回顾上文
作为单体程序,依赖的第三方服务虽不多,但是2C的程序还是有不少内容可讲; 作为一个常规互联网系统,无外乎就是接受请求、处理请求,输出响应。
由于业务渐渐增长,单机多核的共享内存模式带来的问题很多,编程也困难,随着多核时代和分布式系统的到来,共享模型已经不太适合并发编程,因此Actor模型又重新受到了人们的重视。

-----调试多线程都懂------
* 传统的编程模型通常使用回调和同步对象(如锁)来协调任务和访问共享数据, 从宏观看传统模型: 任务是一步步紧接着完成的,资源是需要抢占的。
* Actor模式是一种并发模型,与另一种模型共享内存完全相反,Actor模型share nothing。所有的线程(或进程)通过消息传递的方式进行合作,这些线程(或进程)称为Actor, 预先定义了任务的流水线后,不关注数据什么时候流到这个任务 ,专注完成工序任务。
.Net TPL Dataflow组件帮助我们快速实现Actor模型。
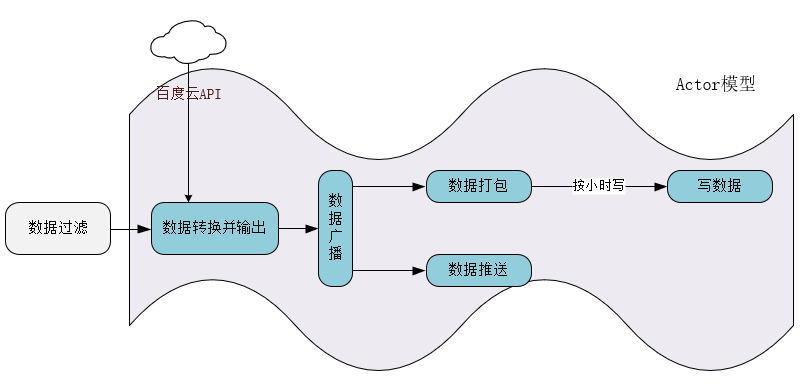
TPL Dataflow是微软前几年给出的数据处理库, 内置常见的处理块,可将这些块组装成一个处理管道,"块"对应处理管道中的"阶段", 可类比AspNetCore 中Middleware 和pipeline.。
-
TPL Dataflow库为消息传递和并行化CPU密集型和I / O密集型应用程序提供了编程基础,这些应用程序具有高吞吐量和低延迟。它还可以让您明确控制数据的缓冲方式并在系统中移动。
- 为了更好地理解数据流编程模型,请考虑从磁盘异步加载图像并创建这些图像的应用程序。
-
传统的编程模型通常使用回调和同步对象(如锁)来协调任务和访问共享数据,
-
通过使用数据流编程模型,您可以创建在从磁盘读取图像时处理图像的数据流对象。在数据流模型下,您可以声明数据在可用时的处理方式以及数据之间的依赖关系。 由于运行时管理数据之间的依赖关系,因此通常可以避免同步访问共享数据的要求。此外,由于运行时调度基于数据的异步到达而工作,因此数据流可以通过有效地管理底层线程来提高响应性和吞吐量。
-
- 需要注意的是:TPL Dataflow 非分布式数据流,消息在进程内传递, 使用nuget引用 System.Threading.Tasks.Dataflow 包。
TPL Dataflow 核心概念
Buffer & Block
TPL Dataflow 内置的Block覆盖了常见的应用场景,当然如果内置块不能满足你的要求,你也可以自定“块”。
Block可以划分为下面3类:
- Buffering Only 【Buffer不是缓存Cache的概念, 而是一个缓冲区的概念】
-
Execution
-
Grouping
使用以上块混搭处理管道, 大多数的块都会执行一个操作,有些时候需要将消息分发到不同Block,这时可使用特殊类型的缓冲块给管道“”分叉”。
Execution Block
-
输入、输出消息的缓冲区(一般称为Input,Output队列)
-
在消息上执行动作的委托

消息在输入和输出时能够被缓冲:当Func委托的运行速度比输入的消息速度慢时,后续消息将在到达时进行缓冲;当下一个块的输入缓冲区中没有容量时,将在输出时缓冲。
每个块我们可以配置:
-
缓冲区的总容量, 默认无上限
-
执行操作委托的并发度, 默认情况下块按照顺序处理消息,一次一个。
我们将块链接在一起形成一个处理管道,生产者将消息推向管道。
TPL Dataflow有一个基于pull的机制(使用Receive和TryReceive方法),但我们将在管道中使用块连接和推送机制。
-
TransformBlock(Execution category)-- 由输入输出缓冲区和一个Func<TInput, TOutput>委托组成,消费的每个消息,都会输出另外一个,你可以使用这个Block去执行输入消息的转换,或者转发输出的消息到另外一个Block。
-
TransformManyBlock (Execution category) -- 由输入输出缓冲区和一个Func<TInput, IEnumerable<TOutput>>委托组成, 它为输入的每个消息输出一个 IEnumerable<TOutput>
-
BroadcastBlock (Buffering category)-- 由只容纳1个消息的缓冲区和Func<T, T>委托组成。缓冲区被每个新传入的消息所覆盖,委托仅仅为了让你控制怎样克隆这个消息,不做消息转换。
该块可以链接到多个块(管道的分叉),虽然它一次只缓冲一条消息,但它一定会在该消息被覆盖之前将该消息转发到链接块(链接块还有缓冲区)。
-
ActionBlock (Execution category)-- 由缓冲区和Action<T>委托组成,他们一般是管道的结尾,他们不再给其他块转发消息,他们只会处理输入的消息。
-
BatchBlock (Grouping category)-- 告诉它你想要的每个批处理的大小,它将累积消息,直到它达到那个大小,然后将它作为一组消息转发到下一个块。
还有一下其他的Block类型:BufferBlock、WriteOnceBlock、JoinBlock、BatchedJoinBlock,我们暂时不会深入。
Pipeline Chain React
当输入缓冲区达到上限容量,为其供货的上游块的输出缓冲区将开始填充,当输出缓冲区已满时,该块必须暂停处理,直到缓冲区有空间,这意味着一个Block的处理瓶颈可能导致所有前面的块的缓冲区被填满。
但是不是所有的块变满时,都会暂停,BroadcastBlock 有允许1个消息的缓冲区,每个消息都会被覆盖, 因此如果这个广播块不能将消息转发到下游,则在下个消息到达的时候消息将丢失,这在某种意义上是一种限流(比较生硬).
编程实践
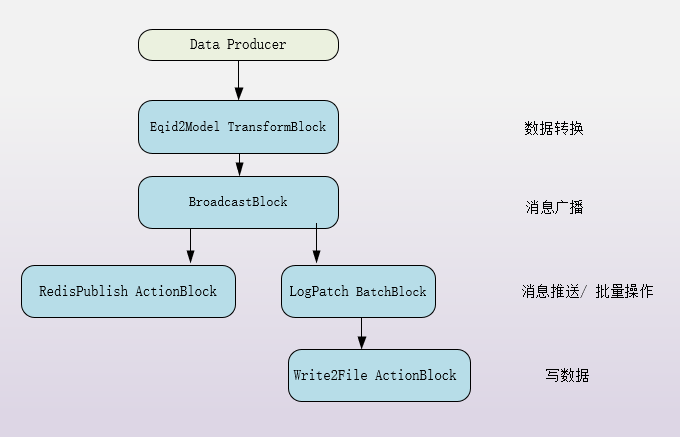
生产者投递消息
可使用Post或者SendAsync 方法向首块投递消息
-
Post方法即时返回true/false, True意味着消息被block接收(缓冲区有空余), false意味着拒绝了消息(缓冲区已满或者Block已经出错了)。
-
SendAsync方法返回一个Task<bool>, 将会以异步的方式阻塞直到块接收、拒绝、块出错。
定义流水线
按照上图工作流定义 流水线
public EqidPairHandler(IHttpClientFactory httpClientFactory, RedisDatabase redisCache, IConfiguration con, LogConfig logConfig, ILoggerFactory loggerFactory) { _httpClient = httpClientFactory.CreateClient("bce-request"); _redisDB0 = redisCache[0]; _redisDB = redisCache; _logger = loggerFactory.CreateLogger(nameof(EqidPairHandler)); var option = new DataflowLinkOptions { PropagateCompletion = true }; publisher = _redisDB.RedisConnection.GetSubscriber(); _eqid2ModelTransformBlock = new TransformBlock<EqidPair, EqidModel> ( // redis piublih 没有做在TransformBlock fun里面, 因为publih失败可能影响后续的block传递 eqidPair => EqidResolverAsync(eqidPair), new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism = con.GetValue<int>("MaxDegreeOfParallelism") } ); // https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/walkthrough-creating-a-dataflow-pipeline _logBatchBlock = new LogBatchBlock<EqidModel>(logConfig, loggerFactory); _logPublishBlock = new ActionBlock<EqidModel>(x => PublishAsync(x) ); _broadcastBlock = new BroadcastBlock<EqidModel>(x => x); // 由只容纳一个消息的缓存区和拷贝函数组成
_broadcastBlock.LinkTo(_logBatchBlock.InputBlock, option);
_broadcastBlock.LinkTo(_logPublishBlock, option);
_eqid2ModelTransformBlock.LinkTo(_broadcastBlock, option);
}


public class LogBatchBlock<T> : ILogDestination<T> where T : IModelBase { private readonly string _dirPath; private readonly Timer _triggerBatchTimer; private readonly Timer _openFileTimer; private DateTime? _nextCheckpoint; private TextWriter _currentWriter; private readonly LogHead _logHead; private readonly object _syncRoot = new object(); private readonly ILogger _logger; private readonly BatchBlock<T> _packer; private readonly ActionBlock<T[]> batchWriterBlock; private readonly TimeSpan _logFileIntervalTimeSpan; /// <summary> /// Generate request log file. /// </summary> public LogBatchBlock(LogConfig logConfig, ILoggerFactory loggerFactory) { _logger = loggerFactory.CreateLogger<LogBatchBlock<T>>(); _dirPath = logConfig.DirPath; if (!Directory.Exists(_dirPath)) { Directory.CreateDirectory(_dirPath); } _logHead = logConfig.LogHead; _packer = new BatchBlock<T>(logConfig.BatchSize); batchWriterBlock = new ActionBlock<T[]>(models => WriteToFile(models)); // 形成pipeline必须放在LinkTo前面 _packer.LinkTo(batchWriterBlock, new DataflowLinkOptions { PropagateCompletion = true }); // 防止BatchPacker一直不满足10条数据,无法打包,故设定间隔15s强制写入 _triggerBatchTimer = new Timer(state => { _packer.TriggerBatch(); }, null, TimeSpan.Zero, TimeSpan.FromSeconds(logConfig.Period)); // 实时写文件流能确保随时生成文件,但存在极端情况:某小时没有需要写入的数据,导致该小时不会创建文件,以下定时任务确保创建文件 _logFileIntervalTimeSpan = TimeSpan.Parse(logConfig.LogFileInterval); _openFileTimer = new Timer(state => { AlignCurrentFileTo(DateTime.Now); }, null, TimeSpan.Zero, _logFileIntervalTimeSpan); } public ITargetBlock<T> InputBlock => _packer; private void AlignCurrentFileTo(DateTime dt) { if (!_nextCheckpoint.HasValue) { OpenFile(dt); } if (dt >= _nextCheckpoint.Value) { CloseFile(); OpenFile(dt); } } private void OpenFile(DateTime now, string fileSuffix = null) { string filePath = null; try { var currentHour = now.Date.AddHours(now.Hour); _nextCheckpoint = currentHour.Add(_logFileIntervalTimeSpan); int hourConfiguration = _logFileIntervalTimeSpan.Hours; int minuteConfiguration = _logFileIntervalTimeSpan.Minutes; filePath = $"{_dirPath}/u_ex{now.ToString("yyMMddHH")}{fileSuffix}.log"; var appendHead = !File.Exists(filePath); if (filePath != null) { var stream = new FileStream(filePath, FileMode.Append, FileAccess.Write); var sw = new StreamWriter(stream, Encoding.Default); if (appendHead) { sw.Write(GenerateHead()); } _currentWriter = sw; _logger.LogDebug($"{DateTime.Now} TextWriter has been created."); } } catch (Exception e) { if (fileSuffix == null) { _logger.LogWarning($"OpenFile failed:{e.StackTrace.ToString()}:{e.Message}." ); OpenFile(now, $"-{Guid.NewGuid()}"); } else { _logger.LogError($"OpenFile failed after retry: {filePath}", e); } } } private void CloseFile() { if (_currentWriter != null) { _currentWriter.Flush(); _currentWriter.Dispose(); _currentWriter = null; _logger.LogDebug($"{DateTime.Now} TextWriter has been disposed."); } _nextCheckpoint = null; } private string GenerateHead() { StringBuilder head = new StringBuilder(); head.AppendLine("#Software: " + _logHead.Software) .AppendLine("#Version: " + _logHead.Version) .AppendLine($"#Date: {DateTime.UtcNow.ToString("yyyy-MM-dd HH:mm:ss")}") .AppendLine("#Fields: " + _logHead.Fields); return head.ToString(); } private void WriteToFile(T[] models) { try { lock (_syncRoot) { var flag = false; foreach (var model in models) { if (model == null) continue; flag = true; AlignCurrentFileTo(model.ServerLocalTime); _currentWriter.WriteLine(model.ToString()); } if (flag) _currentWriter.Flush(); } } catch (Exception ex) { _logger.LogError("WriteToFile Error : {0}", ex.Message); } } public bool AcceptLogModel(T model) { return _packer.Post(model); } public string GetDirPath() { return _dirPath; } public async Task CompleteAsync() { _triggerBatchTimer.Dispose(); _openFileTimer.Dispose(); _packer.TriggerBatch(); _packer.Complete(); await InputBlock.Completion; lock (_syncRoot) { CloseFile(); } } }
注意事项 :异常处理
上述程序在部署时就遇到相关的坑位,在测试环境_eqid2ModelTransformBlock 内Func委托稳定执行,程序并未出现异样;
部署到生产之后, 该Pipeline运行一段时间就停止工作,一直很困惑, 后来通过监测_eqid2ModelTransformBlock.Completion 属性,发现该块在执行某次Func委托时报错,提前进入完成态
官方资料表明: 某块进入Fault、Cancel状态,都会导致该块提前进入“完成态”,但因Fault、Cancle进入的“完成态”会导致 输入buffer和输出buffer 被清空。
After Fault has been called on a dataflow block, that block will complete, and its Completion task will enter a final state. Faulting a block, as with canceling a block, causes buffered messages (unprocessed input messages as well as unoffered output messages) to be lost.
当TPL Dataflow不再处理消息并且能保证不再处理消息的时候,就被定义为 "完成态", IDataflow.Completion属性(Task对象)标记了该状态, Task对象的TaskStatus枚举值描述了此Block进入完成态的真实原因
- TaskStatus.RanToCompletion "成功完成" 在Block中定义的任务
- TaskStatus.Fault 因未处理的异常 导致"过早的完成"
- TaskStatus.Cancled 因取消操作 导致 "过早的完成"
故需要小心处理异常, 一般情况下我们使用try、catch包含所有的执行代码以确保所有的异常都被处理。
 本文作为TPL Dataflow的入门指南,微软技术栈的同事可持续关注这个基于Actor模型的流水线处理组件,处理单体程序中高并发,低延迟场景相当巴适。
本文作为TPL Dataflow的入门指南,微软技术栈的同事可持续关注这个基于Actor模型的流水线处理组件,处理单体程序中高并发,低延迟场景相当巴适。
码甲拙见,如有问题请下方留言大胆斧正;码字+Visio制图,均为原创,看官请不吝好评+关注, ~。。~
本文欢迎转载,请转载页面明显位置注明原作者及原文链接。