https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
首先此次作业要感谢师兄的帮助!
写在博客最前:
(1) 本项目使用Python语言。
(2) 本项目代码地址为https://jianghui2.coding.net/public/20200917-2/test/git
一、重点/难点,代码展示以及效果截图和展示
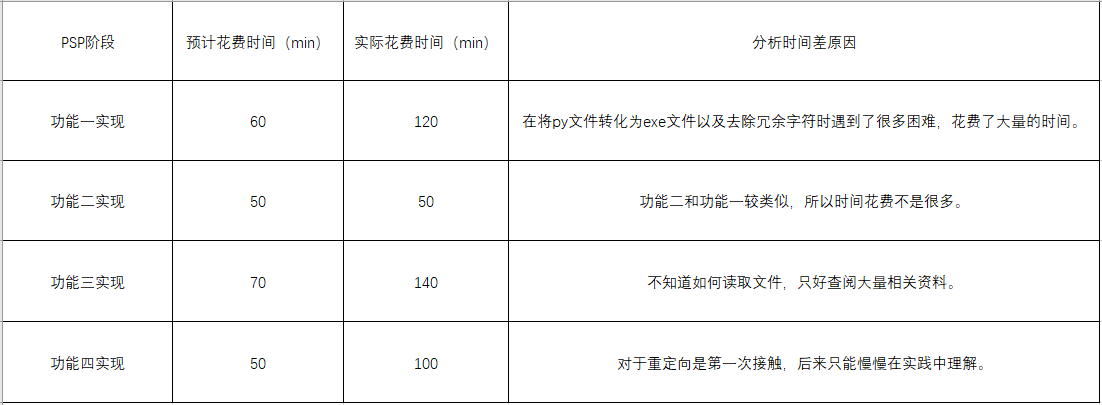
功能1 小文件输入。为表明程序能跑,结果真实而不是迫害老五,请他亲自键盘在控制台下输入命令。
重点/难点 :
(1)如何将py文件转化为exe文件
(2) 词频统计:重难点在于英文字符的去重与删除冗余字符。由于Word中严格按照空格来区分单词,因此将字符等替换为空格即可。去重则利用Python的字
典对文章单词进行遍历,存储单词及频数。
重要代码展示:
删除冗余字符:
def parseText(text): for ch in "~!@#$%^&*(()_+-={}[]<>,.?/;':"|\": text = text.replace(ch, " ") words = text.split() return words
实现功能一:
list1 = text.replace(' ', ' ').lower().split() list2 = list(set(list1)) if (flag == 0): print("total " + str(len(list2))) else: print("total " + str(len(list2)) + " words") print(" ") dir_a = {} for str1 in list1: if str1 != ' ': if str1 in dir_a.keys(): dir_a[str1] = dir_a[str1] + 1 else: dir_a[str1] = 1 dir_b = sorted((dir_a).items(), key=lambda x: x[1], reverse=True)
执行效果截图:

得意、突破、困难的地方 :
函数的了解程度:对isalnum(),jion()函数不熟悉,导致在英文字符的冗余校验和删除过程中进行的十分困难。
删除冗余的字符:按照杨老师提供的测试样例,确定了删除冗余字符的算法,即替换
.,"(软空格、空格、点、逗号、双引号)为空格。在删除时对字符进行遍历,看是否属于以上冗余字符,若是,则替换。避免了反复执行replace()方法,实现了代码的简洁。
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
重点/难点 :
(1)读文件,使用open函数(open(filename,mode,buffering,encoding)方法),将单词存入字典根据空格数计算词频
(2) 读取不包含后缀的文件:读入用户输入的用户名,在用户名后加上".txt"的后缀。此时新的文件名(含后缀)即相当于功能1中要求的文件名。
重要代码展示:
try: with open(filename, 'r', encoding='UTF-8') as f_obj: content = f_obj.read() countNumber(content, flag) except FileNotFoundError: msg = "sorry,the file " + filename + " does not exist." print(msg)
执行效果截图:
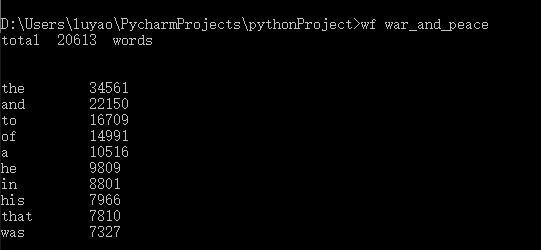
得意、突破、困难的地方 :
大文件:对大文件的筛选难度要明显高于功能一的小文件,学会了使用python中read,open函数。
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
重点/难点 :(1) 命令行参数:首先判断用户当前输入是否为文件夹,由于Python语言可以直接判断当前文件是否含有子文件(即是否为文件夹),故在此处可进行一个判断。判断过后遍历该文件夹下所有后缀为txt的文件,并将其文件名存储在列表之中。
重要代码展示:
找文件:
path = os.listdir(os.getcwd())
folderList = []
for p in path:
if os.path.isdir(p):
读文件:
for folder in folderList: if textFolder == folder: path1 = os.listdir(folder) for i in path1: if os.path.splitext(i)[1] == '.txt': fileNameList.append(os.path.splitext(i)[0])
执行效果截图:
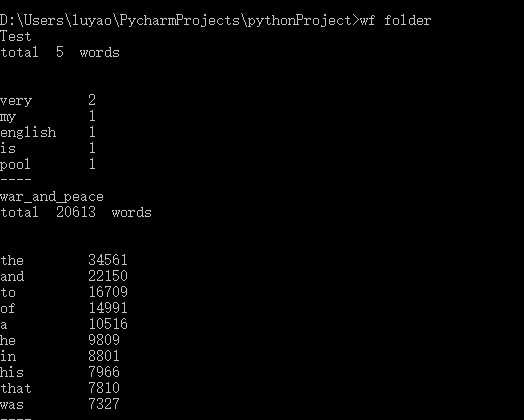
得意、突破、困难的地方 :
函数的调用:不熟悉os.path函数和splitext()函数的调用以及获取文件路径和分离文件后缀的问题,最后迎难而上的去解决了问题!
功能4:从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活的接口)。
重点/难点 :
(1)对于重定向的理解和实践
(2)用户输入文件名或者文本内容的捕获问题。
重要代码展示:
elif sys.argv[1] == "-s": if (len(sys.argv) == 3); flag = 0 countFileWords(sys.argv[2], flag) else: redirect_words = sys.stdin.read() flag = 0 countNumber(redirect_words, flag)
执行效果截图:
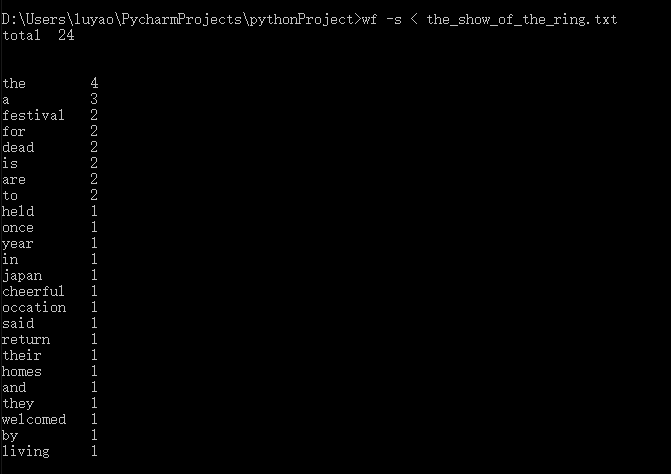
得意、突破、困难的地方 :
对重定向的的实践,是我的一个突破!
二、PSP表格