论文信息
论文标题:Rethinking the Setting of Semi-supervised Learning on Graphs
论文作者:Ziang Li, Ming Ding, Weikai Li, Zihan Wang, Ziyu Zeng, Yukuo Cen, Jie Tang
论文来源:2022, arXiv
论文地址:download
论文代码:download
1 Introduction
本文主要研究半监督GNNs 模型存在的超调现象(over-tuning phenomenon),并提出了一种公平的模型对比架构。
2 The Risk of Over-tuning of Semi-supervised Learning on Graphs
2.1 Semi-Supervised Learning on Graphs
常用的三个数据集:

2.2 An Analysis of Over-tuning in Current GNNs
超调现象(over-tuning phenomenon)普遍存在GNNs中,即 GNN 模型的超参数过分拟合验证集。
本文测试了5种代表性的 GNNs 框架(GCN, GAT, APPNP, GDC-GCN, ADC)在 Cora 数据集上不同验证集尺寸上的准确率对比。本文采用网格搜索为每个模型选择最优的超参数。将验证集的大小从 100 到 500。对于每个验证集,在使用最佳搜索的超参数训练模型后,报告测试集上的结果。结果如 Figure1 所示。
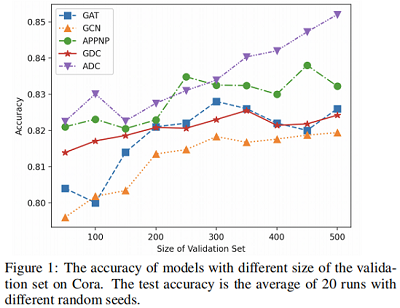
Figure 1 显示,GNN模型使用更大的验证集的性能通常更好。由于验证集只能通过超参数来影响模型,因此我们可以得出结论,该模型可以利用超参数从验证标签中获益。如果我们将验证集的大小从 100 增加到 500,准确率提高高达 1%∼3% ,这足以表明过度调优已经存在。
2.3 ValidUtil: Exploring the Limits of Over-tuning
通常不能将验证集加入到训练集中,这是被认为是一种数据泄露。本文提出的 ValidUtil 如:

结果发现:只有当 $\hat{y}_{i}=y_{i}$ 时,模型才能达到最好的结果。Figure 2 表明了 hyper-parameters 对实验的影响:
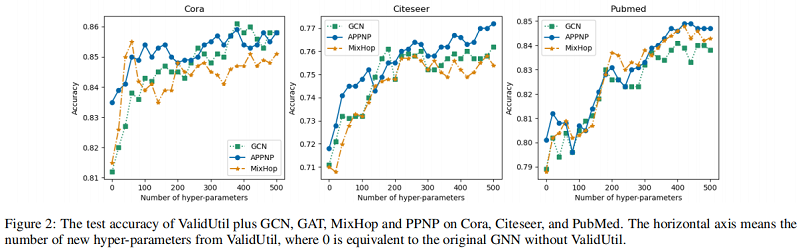
我们发现,即使从ValidUtil中只有20个∼60个超参数,也可以给某些模型带来性能上的飞跃。当我们为验证集中的所有500个节点添加超参数时,PPNP可以比 Table 2 中的SOTA 方法。
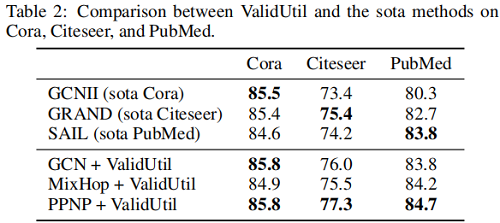
备注:虽然ValidUtil纯粹通过使用验证标签来工作,但它在当前设置下是完全有效的。如果我们将GNN+ValidUtil视为一个黑盒模型,那么训练过程是相当正常的。ValidUtil实际上使用标签的效率很低,因为每个超参数只能学习一个节点的信息——但这足以验证我们的假设。当前设置无法阻止验证标签在超参数调优期间“泄漏”。我们认为有一些更有效的方法来定义有影响的超参数。这些超参数可能与特征或模型结构纠缠在一起,它们可以从多个验证标签中获取信息。根据 Figure 1,这种有影响的超参数可能已经存在于一些模型中,不易检测到。因此,迫切需要构建一个新的图上的半监督学习基准,以避免过度调优和公平、稳健地比较GNN模型。
3 IGB: An Independent and Identically Distributed Graph Benchmark
3.1 Overview
新基准测试的两个目标:避免过度调优和更健壮。
为避免过度调优,本文将节点分为标记节点和未标记节点。可以采用任何方式来学习标记数据集的最佳模型,并评估未标记集(测试集)上的性能。若需要搜索超参数,可以将一部分标记数据集当成验证集。由于验证标签已经暴露出来,因此消除了过度调优的问题。这种设置更接近真实场景,能够在具有不同超参数的模型之间进行公平比较。为了轻松地将 GNN 迁移到这个新的设置中,我们将在第3.2节中引入一个简单而强大的方法来创建验证集。
本文期望在不同的随机种子下,模型的性能是稳定的。机器学习中报告性能的常用方法是:重复测试和报告平均性能。所以本文期望在多个 i.i.d 图上测试模型的性能,这多个 i.i.d 图 是采样得到的。
- 1. Divide the labeled set into training and validation sets.
- 2. Find the best hyper-parameters using grid search on the training and validation sets from the first step.
- 3. Train the model with the best hyper-parameters on the full labeled nodes.
- 4. Test the performance of the model from the third step on the unlabeled (test) sets.
- 5. Repeat the above steps on each graph in a dataset and report the average accuracy
前两步旨在找到GNN模型的最佳超参数。我们认为该方法适用于许多GNN模型获得满意的超参数。如果有其他合理的方法来确定带标记集的最佳超参数,他们也将被鼓励替换这个管道中的前两个步骤。通过这种方式,可以通过在第三步直接公开验证集中的所有标签信息来避免过度调优。
3.3 Datasets
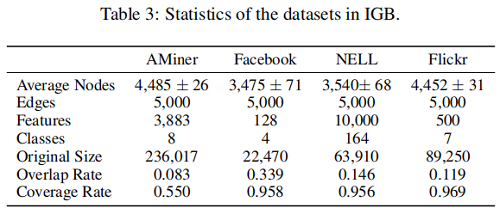
IGB由四个数据集组成:Aminer,Facebook,Nell,Flickr。每个数据集包含100个无向连通图,根据第3.4节中的随机游动方法从原始的大图中采样。我们还报告了一对采样图的平均节点重叠率,即公共节点与节点总大小的比率。覆盖率定义为100个采样图与原始大图的并集之比。首选低重叠率和高覆盖率。数据集的统计数据见表3。
3.4 Sampling Algorithm
使子图的节点标签分布与原始图相似的最简单的方法是顶点抽样。然而,它并不符合我们的期望,因为它生成了不连接的子图。为获得接近 i.i.d. 子图的基准,我们必须仔细设计抽样策略和原则。具体来说,我们期望抽样策略具有以下特性:
- 1. The sampled subgraph is a connected graph.
- 2. The distribution of the subgraph’s node labels is close to that of the original graph.
- 3. The distribution of the subgraph’s edge categories (edge category is defined by the combination of its two endpoints’ labels) is close to that of the original graph.
首先,随机游走很好的满足第一点,我们从节点 $u=n_0$开始采样,通过转换的可能性可以选择以下节点:
$P_{u, v}=\left\{\begin{array}{ll}\frac{1}{d_{u}}, & \text { if }(u, v) \in E \\0, & \text { otherwise }\end{array}\right.$
其中,$P_{u, v}$ 是从 $u$ 到 $v$ 的转移概率,$d_{u}$ 代表着节点 $u$ 的度。
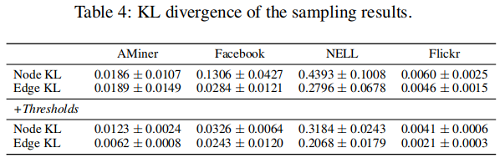
我们拒绝采用类似抽样的方法,以保证第二个和第三个性质。在这里,我们引入了 KL散度 作为一个度量来度量两个不同分布之间的差异。为了得到节点标签分布(“Node KL”)和边缘类别分布(“Edge KL”)KL散度相对较低的子图,我们设置了一个预定义的阈值来决定是否接受采样子图。添加阈值前后的结果比较如 Table 4 所示。
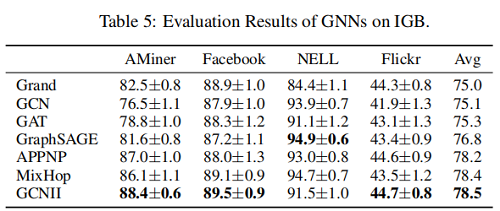
3.5 Benchmarking Results
在这四个数据集上的结果:
3.6 The Stability of IGB
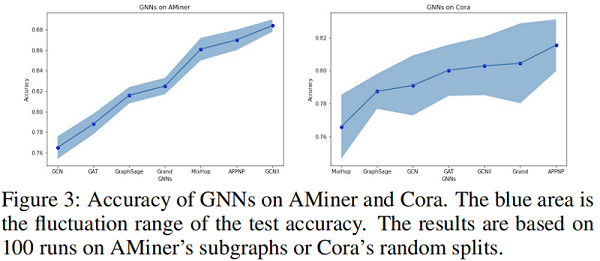
本文用两种方法验证了 IGB 的稳定性。首先,验证它在不同的图上评估模型时的稳定性,因为每个 IGB 数据集包含100个近 i.i.d. 图。具体来说,我们比较了100个 AMiner子图 和100 个Cora随机数据分割上的精度方差。Figure 3 结果表明,即使每个 AMiner 图都使用了随机数据分割,对 IGB 的评估也比 Cora 风格更稳定。
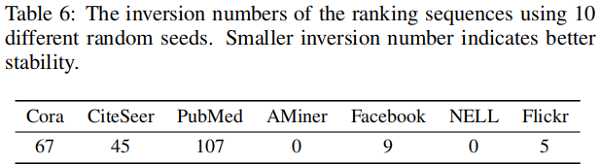
其次,关注IGB在评估具有不同随机种子的模型时的稳定性。在一个稳定的基准测试中,不同模型的排名在改变随机种子时不应该很容易地改变。为了验证这一点,我们使用排名的 “inversion number” 作为度量。
4 Conclusion
本文重新讨论了图上的半监督设置,并阐述了过度调优的问题,且通过 VallidUtil 验证了他的意义。本文还提出了一个新的基准 IGB,一种更加稳定的评估管道。还提出一种基于 RW 采样算法来提高评价的稳定性,本文希望通过IGB 能造福社会。
修改历史
2022-07-07 创建文章