创建表:
CREATE TABLE 语句用于在任何给定的数据库创建一个新表。命名表、定义列、定义每一列的数据类型

查看表:
详细查看表:

重命名表:

删除表:

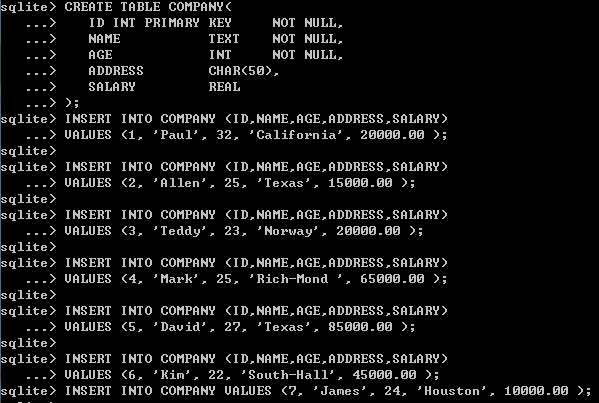
创建表并添加7条记录(第七条记录用了第二种方法添加):
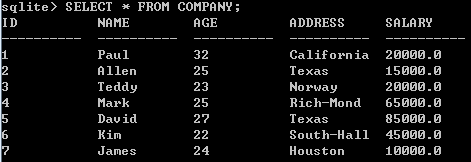
查询表

显示字段名

以表格方式显示

显示结果
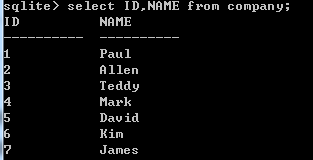
选择字段查询
设置列的显示宽度
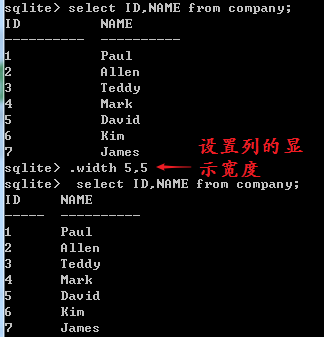
恢复默认宽度
.width on
修改表中已有的记录
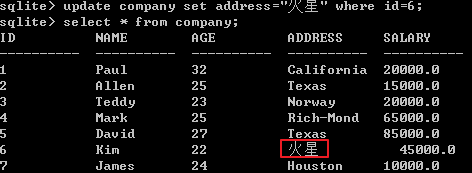
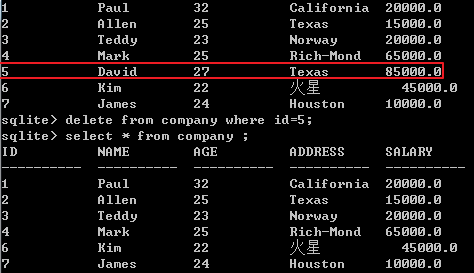
删除表中已有的记录
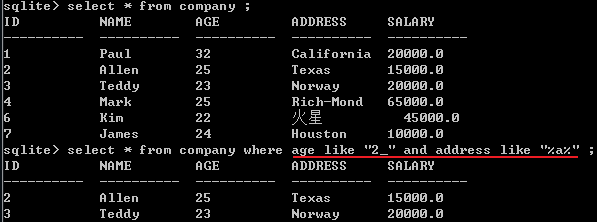
LIKE 运算符是用来匹配通配符指定模式的文本值
百分号(%)代表零个、一个或多个数字或字符。下划线(_)代表一个单一的数字或字符。可以使用 AND 或 OR 运算符来结合 N 个数量的条件
例子:查找年龄为20-29岁且地址带a字符的记录
GLOBLE 运算符是用来匹配通配符指定模式的文本值
星号(*)代表零个、一个或多个数字或字符。问号(?)代表一个单一的数字或字符。这些符号可以被组合使用。可以使用 AND 或 OR 运算符来结合 N 个数量的条件
与 LIKE 运算符不同的是,GLOB 是大小写敏感的
显示第5至第7条记录
limit 2 -- 只显示两条记录
offset 4 -- 忽略前面4条记录,从第5条开始
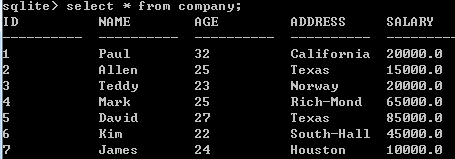

排序显示
asc 由小到大(默认)
desc 由大到小
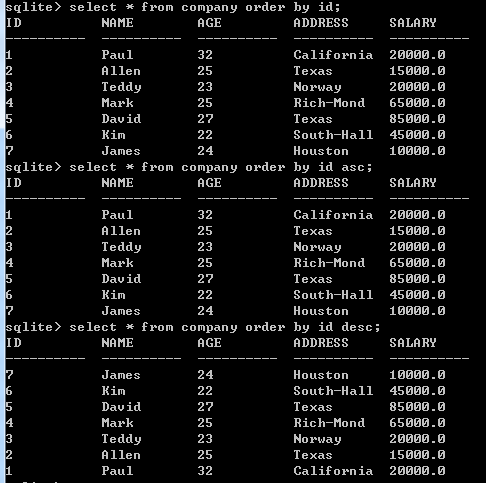
分组计算
GROUP BY 子句的基本语法。GROUP BY 子句必须放在 WHERE 子句中的条件之后,必须放在 ORDER BY 子句之前。
求发给每个员工的总薪水:

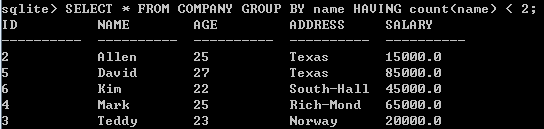
指定条件过滤,字段不重复的记录
HAVING 子句允许指定条件来过滤将出现在最终结果中的分组结果。
WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。
在一个查询中,HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前。
去重显示
DISTINCT 关键字与 SELECT 语句一起使用,来消除所有重复的记录,并只获取唯一一次记录。
