分组集就是分组(GROUP BY子句)使用的一组属性,在传统的SQL中,一个聚合查询只能定义一个分组集:
假设现在不想生成4个单独的结果集,而是希望生成一个统一的结果集,其中包含所有4个分组集的聚合 数据,下面是经过调整后的代码:
虽然设法得到了期望的结果,但这种解决方案存在两个主要 问题:代码长度和性能。
1.GROUPING SETS从属子句
借助该从属子句,就可以在同一查询中定义多个分组集。只要简单地在GROUPING SETS从属子句的圆括号内列出想要定义的各分组集,分组集之间用逗号分隔开。以下是示例代码:
2.CUBE从属子句
在CUBE从属子句的圆括号内,只须要列出由逗号分隔开的元素成员,就可以得到基于输入成员而定义的所有可能的分组集。例如CUBE(a,b)与GROUPING SETS((a,b),(a),(b),())等价。以下是示例代码:
SELECT empid,custid,SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid,custid);
GROUP BY子句的CUBE从属子句是SQL Server2008引入的,SQL Server的早期版本支持一种非标准的CUBE选项,以下是示例代码:
SELECT empid,custid,SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid,custid
WITH CUBE;
3.ROLLUP从属子句
GROUP BY子句的ROLLUP从属子句也提供了一种定义多个分组集的简略方法。不过ROLLUP认为输入成员之间存在一定的层次关系,从而生成让这种层次关系有意义的所有分组集。换句话说,CUBE(a,b,c)生成由3个输入成员得到的所有8个可能的分组集,而ROLLUP认为这3个输入成员 存在a>b>c的层次关系,所以只生成4个分组集(a,b,c),(a,b),(a),();在早期的SQL Server版本中,应用的是WITH ROLLUP选项。
4.GROUPING 和GROUPING_ID函数
如果一个查询定义了多个分组集,可能还想能够把结果行和分组集关联起来,也就是说为每个结果行标识出它是和哪个分组集关联的。只要所有分组元素都定义为NOT NULL,实现这个要求并不难。
因为Orders表的empid和custid定义为NOT NULL,这些列中的NULL值只代表一个占位符,表示该列并不属于当前的分组集。所以,所有empid和custid均不为NULL的行都与分组集(empid,custid)相关联;所有empid不为NULL,custid为NULL的行都与分组集(empid)有关联,以此类推。
但是,如果表中的分组列定义为允许取NULL值,这时就无法区分结果庥中的NULL中来自原始数据还是占位符。如果想以确定性的方式来判断分组集的关联,一种方法是使用GROUPING函数,这个函数接受一个列名,如果该列是当前分组集的成员,就返回0否则返回1,以下是示例代码: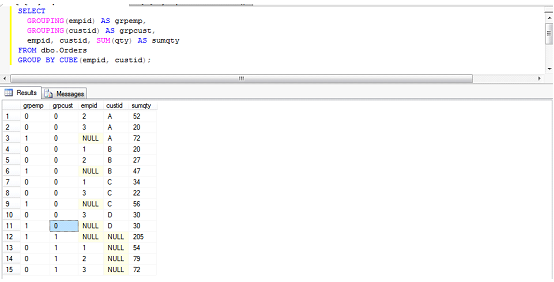
SQL Server 2008引入了一个名为GROUPING_ID的新函数,可以把任何分组集中的所有元素作为函数的输入,例如GROUPING_ID(a,b,c),分组集(a,b,c)可以用整数0
(0*4 + 0*2 + 0*1)表示,因为0代表属于,而分组集(a,c)则可以用整数2(0*4 + 1*2 + 0*1)表示。