对于大多数的博友来说,hs_strcpy一定会很陌生,因为这个hs_strcpy这个关键字和我的工作有挂钩。本来目前就职于恒生电子,hs_strcpy是中间件中公司定义的字符串拷贝方法,在工作业余之余,看过了一篇缓冲区溢出的文章,处于好奇心就看了一下公司内部的底层代码,发现了hs_strcpy这个函数的实现,突然发现原来这个还是其实也是存在缓冲区溢出的。什么是缓冲区溢出、如何防止缓冲区溢出,是我写这篇文章的真正目的。小编自称菜鸟,如果有写的不对的地方,请多多批评。
专有名字解释
在看下文之前,我们还是先看一下专有的名词解释吧,这样可以更好的带大家全面的了解本文的核心内容。
1.缓冲溢出(Buffer overflow),是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,使得溢出的数据覆盖在合法数据上,理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符,但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患。操作系统所使用的缓冲区又被称为"堆栈".。在各个操作进程之间,指令会被临时储存在"堆栈"当中,"堆栈"也会出现缓冲区溢出。[1]
2. 栈(操作系统):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。[2]
3. ESP(Extended stack pointer)是指针寄存器的一种(另一种为EBP)。用于堆栈指针。[3]
4. 扩展基址指针寄存器(extended base pointer) 其内存放一个指针,该指针指向系统栈最上面一个栈帧的底部。[4]
5. 栈帧也叫过程活动记录,是编译器用来实现过程/函数调用的一种数据结构。[5]
开门见山
随着IDE工具的越来越发达,越来越多的程序员开始疏忽缓冲区溢出,甚至一些开发程序员从未听说过此专有名词。当然如果真的发生了缓冲溢出,那还是非常可怕的,虽然光大的乌龙指并非缓冲溢出所为,但是缓冲区可以再次创造光大的乌龙指。所以我们开发人员不可以忽视我们程序的缓冲区溢出问题。
那到底什么是缓冲区溢出呢?顾名思义,缓冲区溢出的含义是为缓冲区提供了多于其存储容量的数据,打个比方,我有一个100ml的水杯,但是我倒入了120ml的水,那么20ml的水就会溢出杯子,造成一些想不到的后果。
strcpy和hs_strcpy
我们先来看一下微软为我们开发人员提供的strcpy这个api函数的实现源码(参考百度百科):
/********************** * C语言标准库函数strcpy的一种典型的工业级的最简实现 *返回值:目标串的地址。 *对于出现异常的情况ANSI-C99标准并未定义,故由实现者决定返回值,通常为NULL。 *参数: * strDestination 目标串 * s /* GNU-C中的实现(节选): */ char* strcpy(char *d, const char *s) { char *r=d; while((*d++=*s++)); return r; } /* while((*d++=*s++)); 的解释:赋值表达式返回左操作数,所以在复制NULL后,循环停止ֹ */ 在比较一下恒生公司自定义开发的源码(本人在服务器的文件中找到了定义和实现的整个代码): int hs_strcpy(char *d_dest,const char *s_src) { if (isnull(s_src) == 0) { d_dest[0] = '�'; return(-1); } if (d_dest == NULL) return(-1); for(; *d_dest++ = *s_src++; ) /* the same as strcpy. */ ; return(0); }
这里我们可以看出,strcpy这个函数把自己所有的字符都依次赋值给了d这个指针,然后再把r这个字符指针指向d的开始位置(d[0]的地址),并返回了r指针的地址。然而恒生自定义的hs_strcpy有着异曲同工之处,就是把src中的内容依次赋值给dest。如果正确就返回0,错误返回-1(其实这里我有一点不明白,就是不知道当初的设计人员为什么把返回类型定义成int类型而不是Bool类型,因为我觉得可能bool类型效率、性能都会更好);唯一不同的是设计者判断了一下src和dest是否为空。虽然说来,公司自定义的开发的字符串拷贝函数在效率方便有了一定的提高,但是由于在strcpy中本身就存在缓冲溢出的问题,所以很遗憾的告诉开发者,hs_strcpy也存在同样的缓冲溢出问题。
用代码讲话
下面我就直接把代码粘贴出来,把这个bug重现出来,当然不同的编译器或者是编译的环境不同(debug和release),虽然同样的代码,但是执行的结果可能不一样,如果你拷贝了我的代码,但是问题却不重现,先检查一下自己的IDE环境。
IDE环境:
开发工具:VC6.0 编译模式(debug)
IDE界面图1
Strcpy缓冲溢出:
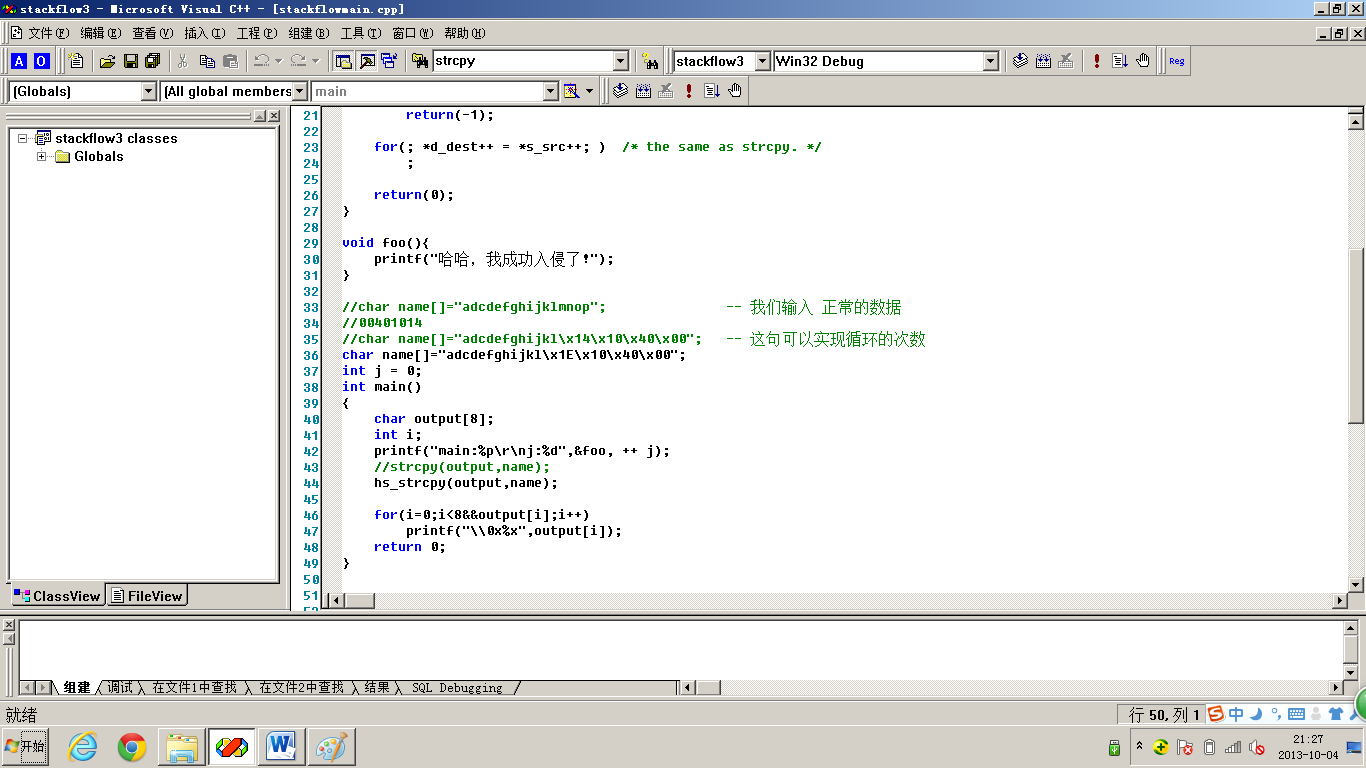
#include <stdio.h> #include <string.h> void foo(){ printf("哈哈,我是被strcpy缓冲溢出的地方"); } //最简单的缓冲溢出例子 int main(){ char output[8]; //char name[] = "adcdefg"; //① 我们希望输入正确的值 //char name[] = "adcdefghijklmnop"; //② 我们用过量的字符串来填充,造成缓冲溢出,这里我们可以参考一下str_cpy_1的图 // 得到了foo的Address为0040101E 具体要怎么测溢出点的位置,最好切换到xp环境下,会有错误信息,根据错误信息查找ascill值 // 不知道你们注意到了没有,我这里不用aaa...而是用abc...,是因为我既要让程序溢出,而且要确切的知道溢出点。因为找地址会打印出来字符的ascill,比如小写的a对应的十进制acill值为97,但是如果控制台打印出来97 97 97 97 我们就不知道到底是从那个字母开始缓冲区溢出了,但是如果我们设置成abcd… 假如提示98 99 …,我们就知道从b开始发生了缓冲区溢出 // (这里的溢出点为mnop) char name[] = "adcdefghijklx1Ex10x40x00";//③ 重点:我们以此修改mnop的值为刚刚捕获到的foo的地址的值,但是需要注意我们要从后面开始修改 // 我们修改好了之后再次运行,发现了什么,注意我这里是debug模式 printf("foo Address : %p",&foo); strcpy(output,name); return 0; }
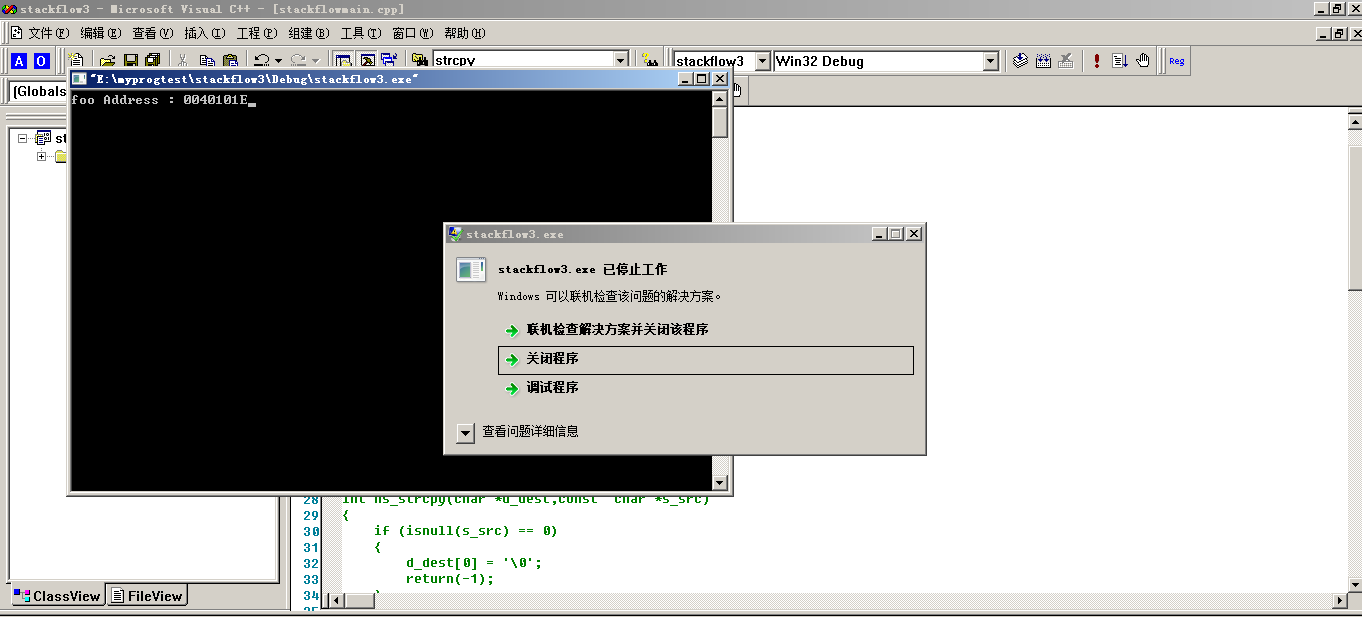
图2 strcpy_1
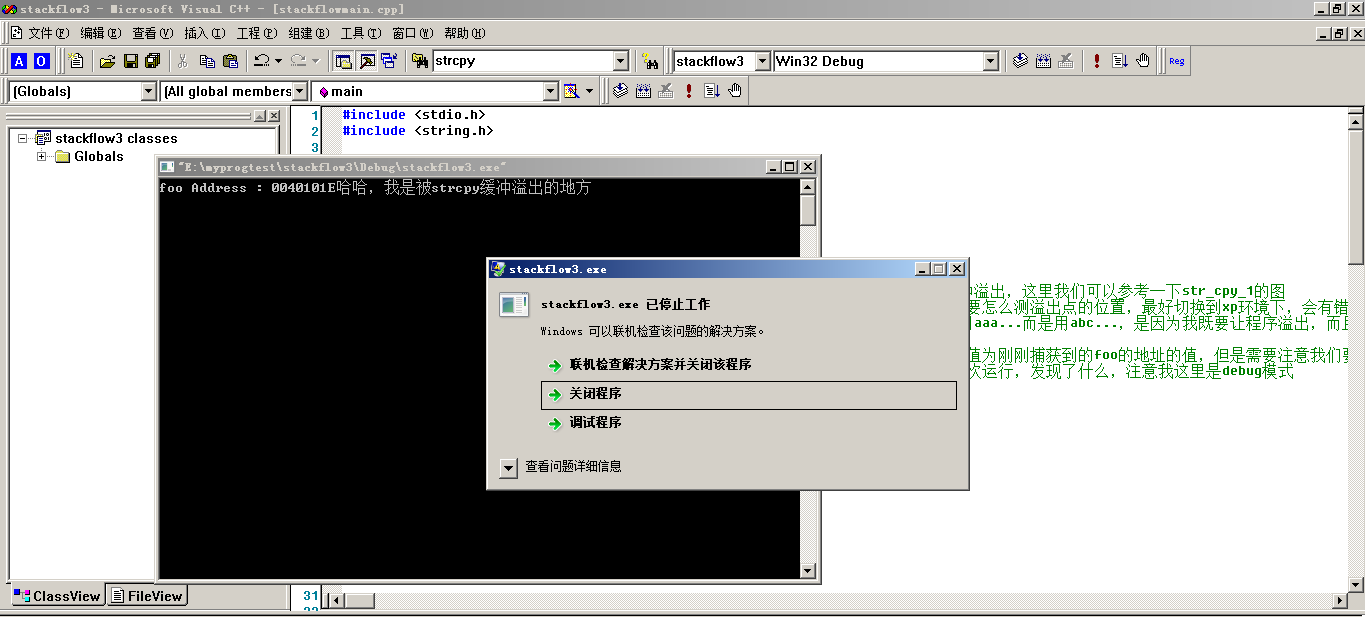
图3 strcpy_2
hs_strcpy缓冲溢出:
//下面hs_strcpy 和 isnull 都是恒生公司自己设计的 #include <stdio.h> int isnull(const char *d_str) { if (d_str == NULL || d_str[0] == '�') return(0); return(1); } int hs_strcpy(char *d_dest,const char *s_src) { if (isnull(s_src) == 0) { d_dest[0] = '�'; return(-1); } if (d_dest == NULL) return(-1); for(; *d_dest++ = *s_src++; ) /* the same as strcpy. */ ; return(0); } // ͬ同样的我们定义一个foo函数,来作为攻击的对象 void foo(){ printf("哈哈,我是因为hs_strcpy函数中被攻击进来的!"); } //char name[] = "adcdefg"; // ① 我们希望输入正确的数据,功能正常 //char name[]="adcdefghijklmnop"; // ② 我们输入过多的字符,造成缓冲溢出,来寻找地址,通strcpy方法,最后还是找到 // 最后我们还是找到了mnop为缓冲溢出的地址,我们来修改缓冲地址 // 得到的foo地址还是为0040101E //char name[] = "adcdefghijklx1Ex10x40x00"; //③ 重点,同strcpy char name[] = "adcdefghijklx05x10x40x00"; int j = 0; int main() { char output[8]; int i; printf("foo Address:%p ---- main Address:%p----count(j):%d ",&foo,&main, ++ j); hs_strcpy(output,name); return 0; }
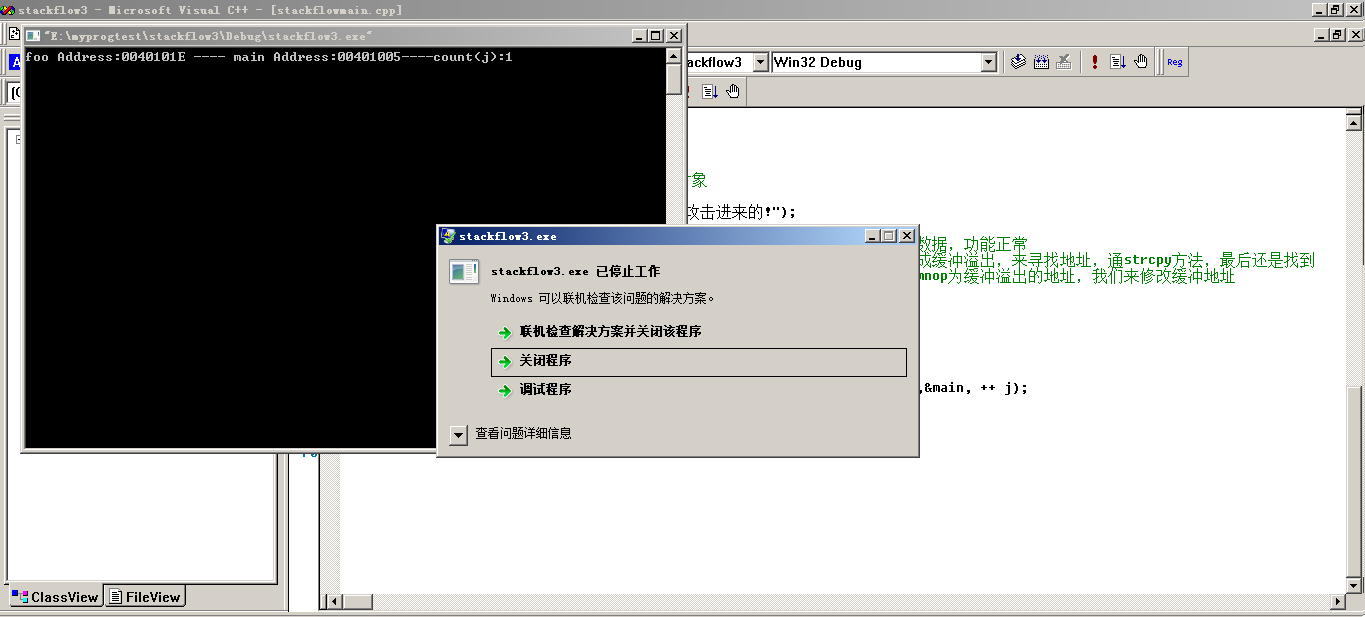
图4 测试foo地址进行攻击

图5 hs_strcpy缓冲溢出
一图揭秘缓冲溢出:
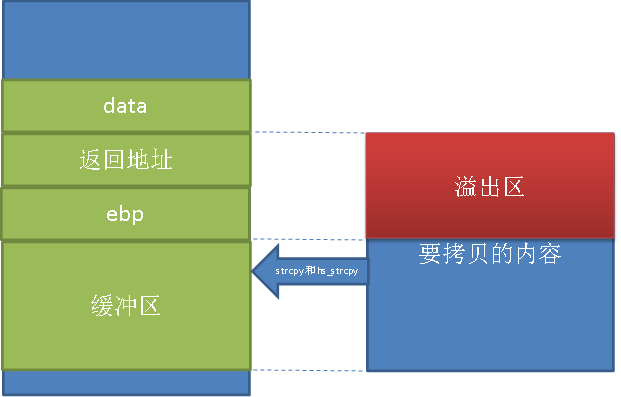
图6 缓冲溢出解析图
可能你已经从图中看明白了,为什么会发生缓冲溢出。但是我自己还想唠叨一下,在和那些可能还未理解的人解释一下。对于任何一个函数而言,在调用这个函数时,调用的函数的参数需要入栈,并将call function指令下一条指令的地址,并保存到栈内,然后再跳转到function函数内部执行。每个函数定义都会有函数头和函数尾代码,函数内需要用ebp保存函数栈帧基地址,因此先保存ebp原来的值到栈内,然后将栈指针esp内容保存到ebp(栈顶是不用保存的,因为上一个栈帧的顶部将会是调用的栈帧底部。(两栈帧相邻的))。函数返回前需要做相反的操作——将esp指针恢复,并弹出ebp。这样,函数内正常情况下无论怎么使用栈,都不会使栈失去平衡。然而当我们填充的缓冲区的内容一旦超过其本身的缓冲区容量,那么我们将会一次去占用ebp、返回地址里面的内容。从而导致缓冲区溢出的问题。
光大乌龙指再现
通过上面的代码,我们可以看到程序只是简简单单的访问了一个不该访问的Addr,但是怎么会出现原本一次发包而变成多次发包呢?其实很简单,我们来看一下在hs_strcpy函数中,有打印出来了foo的地址和main的地址,其实会有一些想法的人肯定会知道,这里不是简简单单的打印一下,我们是为了再次创建“乌龙指”而设下的代码,我们原先只是通过简简单单的调用到foo的地址,但是我们想想看,如果我们缓冲溢出,并且修改溢出的地址为main函数地址(注意了,这里所说的main函数,他也是一个函数,但是却是一个特殊的函数,作为函数的一开始调用的地方,当然这话不是绝对的,我们还是有办法修改不从main开始,扯得有点远了)。代码就不贴了,直接看一下效果图把:
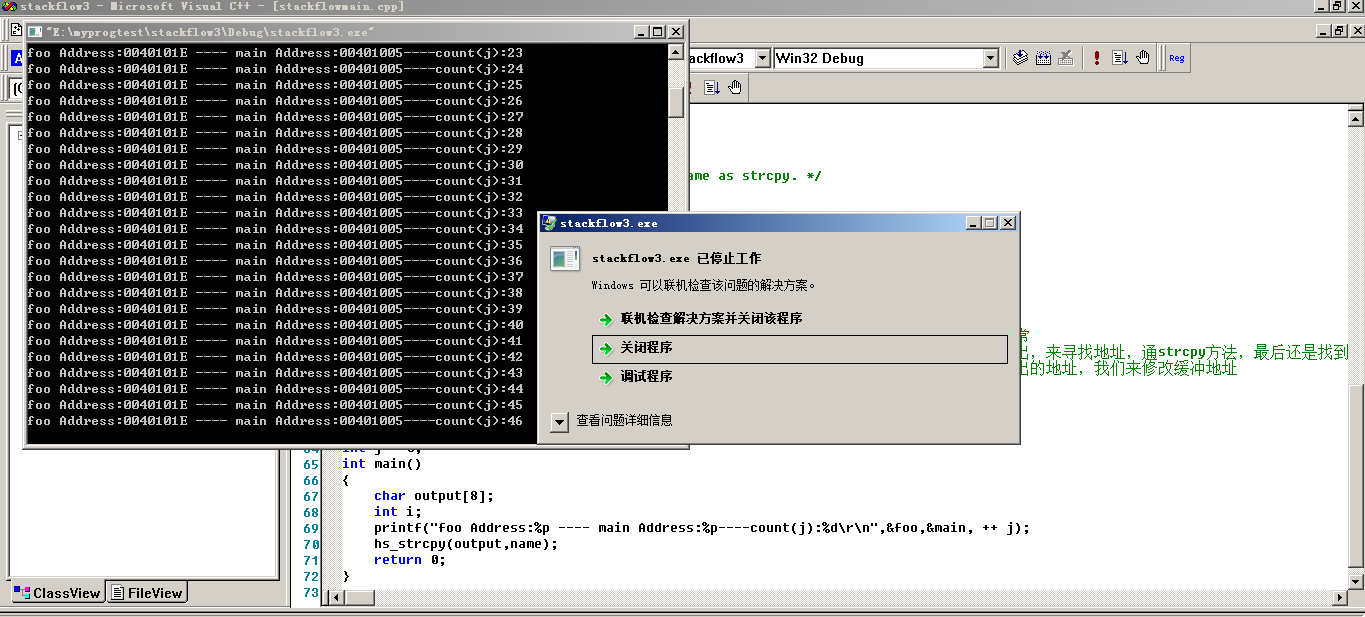
图7 “无限”循环
这里所谓的无限循环还是有待商榷的,确切的说,可以循环的次数还是和申请到栈的大小有关系的,在win7 64位中被循环了46次之多,而在xp 32位环境中却被循环了32次。
可能有些人会反驳说,这个缓冲的溢出在特定的环境下和特定的运行环境下才会发生,比如说在VC6.0中debug模式下发生,但是如果我在release模式下面就不会发生了,非常遗憾的告诉你,缓冲溢出并非只是在debug下的缺陷,在release模式下面照样可以发生,当然也有人成功制造了在linux环境下的,发生缓冲溢出。
缓冲区溢出无处不在
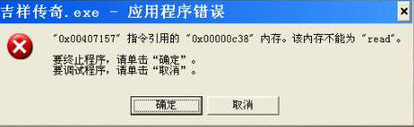
图8 XP缓冲区溢出图
我想我们这辈人还是从xp玩转过来吧,所以对上面的这张图片应该不会陌生。在xp中,我们经常可以看到类似上面的错误。其实上面的错误就是由于软件设计的不合理,引发的缓冲区溢出,从图上我们可以看到他的返回地址被修改成为了0x00407157。当然在0x00407157不是一个函数的开始地址,所有程序不能走了,那就只能报错了;但如果0x00407157是一个函数地址,而且是一个敏感的函数,那么会发生什么,我想大家应该心里明白了。
如何避免缓冲的溢出
前面我们已经系统的看过了缓冲发生的整个过程,那么我们有什么办法避免呢,呵呵,我想已经有人其实有想法了,那就是我们去控制src输入的字符串长度。我不知道开发人员是否注意到我们在开发时,大多数的情况下,hs_strcpy是长度是一个定值,比如hs_strcpy(char[8],char[8]),但是在一些代码中我们还是可以看到不同长度的赋值如hs_strcpy(char[8],char[128])等等。那后者很容易发生所谓的缓冲溢出。还有一种情况就是我们开发的时候,前端(delphi)传过来的值就已经缓冲溢出了,所以有的时候,我们在允许用户输入数据的时候,把文本框控件的maxlength设置一下比较好。写到这里让我想起了培训的那个例子,每个人都只尽了自己90%的努力,程序员没有对输入内容做合法性检查,测试人员没有对敏感数据进行测试,系统框架人员疏忽了一些不安全的代码……,最后到用户手上的就是一个非常可怕的产品,说不一定就会发生类似光大的事件。
总结
当然缓冲溢出并不是简简单单的strcpy这个api函数,而且在很多函数中发生,这里就例举部分:strcpy、strcat、sprintf、scanf、sscanf、fscanf、vfscanf、vsprintf、vscanf、vsscanf、streadd、strecpy、strtrns等等(参考IBM的一篇文章)。感兴趣可以看一下这篇文章或者是查相应的文章或资料。当然网上不推介使用strcpy取而代之的是strncpy。而我推荐的就是在我们前台和后台一起对安全性进行检查。当然我写这篇文章还是比较入门的(如果在深层次点,会涉及到汇编),缓冲溢出并非因这篇文章而结束了,还有很多的地方需要大家去学习。
本文pdf 版本已经上传到我个人网站(http://jcodes.cn),欢迎进去下载。(打开jcodes网站->博客->从hs_strcpy谈安全——缓冲区溢出)