TaskManager接收到来自JobManager的jobGraph转换得到的TDD对象,启动了任务,在StreamInputProcessor类的processInput()方法中
通过一个while(true)中不停的拉取上游的数据,然后调用streamOperator.processElement(record)调用用户实现的方法去处理数据拉取的数据
首先先来看下这个operator对象

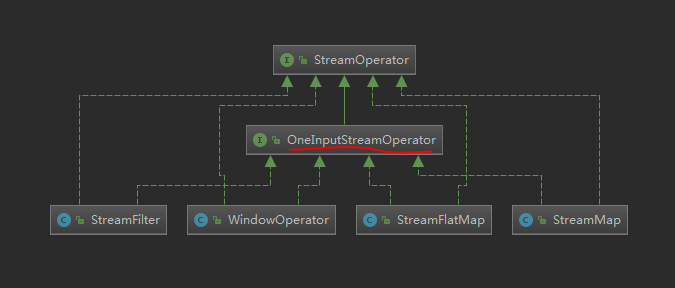
然后看看OneInputStreamOperator类的UML
这里所有的实现类没有全部列出,只列了一些代表
看到这里,写过Flink的streamAPI的同学,肯定感觉到很熟悉!!!!!!
这里!不就是我们常写flink代码的那些算子嘛
对没有错,我们程序中实现的那些算子逻辑,最后都会被封装成一个OneInputStreamOperator,这里具体看一个最熟悉的Fliter
来看一下StreamFilter的processElement方法
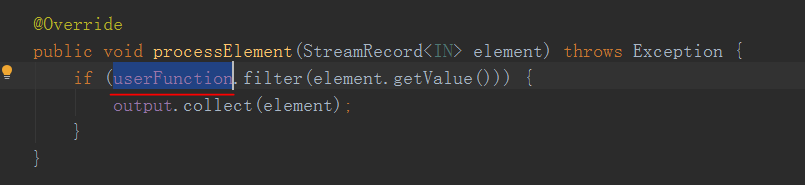
!!!这里传入一个数据后,这个userFunction调用了filter方法并且把数据放进去了
当返回true通过这个output.collect发送出去了
这不就对应了我们用户自己实现的filter算子嘛,没错这个方法其实就是客户端的filter方法,这个userFunction包含了用户实现filter算子的逻辑
(!!!!!就是说这个processElement方法会调用用户的逻辑)
(所以这个userFunction可以带上client的方法实现,这对我们很重要,特别是对flink源码修改,为clientApi添加新功能方法,运行时可以通过这里拿到)
继续
来看看这个output.collect()方法

然后

看到这个,等等等等
我不是从这个processElement()方法进来的吗,怎么又开始调processElement()方法了
难道递归了? 不对不对
这里operator不是上一个operator了,而是这个output对象的(这里是chainOutPut)
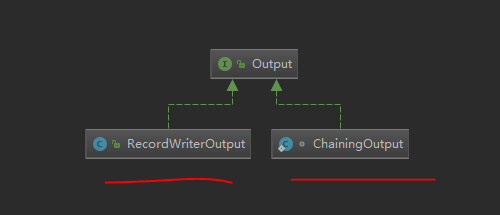
看下这个output对象

看下UML类图,也是只列举了重要的
先看chainingOutPut的属性
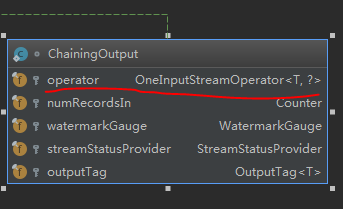
发现了又出现了OneInputStreamOperator对象
看到这个实现类的名字!chain联想起了什么
Flink会将可以chain在一起的算子在streamGraph转换成jobGraph的时候根据条件chain在一起
一惊!
来分别看一下ChainingOutPut和RecordWriterOutput的collect()方法有什么区别
在chain中

在RecordWriter中

这里chain的ouput,又继续调用了下一个operator的processElement方法,然后又在processElement方法中又调用output.collect( ),collect中又调用了下一个operator的processElement方法
整个过程就是个无限的循环,直到,某一个operator的ouput不为ChainingOutPut,当变为RecordWriterOutput时
上面看到RecordWriterOutput的processElement直接emit发送出去了这个数据,再也没有继续调用processElement方法了
这里也就对应了,flink中的责任链,chain在一起的算子会一个接着一个执行,直到无法chain,就会往下游发送emit了
来看一下UML类图帮助理解
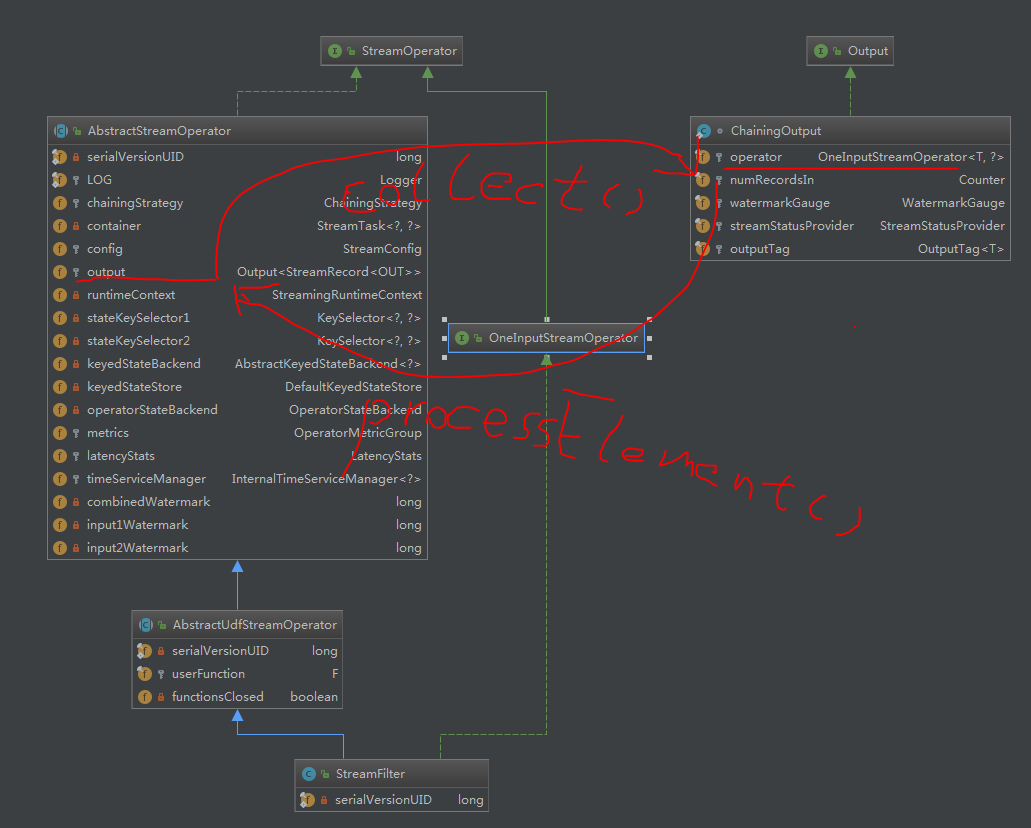
里中有我,我中有你,一直相互调用直到无法chain,然后emit往下游发送(这里肯定就有发送端的反压逻辑,以后随缘更新)
那这里的循环调用理解了就会想,那如何确定第一个operator调用,然后进入整个调用链呢
回到TaskManager接收到JobManager的TDD以后初始化整个任务的时候
StreamTask.java中invoke方法中

先是初始化了一个OperatorChain,里面其实就是一个数组StreamOperator

在他初始化的时候,其实就是为我们所有的streamOutputs设置了他的output以及会根据jobManager发送过来的TDD(包含信息)
设置成对应的ChainingOutPut还是RecordWriterOutput,chainOutput会设置他的的operator
然后获取了getHeadOperator()其实就是获取了他调用连中的第一个
然后在

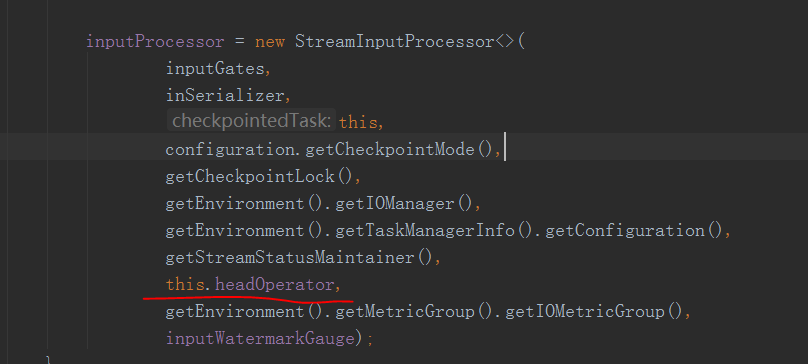
将这个第一个operator关联到了inputProcessor对象里面
后面就简单了在inputProcessor.processInput中就进入了while(true)循环拉取上游数据的逻辑
然后

在这里调用的第一个processElement方法就是我们的那个headOperator
这样整个调用责任链就开始从第一个Operator运行起来了