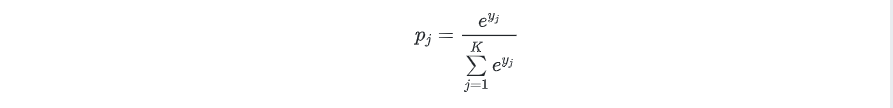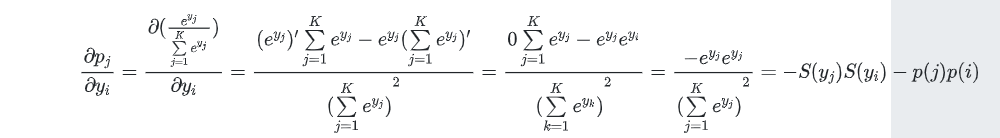0x00 输出层的激励函数 - SOFTMAX
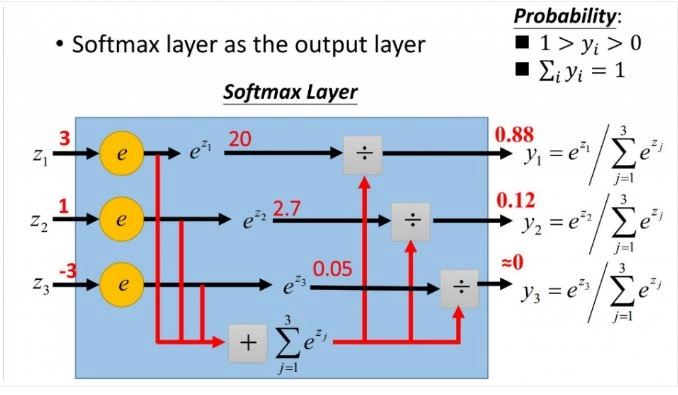
SOFTMAX 长什么样子?如下图所示
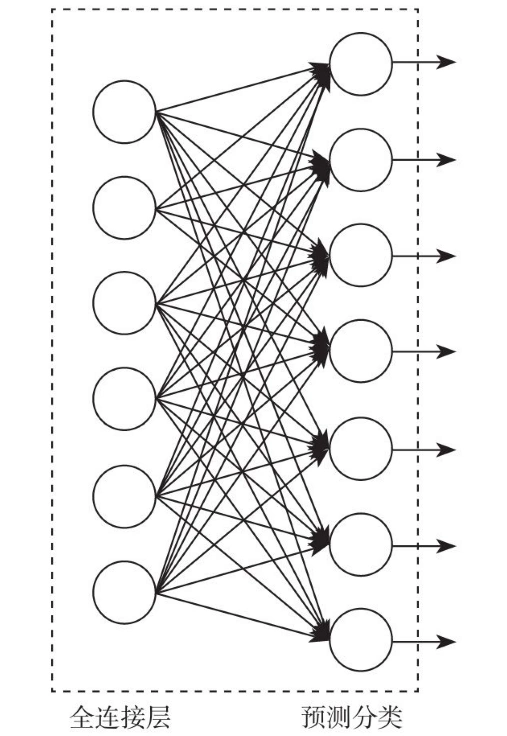
从图的样子上看,和普通的全连接方式并无差异,但激励函数的形式却大不一样。

首先后面一层作为预测分类的输出节点,每一个节点就代表一个分类,如图所示,那么这7个节点就代表着7个分类的模型,任何一个节点的激励函数都是:
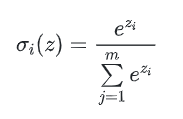
其中就是节点的下标次序 ,而,也就说这是一个线性分类器的输出作为自然常数的指数。最有趣的是最后一层有这样的特性:
,而,也就说这是一个线性分类器的输出作为自然常数的指数。最有趣的是最后一层有这样的特性:
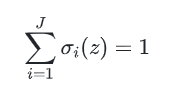
也就是说最后一层的每个节点的输出值的加和是1。这种激励函数从物理意义上可以解释为一个样本通过网络进行分类的时候在每个节点上输出的值都是小于等于1的,是它从属于这个分类的概率。
训练数据由训练样本和分类标签组成。如下图所,j假设有7张图,分别为飞机、汽车、轮船、猫、狗、鸟、太阳,则图像的分类标签如下表示:

这种激励函数通常用在神经网络的最后一层作为分类器的输出,有7个节点就可以做7个不同类别的判别,有1000个节点就可以做1000个不同样本类别的判断。
0x01 熵与交叉熵
熵的本质是香农信息量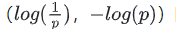 的期望。
的期望。
熵在信息论中代表随机变量不确定度的度量。一个离散型随机变量 X 的熵 H(X) 定义为:
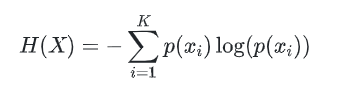
交叉熵刻画的是实际输出概率和期望输出概率的距离,交叉熵的值越小,则两个概率分布越接近,即实际与期望差距越小。交叉熵中的交叉就体现在(期望概率分布),(实际概率分布)。假设概率分布为期望输出,概率分布为为实际输出,为交叉熵。则:
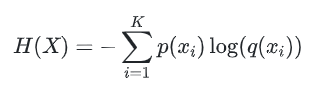
假如,n=3,期望输出,模型1的实际输出为,模型2的实际输出为,那么交叉熵为:
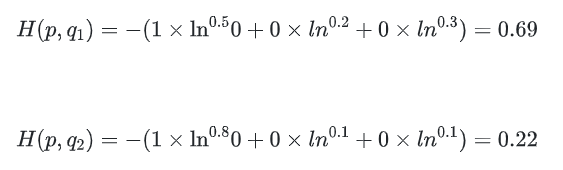
pytorch中的实现:
import torch import numpy as np input1 = torch.from_numpy(np.array([[0.8,0.1,0.1]])) input1.requires_grad=True target1= torch.from_numpy(np.array([0])).long() output1 = loss(input1, target1) print(nll_loss(torch.log(input1),target1))
输出 tensor(0.2231, dtype=torch.float64, grad_fn=<NllLossBackward>)
很显然,和分布更接近。
假如,以“中国乒乓球队和巴西乒乓球对比赛结果”为例:
假设中国乒乓球队和巴西乒乓球队历史交手64次,其中中国队获胜63次,63/64是赛前大家普遍认可的中国队获胜概率,这个是先验概率。
那么这次中国队获胜的平均信息量有多大呢?
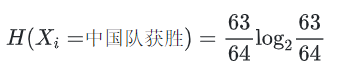
同理:

所以,“中国乒乓球队和巴西乒乓球对比赛结果”,这一信息的信息熵为:
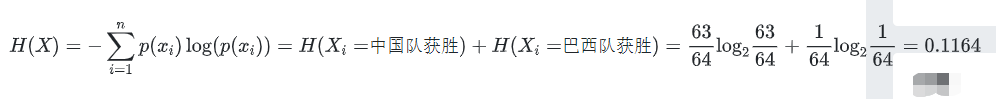
0x02 交叉熵损失函数
为什么Cross Entropy损失函数常用于分类问题中呢?我们从一个简单的例子来分析。
# 问题引入: # 假设我们有一个三分类问题,分别用模型1和模型2来进行预测。
结果如下:
模型1

模型2
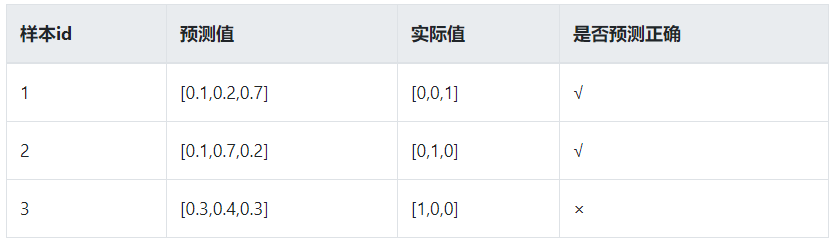
对样本1和样本2,模型1以0.4>0.3的微弱优势正确预测样本1的标签为类别3,而模型2以0.7>0.2>0.1的巨大优势毫无悬念的正确预测出样本标签。
对于样本3,模型1和模型2均预测错误,但模型1以0.7>0.2>0.1的概率,错误的预测样本标签为标签3,但实际标签为标签1,错的离谱!!!但模型2虽然也预测错了,但0.4>0.3>0.2还不算太离谱。
现在我们用损失函数来定义模型的表现。
2.1 Classification Error(分类错误率)

模型1和模型2虽然都预测错了1个,但相对来说模型2表现更好,按理说模型越好,损失函数值越小,但分类错误率并没表现出来。
2.2 Mean Squared Error(均方误差)
均方误差损失也是一种比较常见的损失函数,其定义为:
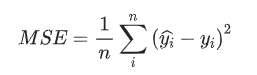
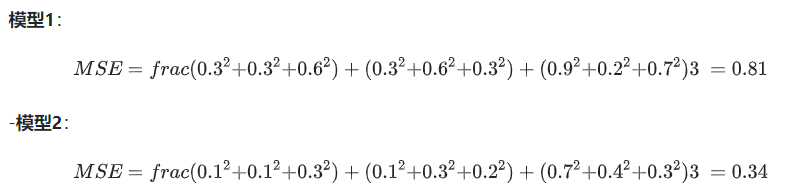
我们发现MSE能判断出模型2优于模型1,但采用梯度下降法来求解的时候,MSE的一个缺点就是其偏导值在输出概率值接近0或者接近1的时候非常小,这可能会造成模型刚开始训练时,梯度几乎消失。
对于分类问题的损失函数来说,分类错误率(分类精确率)和平方和损失都不是很好的损失函数,下面我们来看一下交叉熵损失函数的表现情况。
0x03 交叉熵损失函数的定义
3.1 二分类
在二分类的情况下,模型最终预测的结果只有2类,对于每个类别我们预测的概率为和。
此时Binary Cross Entropy:
其中:
- y : 样本标签,正样本标签为1,负样本标签为0
- p : 预测为正样本的概率
3.2 多分类
多分类实际是二分类的扩展。
其中:
- K : 类别的数量
- y : 是否是类别,
- p : 样本属于类别的概率
现在我们用交叉熵损失函数来计算损失函数值。

可以发现,交叉熵损失函数可以捕捉到模型1和模型2的差异。
3.3 函数性质
交叉熵损失函数经常用于分类问题中,特别是神经网络分类问题,由于交叉熵涉及到计算每个类别的概率,所以在神经网络中,交叉熵与softmax函数紧密相关。
我们用神经网络的最后一层输出情况来看。
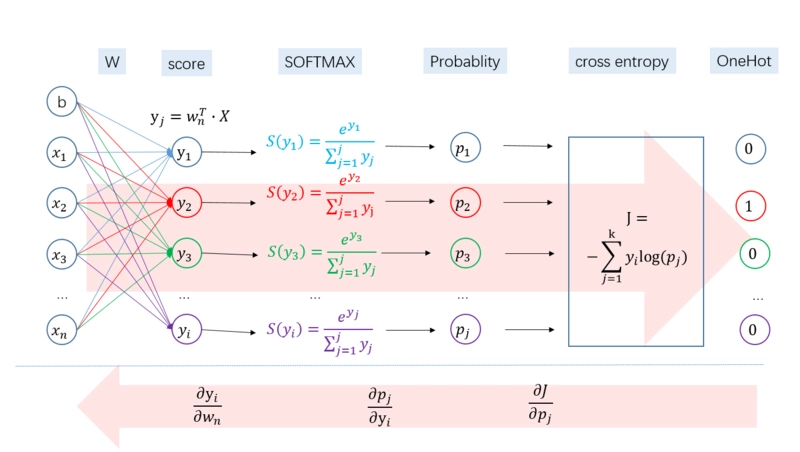
下面我们来推下整个求导公式,求导如图所示,分为三个过程:
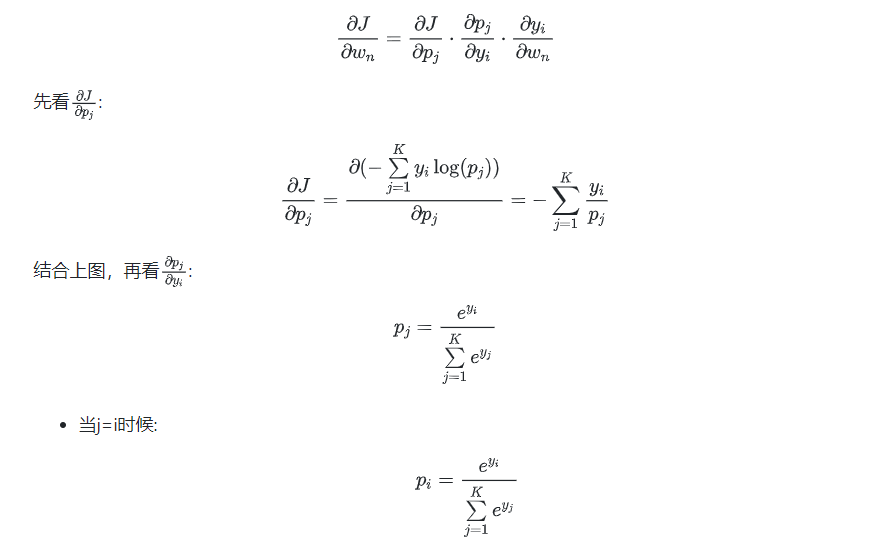

当j≠i时候: