第一次个人编程作业
博客作业求高分 嘻嘻!!
1.GITHUB链接
2.PSP表格估计时间
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |
|---|---|---|
| Planning | 计划 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 60 |
| Development | 开发 | 1170 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 |
| · Design Spec | · 生成设计文档 | 30 |
| · Design Review | · 设计复审 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 |
| · Design | · 具体设计 | 100 |
| · Coding | · 具体编码 | 420 |
| · Code Review | · 代码复审 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 |
| Reporting | 报告 | 60 |
| · Test Repor | · 测试报告 | 60 |
| · Size Measurement | · 计算工作量 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 |
| 1375 | · 合计 | 1230 |
3.计算模块接口的设计与实现过程
3.1接口思路描述
(1)首先主程序分析字符串分离出level和字符串数据,然后调用我自己写的parseAddr尝试分离出五级地址
(2)在parseAddr库中,根据之前的level等级,从而判断是否要在分离五级地址的时候,补全缺失的地址
(3)分离出五级地址后,根据level等级,判断是否需要继续将详细地址分离成 路名+门牌号+详细地址
(4)如果需要补全七级地址则需要调用高德地图的API,先通过模糊地址解析处经纬度,然后利用经纬度逆地址解析.根据逆地址解析得到的详细地址,从而分离出门牌号和路名
ParseAddr 接口代码:
def parse(self,addr):
provinces,cities,countries,towns=self.provinces,self.cities,self.countries,self.towns
#找出省
#print(provinces,cities,countries,towns)
dic={
'province':'',
'city':'',
'country':'',
'town':'',
'detail':'',
}
for i in abbrProvinces:
if i in addr and ( addr.find(i)==0):#保证第一个省正确
dic['province']=allProvinces[abbrProvinces.index(i)]
if dic['province'] in ['北京','天津','上海','重庆']:
dic['city']=dic['province']+'市'
break
if dic['province']=='':
for i in cities:
if (cities[i]['city'] or cities[i]['city'][:-1]) in addr:
dic['provnice']=provinces[cities[i]['city_id'][:2]+10*'0']
break
if dic['province']=='':
for i in countries:
if countries[i]['country'] in addr:
dic['province']=provinces[countries[i]['country_id'][:2]+10*'0']
break
if dic['province'] == '':
for i in towns:
if towns[i]['town'] in addr:
dic['province']=provinces[towns[i]['town_id'][:2]+10*'0']
#print(dic['province'])
province_id = provinces[dic['province']]
if dic['province']:
if (dic['province'][-1] == '省') or (dic['province'] in ['北京', '天津', '重庆', '上海']):
if dic['province'] in ['北京', '天津', '重庆', '上海']:
# match=re.match(dic['province'],addr)
dic['city']=dic['province']+'市'
span = addr.find(dic['province']) + len(dic['province'])
if addr[span] == '市':
addr = addr.replace(dic['city'], '', 1)
else:
addr = addr.replace(dic['province'], '', 1)
else:
span = addr.find(abbrProvinces[allProvinces.index(dic['province'])]) + len(
abbrProvinces[allProvinces.index(dic['province'])])
# print(match.span())
if addr[span] == '省':
addr = addr.replace(dic['province'], '', 1)
else: # 后面没有省
addr = addr.replace(dic['province'][:-1], '', 1)
else:
addr = addr.replace(dic['province'], '', 1)
if dic['city'] == '':
for i in cities:
if i[:2]==province_id[:2]:#保证分词正确
if (cities[i]['city'] in addr) and addr.find(cities[i]['city']) ==0:
dic['city']=cities[i]['city']
if ((cities[i]['city'][:-1]) in addr ) and ( addr.find(cities[i]['city'][:-1])==0):
dic['city']=cities[i]['city']
#找到县
if dic['city']:
if (not (dic['province'] in ['北京', '天津', '重庆', '上海'])) and (dic['city'][-1] == '市'):
span = addr.find(dic['city'][:-1]) + len(dic['city'][:-1])
if addr[span] == '市':
addr = addr.replace(dic['city'], '', 1)
else:
addr = addr.replace(dic['city'][:-1], '', 1)
else:
addr = addr.replace(dic['city'], '', 1)
for i in countries:
#print(countries[i])
if (countries[i]['country'] in addr) and (province_id[:2]==countries[i]['country_id'][:2]) :
if addr.find(countries[i]['country'])==0:
dic['country'] = countries[i]['country']
addr=addr.replace(dic['country'],'',1)
if dic['city']=='' :
if i[:4]+8*'0' in cities:
dic['city']=cities[i[:4]+8*'0']['city']
break
if dic['city']:
if (not (dic['province'] in ['北京', '天津', '重庆', '上海'])) and (dic['city'][-1] == '市'):
span = addr.find(dic['city'][:-1]) + len(dic['city'][:-1])
if addr[span] == '市':
addr = addr.replace(dic['city'], '', 1)
else:
addr = addr.replace(dic['city'][:-1], '', 1)
else:
addr = addr.replace(dic['city'], '', 1)
for i in towns:
#print(towns[i])
if (re.findall(towns[i]['town'],addr) ) and (province_id[:2]==towns[i]['town_id'][:2]):
if addr.find(towns[i]['town'])==0:
#print(towns[i]['town'])
dic['town']=towns[i]['town']
addr=addr.replace(dic['town'],'',1)
if dic['city']=='':
if i[:4]+8*'0' in cities:
dic['city']=cities[i[:4]+8*'0']['city']
if dic['country']=='':
if i[:7]+5*'0' in countries:
dic['country'] = countries[i[:7] + 5 * '0']['country']
break
if dic['city']:
if (not (dic['province'] in ['北京', '天津', '重庆', '上海'])) and (dic['city'][-1] == '市'):
span = addr.find(dic['city'][:-1]) + len(dic['city'][:-1])
if addr[span] == '市':
addr = addr.replace(dic['city'], '', 1)
else:
addr = addr.replace(dic['city'][:-1], '', 1)
else:
addr = addr.replace(dic['city'], '', 1)
# addr = addr.replace(dic['town'], '', 1)
# addr = addr.replace(dic['country'], '', 1)
dic['detail'] = addr
#print(dic)
return dic
3.2接口流程图

3.3 实现过程和算法说明
(1)parseAddr库中有一个Load()类,初始化类后,将会加载4个xlsx文件,分别存入四个字典:省,市,县,乡.
Load()库下有两个函数,一个是补全函数,一个是剔除函数.补全函数用来补全五级地址,剔除函数用来剔除原本不存在的地址.
性能优点1:空间换时间 ;在构造省市县乡四级数据结构的时候,为了减少循环,提升查找效率。我是用了双向字典。将键-值存在字典后,并将二者调换位置,再次存下。
性能优点2:快速查询;在爬取城乡区域信息时,发现城乡区域代码的一种继承关系。只需要取前两位数字得到省级,前四位得到市级...等等
(2)GDAPI,利用在高德地图平台上申请的key,调用API,使用地址/逆地址解析接口,从而拿到七级地址.
(3)在主文件中对返回的五级地址或七级地址进行处理,得到正确的答案.
4.计算模块接口部分的性能改进
4.1接口结构调整
将部分功能相似的函数进行了整合,形成一个函数,通过对参数的控制,从而产生不同结果.
将GDAPI和parseAddr模块整合,打造出分析地址出神入化的一个python库,最近准备开源它.
4.2接口性能改进
将一些暴力for循环的模块,重写成一些数据结构,如双向字典,快速hash出我想要的结果.
引用一些其他的库,替换自己字符串模拟,提高自己的数据处理速度.

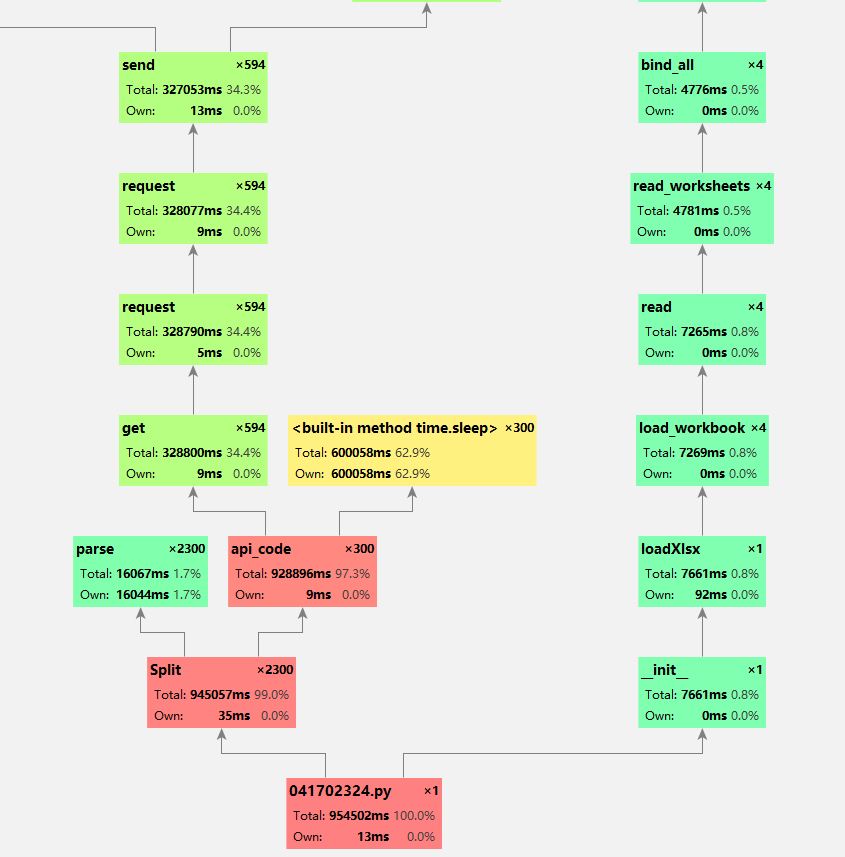
在性能分析工具Profile下,有这样的显示,的对我自己写函数api_code调用非常频繁.(因为我平凡的调用了高德API)
(1)在数据加载上的时间非常少.
(2)大量时间花费在了调用系统函数上
(3)对Split()函数压力太大,没有合理的分配函数的功能
5.计算模块部分单元测试展示
5.1 数据构造思路
根据数据制作者的思路,首先在国家统计局上爬取31个省市县乡村的行政信息,然后调用菜鸟物流的API,进行模糊搜索,得到一组数据大约1000条.这样构造的数据将会非常近似原生数据
5.2 单元测试覆盖率截图
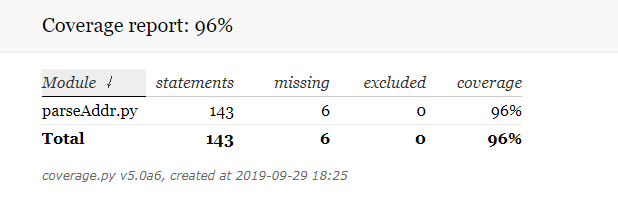
(1) parseAddr
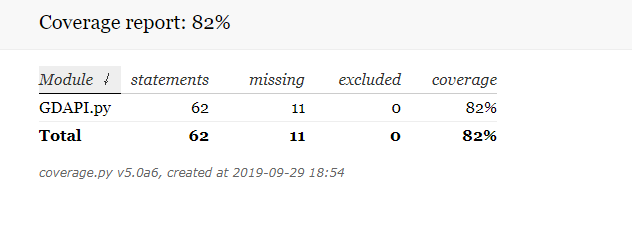
(2)GDAPI
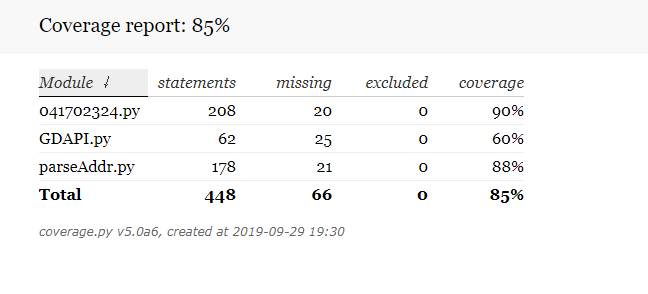
(3)整体测评
6.计算模块部分异常处理说明
样例测试:
1!晏孔,重庆巫山13097181946县大昌镇洋溪村便民超市.
1!荆麻,13282875332天津市北淮淀镇乐善庄村乐善庄小学.
1!诸葛宁盛,河南省15613629652焦作市山阳区定和街道塔南路287号新兴日化.
1!冯昔唉,安徽省合肥市庐江县郭河镇G3京台高18835354291速合肥市庐江县广寒桥街道.
1!百里屏闷,广西壮族自治区桂林市灵川县潭13315249688下镇004乡道灵川县潭下镇大义村民委员会.
1!徐扼负,天津市河北区月牙河街道大江里58号楼13289199578.
1!娄缠壮,山东省烟台莱山14732355817区莱山街道南陈家疃小区10栋.
1!曹持,江苏泰州13066409994市海陵区迎宾路88号春兰商务酒店.
1!赫连谴,北京市桥梓镇214县道中共沙峪口村支13827008064部委员会.
1!督坠,浙江淳安县中洲镇杨畈线畈头村18682392149村邮站.
1!桓猿攀,13898044414辽宁省营口市盖州市西海街道305国道盖州市西海农场.
1!通描哗,山西省临汾市安泽县冀氏镇北孔滩村13228042359村委会.
1!卓斧,贵州省贵阳清镇市红枫街164号青龙街道办事处13949510110.
(1)异常处理1:
在程序运行中很显然会出现数据结构错误如:字典键值缺失——KeyError。
解决方法:try ... except ... 处理异常并构造强力数据,保证代码全被覆盖到。
(2)异常处理2:
当数据可能是极端数据(边界数据)时,会导致程序无法承受的错误,甚至无法继续运行下去。
例如:index out of range。
解决方案:构造边界数据,并使用try ... except ...处理异常
(3)异常处理3:
当网络出现波动时,API调用出现问题。
解决方法:这时应该考虑sleep主线程,并及时保护现场,将数据写入指定文本。
7.PSP表格实际时间
| PSP2.1 | Personal Software Process Stages | 实际耗时(分钟) |
|---|---|---|
| Planning | 计划 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 40 |
| Development | 开发 | 1335 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 |
| · Design Spec | · 生成设计文档 | 20 |
| · Design Review | · 设计复审 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 70 |
| · Design | · 具体设计 | 80 |
| · Coding | · 具体编码 | 400 |
| · Code Review | · 代码复审 | 90 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 |
| Reporting | 报告 | 80 |
| · Test Repor | · 测试报告 | 75 |
| · Size Measurement | · 计算工作量 | 40 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 |
| · 合计 | 1375 |