上一篇文章我们学习了最短路径的两个算法。它们是有环图的应用。下面我们来谈谈无环图的应用。
一、拓扑排序
博主大学学的是土木工程,在老本行,施工时很关键的节约人力时间成本的一项就是流水施工,钢筋没绑完,浇筑水泥的那帮兄弟就得在那等着,所以安排好流水施工,让工作周期能很好地衔接就很关键。这样的工程活动,抽象成图的话是无环的有向图。
在表示工程的有向图中,用顶点表示活动,弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,成为AOV网(Active On Vertex Network)
※ 若在一个具有n个顶点的有向图G = (V,E)中,V中的顶点序列v1,v2, …… , vn满足若从顶点vi到vj有一条路径,则在顶点序列中,顶点vi必然在vj之前。则我们称这样的顶点序列为一个拓扑序列。
所谓拓扑排序,其实就是对一个有向图构造拓扑序列的过程。构造时会有两个结果:1,此网的全部顶点都被输出,则说明它是不存在环的AOV网;2,如果输出顶点数少了,哪怕是少了一个,也说明这个网存在回路,不是AOV网。
拓扑排序算法:
对AOV网进行拓扑排序的基本思路是:从AOV网中选择一个入度为0的顶点输出,然后删去此顶点和以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或者AOV网中不存在入度为0的顶点为止。
拓扑排序算法的实现显然用邻接表比较方便。我们还需要另外一个辅助的栈来存储入度为0的顶点,免得每次找入度为0的顶点都要遍历整个图。
给出示例图如下:
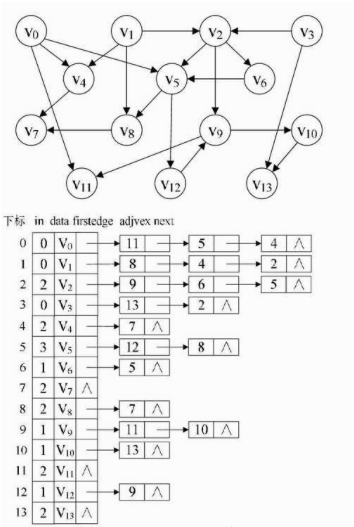
代码实现:
//边结点的定义 package Graph.TopologicalSort; public class Edge { private int begin; private int end; private Edge next; public Edge getNext() { return next; } public void setNext(Edge next) { this.next = next; } public Edge(int begin, int end){ this.begin = begin; this.end = end; this.next = null; } public int getBegin() { return begin; } public void setBegin(int begin) { this.begin = begin; } public int getEnd() { return end; } public void setEnd(int end) { this.end = end; } }
//顶点结点的定义 package Graph.TopologicalSort; public class Vertex { private int data; private int in; private int out; private Edge edge; public Vertex(int data){ this.data = data; this.in = 0; this.out = 0; edge = null; } public Edge getEdge() { return edge; } public void setEdge(Edge next) { this.edge = next; } public int getData() { return data; } public void setData(int data) { this.data = data; } public int getIn() { return in; } public void setIn(int in) { this.in = in; } public int getOut() { return out; } public void setOut(int out) { this.out = out; } }
package Graph.TopologicalSort; import java.util.Stack; public class DigraphAdjust { private int numVertex; private int maxNumVertex; private Vertex[] vertexs; public DigraphAdjust(int maxNumVertex){ this.maxNumVertex = maxNumVertex; vertexs = new Vertex[maxNumVertex]; numVertex = 0; } public void addVertex(int data){ Vertex newVertex = new Vertex(data); vertexs[numVertex++] = newVertex; } public void addEdge(int begin, int end){ Edge newEdge = new Edge(begin, end); Vertex beginV = vertexs[begin]; beginV.setOut(vertexs[begin].getOut() + 1); vertexs[end].setIn(vertexs[end].getIn() + 1); if (beginV.getEdge() == null) { beginV.setEdge(newEdge); }else { Edge e = beginV.getEdge(); beginV.setEdge(newEdge); newEdge.setNext(e); } } public void deleteVertex(int index){ Edge e = vertexs[index].getEdge(); int k; for (; e != null; e = e.getNext()){ vertexs[e.getEnd()].setIn(vertexs[e.getEnd()].getIn() - 1); k = vertexs[e.getEnd()].getIn(); if (k == 0){ zeroIn.push(e.getEnd()); } } //这里并非真的删除顶点,而是只让后续结点的入度减一即可 /* for (int i = index; i < numVertex - 1; i++) { vertexs[i] = vertexs[i + 1]; } numVertex--; */ } private Stack<Integer> zeroIn = new Stack<>(); //拓扑算法 public boolean TopologicalSort(){ for (int i = 0; i < numVertex; i++){ if (vertexs[i].getIn() == 0){ zeroIn.push(i); } } int count = 0; while (!zeroIn.isEmpty()){ int node = zeroIn.pop(); System.out.println(vertexs[node].getData() + " " + ++count); deleteVertex(node); } if (count < numVertex){ return false; }else { return true; } } }
总结:对一个具有n个顶点e条弧的AOV网来说,扫描顶点表将入度为0的顶点入栈的时间复杂度是O(n),之后的while循环中,每个顶点进一次栈,出一次栈,入度减1的操作共执行了e次,所以整个算法的时间复杂度为O(n+e)
二、关键路径
关键路径是为了解决工程完成需要的最短时间问题。
在一个表示工程的带权有向图中,用顶点表示事件,用有向图表示活动,用边上的权值表示活动的持续时间,这种有向图的边表示活动的网,我们称之为AOE网。
如下:
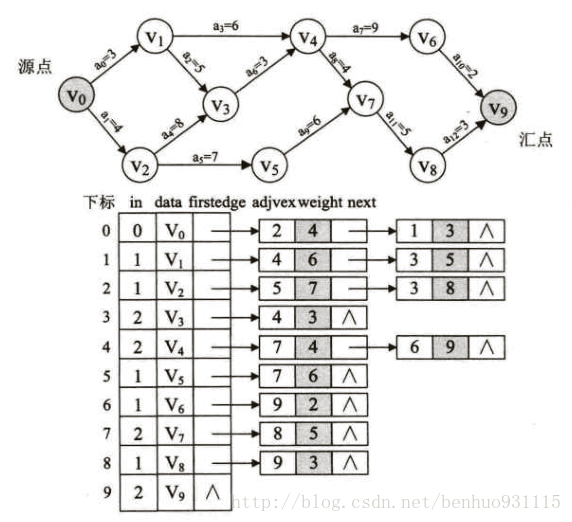
路径上各个活动所持续的时间之和成为路径长度,从原点到终点具有最大长度的路径叫做关键路径,在关键路径上的活动叫做关键活动。
为此,需要定义如下几个参数:
1.事件的最早发生时间etv(earliest time of vertex):即顶点vkvk的最早发生时间
2.事件的最晚发生时间ltv(latest time of vertex):即顶点vkvk的最晚发生时间,也就是每个顶点对应的事件最晚需要开始时间,超出此时间将会延误整个工期
3.活动的最早开工时间ete(earliest time of edge):即弧akak的最早发生时间
4.活动的最晚开工时间lte(latest time of edge):即弧akak的最晚发生时间,也就是不推迟工期的最晚开工时间
如何找关键路径:
如果一个活动,它的最早开始时间和最晚开始时间是一样的,也就是说,它不能被拖延,那么它就是关键活动了。关键活动的长度决定了工程总耗时。那么我们找到所有活动的最早开始时间和最晚开始时间,比较哪些活动的二者是相等的,这些活动就是关键活动。
关键路径算法:
我们先求事件的最早发生时间etv,利用我们上面讲过的从头至尾找拓扑序列的过程,并且在这个过程中存下每个顶点前驱的发生时间加上二者之间边的权值,就是该顶点的最早发生时间。
代码如下
import java.util.Stack; public class Graph { private int numVertex; private int maxNumVertex; private VertexC[] vertexs; public Graph(int maxNumVertex){ this.maxNumVertex = maxNumVertex; vertexs = new VertexC[maxNumVertex]; numVertex = 0; } public void addVertex(int data){ VertexC newVertex = new VertexC(data); vertexs[numVertex++] = newVertex; } public void addEdge(int begin, int end, int weight){ EdgeC newEdge = new EdgeC(begin, end, weight); VertexC beginV = vertexs[begin]; beginV.setOut(vertexs[begin].getOut() + 1); vertexs[end].setIn(vertexs[end].getIn() + 1); if (beginV.getEdge() == null) { beginV.setEdge(newEdge); }else { EdgeC e = beginV.getEdge(); beginV.setEdge(newEdge); newEdge.setNext(e); } } public void deleteVertex(int index){ EdgeC e = vertexs[index].getEdge(); int k; for (; e != null; e = e.getNext()){ vertexs[e.getEnd()].setIn(vertexs[e.getEnd()].getIn() - 1); k = vertexs[e.getEnd()].getIn(); if (k == 0){ zeroIn.push(e.getEnd()); } //关键部分:求各顶点事件的最早发生时间。 //即刚刚被删除的顶点的最早发生时间加上这两点之间权值 与 要求的顶点之前的最早发生时间 之间取较大值 if(etv[topoStack.peek()] + e.getWeight() > etv[e.getEnd()]){ etv[e.getEnd()] = etv[topoStack.peek()] + e.getWeight(); } } //这里并非真的删除顶点,而是只让后续结点的入度减一即可 /* for (int i = index; i < numVertex - 1; i++) { vertexs[i] = vertexs[i + 1]; } numVertex--; */ } private Stack<Integer> zeroIn = new Stack<>(); private Stack<Integer> topoStack = new Stack<>(); private int[] etv; //事件的最早发生时间 private int[] ltv; //事件的最晚发生时间 //拓扑排序算法 public boolean TopologicalSort(){ for (int i = 0; i < numVertex; i++){ etv = new int[numVertex]; if (vertexs[i].getIn() == 0){ zeroIn.push(i); } etv[i] = 0; } int count = 0; while (!zeroIn.isEmpty()){ int node = zeroIn.pop(); //System.out.println(vertexs[node].getData() + " " + ++count); topoStack.push(node); //将弹出的顶点序号压入拓扑排序的栈 deleteVertex(node); } if (count < numVertex){ return false; }else { return true; } }
然后将ltv数组初始化为etv[]最后一个元素的值,每个顶点的最晚发生时间是其每个后继节点的最晚发生时间减去二者之间活动的持续时间,这样我们求得了ltv数组。
之后再根据etv数组和ltv数组求得ete数组。ete数组是活动的最早开工时间,它等于它的前驱事件的最早发生时间,也就是说ete数组和etv数组是相等的。
lte数组是活动的最晚开工时间,也就等于它的后继事件的最晚发生时间减去活动的持续时间,也就等于对应的ltv数组减去weight。这样我们把两个数组都求出来了。
后面只需要比较每个顶点的ete和lte是否相等,就知道这个活动是不是关键活动。代码如下
public void CriticalPath(){ int[] ete = new int[numVertex]; //保存边上活动的最早开始时间,其index表示该边begin的index int[] lte = new int[numVertex]; //保存边上活动的最晚开始时间 EdgeC e; //下面用来保存顶点的临时变量 TopologicalSort(); //先通过拓扑排序求出etv //初始化ltv ltv = new int[numVertex]; for (int i = 0; i < numVertex; i++){ ltv[i] = etv[numVertex - 1]; } while (!topoStack.isEmpty()) { int node = topoStack.pop(); int adj; //求得每一个顶点事件的最晚发生时间,类似反向拓扑排序 for (e = vertexs[node].getEdge(); e != null; e = e.getNext()) { adj = e.getEnd(); if (ltv[adj] - e.getWeight() < ltv[node]) { ltv[node] = ltv[adj] - e.getWeight(); } } for (int i : ltv) { System.out.println(i); } } //求关键路径 . + for (int index = 0; index < numVertex; index++){ for (e = vertexs[index].getEdge(); e != null; e = e.getNext()){ ete[index] = etv[index]; lte[index] = ltv[e.getEnd()] - e.getWeight(); if (ete[index] == lte[index]){ System.out.printf("(%d,%d) : %d ", vertexs[index].getData(), vertexs[e.getEnd()].getData(), e.getWeight()); } } } }
这个例子只是求得了唯一一条关键路径,并不代表再别的例子中不存在多条关键路径。
到这里图就基本讲的差不多了,下面放框架