步消除、标量替换等。以同步消除为例,如果逃逸分析能够确定一个变量不会逃逸出线程,即无法被其它线程访问到,那对这个变量实施的同步措施就可以消除掉了。