1. 引用的实现原理
引用一般的概念称为变量的别名,定义的时候必须初始化绑定一个指定对象,且中途不可更改绑定对象,那么引用的原理是怎样的呢?
先看一段简单的代码测试
class SimpleReference {
private:
char& m_r;
};
void PrintSimpleReference(){
std::cout << "Size of the class with a simple reference is " << sizeof(SimpleReference) << std::endl;
}
输出结果
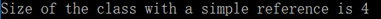
可以看到只有一个引用成员对象的类,sizeof是4,跟只有一个指针成员对象的类是一样的,那么先大胆假设引用其实就是一个指针,看下面这个例子,分别定义一个指针和引用并初始化
void ReferencePointerTest() {
int i = 100;
int *pi = &i;
std::cout << "Pointer Value is " << *pi << std::endl;
int& ri = i;
std::cout << "Reference Value is " << ri << std::endl;
}
通过ctrl+F11查看反汇编代码,调用如下
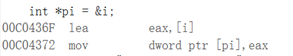

从反汇编的汇编代码来看,使用的命令完全一样,这样看来引用就是通过指针的方式来实现的
那么抛出第一个问题,既然引用等价于指针,为什么还要使用引用这个方式呢?
简单说,引用只是为了优化指针的试用,主要的区别在于:
指针地址可以修改,可以为空,而引用不行,一个未初始化的引用是不能使用的,避免了用户传递无效指针
通过sizeof的计算,指针只能得到指针本身的大小,而引用优化为得到指向对象本身的大小,这点可以推导编译器记录对象符号的时候,指针记录 指针自身地址,引用则记录引用对象自身地址
从引用的使用方式上,可以推导出T& == T* const,一个不可修改指向地址的指针,但指向内容是非const,依然可以修改内容
2. const引用
const引用是一种特殊的引用,从字面意思看const引用只是限制了引用对自身引用对象的修改权限,参考如下代码:
void ConstReferenceTest() { int i = 100; const int ci = 110; const int& rci0 = i; const int& rci1 = ci; const int& rci2 = 120; std::cout << "rci0 " << rci0 << " rci1 " << rci1 << " rci2 " << rci2; }
最重要的一点,const引用可以绑定一个常量值,而不一定是一个类型对象,这样作为参数的时候,const引用可以使用临时对象和常量值作为参数,而非const引用作为参数,只能使用一个引用对象作为参数,参考如下代码
void ReferenceArgTest(int& ri) {
std::cout << "Reference Argument is " << ri << std::endl;
}
void ConstReferenceArgTest(const int& cri) {
std::cout << "Const Reference Argument is " << cri << std::endl;
}
void Test() {
ReferenceArgTest(100); //error, 常量值不能作为引用对象使用
ConstReferenceArgTest(100); //correct, 常量可以作为const引用参数
}
结论:使用const引用可以包含函数返回临时对象,常量等非类型对象,这也就是为什么编译器默认给的复制构造函数参数要用const T&形式;这类对象一般称为右值
3. 什么是左值,右值
左值右值的概念基于赋值表达式,比如:a = b + 10, a就是一个左值,而b+10得到的结果就是一个右值。那么具体如何区分左右值呢?
简单说,可以通过&运算符获取地址的,就是左值;若否就是右值,一个简单的例子
int a = 10; ++a = 5; //correct, ++a的返回值是a对象自身,是一个左值可以使用 a++ = 5; //error, a++的返回值是一个将亡值是没有地址的,不能作为左值使用
右值又分为纯右值和将亡值,纯右值就是常量值,100, ‘a’, “abcd”, false这样的字面值都是纯右值;而将亡值则是指临时对象, a+10表达式,getvalue接口返回等结果都属于将亡值,当将亡值赋值给具体的左值之后,其自身就会自动析构掉资源
4. 右值引用
可以绑定右值的引用称为右值引用,传统的引用因为需要绑定一个具体的对象,所以称为左值引用。C++98和C++03只有左值引用的概念;从C++11开始,引入了右值引用的概念,为了区分于左值引用,使用&&符号来声明。比如int&& rr = 10;注意,右值引用只能绑定右值,左值引用也只能绑定左值,如下
int i = 100; int& r = 100; //error,左值引用只能绑定左值 int&& rr = i; //error,右值引用只能绑定右值
注意:右值引用与右值是两个概念,右值引用本身是可以取地址的,所以右值引用是一个左值,所以rr是一个可以取地址的左值对象
先看一个例子,看看右值引用到底解决了什么问题
假设有两个相同容量的水池,其中一个空的,其中一个已经注满了水,现在我们要把空池子注满水而另一个放空
class WaterPool { char* m_pWaterStream = nullptr; public: WaterPool() { std::cout << "Construct a empty waterpool" << std::endl; } WaterPool(char* pStream) : m_pWaterStream(pStream) { std::cout << "Constrcut a full waterpool" << std::endl; } ~WaterPool() { if (m_pWaterStream) { delete[] m_pWaterStream; std::cout << "Destruct a full waterpool" << std::endl; } else { std::cout << "Destruct a empty waterpool" << std::endl; } } WaterPool(WaterPool& other) { std::cout << "Construct a full waterpool by copy" << std::endl; m_pWaterStream = new char[strlen(other.m_pWaterStream) + 1]; memset(m_pWaterStream, 0, strlen(other.m_pWaterStream) + 1); strcpy_s(m_pWaterStream, strlen(other.m_pWaterStream)+1, other.m_pWaterStream); }
}
void draw_off_water() {
WaterPool w1(new char[100]);
WaterPool w2 = w1;
}
输出打印:
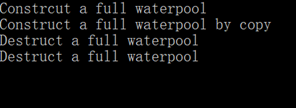
可以看到,传统的复制构造用了一种比较蠢的方式,先不管第一个满水池直接用水管注满第二个池子,然后放空第一个水池;既然已经决定要放空第一个水池的水,为何不直接考虑把第一个池子的水通过一个管道注入第二个水池呢,这样也节省了一整池子的水资源。因为第一个水池是准备要放水的,也就是说放完水之后这个水池不会再使用了,很符合前面提到的将亡值概念。从将亡值的概念知道,临时对象交给一个左值之后,就会析构掉资源,如果通过赋值则需要把临时对象的全部资源拷贝给左值对象,那么是不是可以直接不析构临时对象的资源而只交接资源所有权给左值对象呢?
如下图所示
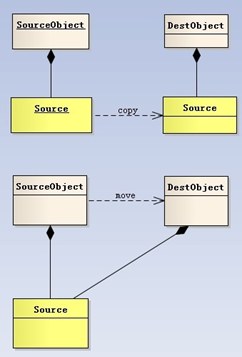
为了解决深拷贝带来不必要的资源和性能问题,C++11引入了一个新的概念叫move(移动),而右值引用则是为实现移动而出现的解决方案。在C++11中类的默认函数多出两个移动构造函数和移动赋值函数
先看右值引用的解决方案
WaterPool(WaterPool&& other) { std::cout << "Construct a full waterpool by move" << std::endl; m_pWaterStream= other.m_pWaterStream; other.m_pWaterStream = nullptr;
}
void draw_off_water() {
WaterPool w1(new char[100]);
WaterPool w2 = std::move(w1);
}
输出打印

本来的深拷贝赋值动作变成了浅拷贝的移动动作。从析构的打印可以看到,前一个水池直接把水倒入后一个水池,析构掉的是一个空水池。而代表水的这段字符串直接从w1交给了w2控制,而并非在堆上又分配回收一次
目前c++11的规则中,如果声明一个类什么都不写,但在使用中又使用了这些函数,编译器是会默认帮助生成以下函数的,包括
默认构造函数
析构函数
复制构造函数 (没有声明复制构造,且代码中调用了复制构造)
复制赋值函数
移动构造函数 (没有声明复制构造,没有声明析构,没有声明移动构造,且代码中使用了移动构造)
移动赋值函数
注意,虽然复制构造,复制赋值和析构没有必须的关联关系,不会因为自定义了复制构造,就无法靠编译器自动生成复制赋值,但这三者在资源创建和回收应该有管理依赖关系,如果其中一个自定义了,最好还是自定义其他两个
所以如果自己类中的资源需要特殊处理,最好是自己定义这些构造赋值函数,
一般来说,需要以下的自定义函数
class Base { public: Base(); // 默认构造函数 ~Base(); // 析构函数 Base(const Base & rhs); // 复制构造函数 Base & operator=(const Base & rhs); // 复制赋值函数 Base (Base && rhs); // 移动构造函数 Base & operator=( Base && rhs); // 移动赋值函数 };
从上面的声明可以比较清晰得看出,如果在赋值时给出一个左值则会调用复制赋值,如果给出一个右值则会调用移动赋值,而C++还有一个规则是如果没有定义移动构造且编译器也未达到自动生成移动构造的条件下而使用了右值引用作为构造参数,会自动调用复制构造来完成(因为复制构造的参数是const T&, 可以绑定给一个右值)
std::swap的具体实现,就是借用了右值引用的概念交换两个参数对象的资源

这里使用了一个接口叫做std::move, 简单讲就是将一个非右值强转换为右值,因为只有参数为右值才会触发这个类对应的移动构造和移动赋值,进行资源转移所有权的操作,
智能指针中的std::auto_tr在C++11中被弃用而开始使用std::unique_ptr,后者即是基于移动语义来实现的异常安全的独占资源指针

这里先不讲move的具体实现,先引申出另一个概念,完美转发
5. 完美转发
解析概念之前,先看一个例子
void Print(const BaseClass& b) { std::cout << "Print BaseClass by Left Reference" << std::endl; } void Print(BaseClass&& b) { std::cout << "Print BaseClass by Right Reference" << std::endl; } void PrePrint(BaseClass&& b) { Print(b); } void ForwardPrint(BaseClass&& b) { Print(std::forward<BaseClass>(b)); }
PrePrint函数传递的外部参数是一个右值引用,但是在内部直接使用变成了调用左值引用,是因为b作为右值引用对象,其本身是一个左值。但这种实现则违背了我们的初心,我们是期望调用右值引用参数的方法
再来看ForwardPrint,将参数做了一次转发转换为右值引用的值,则保证了传递给Print的参数是右值引用,std::forward这个转发机制则是用于解决这个问题,但是完美转发的作用主要还是作用于模板编程,看下面的问题
对于模板编程来说,T&&一定是右值引用吗?
看一个例子
template<class T> void TemplateReferenceCollapsing(T&& t) { Print(std::forward<T>(t)); } void ReferenceCollapsingTest() { BaseClass b; BaseClass &rb = b; TemplateReferenceCollapsing(b); TemplateReferenceCollapsing(rb); TemplateReferenceCollapsing(Create()); }
参数填入左值,右值均可通过编译,说明传入不一样的实参,T&&会变成不一样的类型,这种引用既不是左值引用也不是右值引用,但又既可以作为左值引用又可以作为右值引用,称为万能引用
这里提出一个新的概念叫引用折叠(reference collapsing),折叠的规则
|
传入实参 |
推导的T |
折叠后实参型 |
|
A |
A& |
A& + && = A& |
|
A& |
A& |
A& + && = A& |
|
A&& |
A |
A + && = A&& |
(类型推导不再这里介绍,折叠规则一个简单的记忆就是只有调用传入右值引用,T&&才会实例为真正的右值引用参数,否则都是左值引用)
这里解决了一个问题,如果我们传递的参数既可能是左值又可能是右值,如果以具体类型重载接口,那么一个参数就需要重载两个接口,N个参数就需要重载2N个接口,这显然工程巨大且不现实。有了引用折叠自动推导参数后,只需要带上一个完美转发,一个接口就处理了全部的情况,看一个实际应用的例子
template<class Function, class... Args> inline auto FuncWrapper(Function && f, Args && ... args) -> decltype(f(std::forward<Args>(args)...)) { return f(std::forward<Args>(args)...); }
这是一个万能的函数包装器,无论带不带返回值,带不带参数,带不定数量的参数均可使用这个包装器
理解了引用折叠,std::move的实现就比较好理解了,看实现源码

std::remove_reference的作用是去除模板类型的引用属性
std::remove_reference<T&>::type = T
std::remove_reference<T&&>::type = T
std::remove_reference<T>::type = T
所以无论模板参数T是哪种情况,move都可以强制将参数转换为T&&得到一个右值引用
总结
- 左值引用的实现原理是T* const,所以引用一旦初始化就不能更改对象但可以修改内容
- 右值引用不是RVO(Return Value Optimization), 后者比右值引用更厉害,是直接编译器优化了代码内部执行的重复构造和临时对象复制。右值引用并不能减少构造函数的调用,但是它可以选择移动构造避免堆内存反复的分配回收,当然,移动构造的移动实现可能需要你自己来实现(c++内部的数据结构大部分已经做了默认处理,比如stl容器)
- 完美转发是为了解决右值引用参数在函数内部的二次调用,右值引用对象不是右值而是左值
- 如果我们期望用到右值引用相关的效果(比如移动构造,右值引用参数重载函数),请用std::move把左值强制转换成右值(但是函数返回临时对象不建议加,因为已经被RVO优化过了)