在读了FM和FNN/PNN的论文后,来学习一下16年的一篇Google的论文,文章将传统的LR和DNN组合构成一个wide&deep模型(并行结构),既保留了LR的拟合能力,又具有DNN的泛化能力,并且不需要单独训练模型,可以方便模型的迭代,一起来看下吧。
原文:Wide & Deep Learning for Recommender Systems
地址: https://arxiv.org/pdf/1606.07792.pdf
1、问题由来
1.1、背景
本文提出时是针对推荐系统中应用的,当然也可以应用在ctr预估中。
首先介绍论文中通篇出现的两个名词:
- memorization(暂且翻译为记忆):即从历史数据中发现item或者特征之间的相关性。
- generalization(暂且翻译为泛化):即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
举个例子来解释下:在人类的认知学习过程中演化过程中,人类的大脑很复杂,它可以记忆(memorize)下每天发生的事情(麻雀可以飞,鸽子可以飞)然后泛化(generalize)这些知识到之前没有看到过的东西(有翅膀的动物都能飞)。
但是泛化的规则有时候不是特别的准确,有时候会出错(有翅膀的动物都能飞吗)。这时候就需要记忆(memorization)来修正泛化的规则(generalized rules),叫做特例(企鹅有翅膀,但是不能飞)。这就是Memorization和Generalization的来由或者说含义。
1.2、现有模型的问题
-
线性模型LR简单、快速并且模型具有可解释,有着很好的拟合能力,但是LR模型是线性模型,表达能力有限,泛化能力较弱,需要做好特征工程,尤其需要交叉特征,才能取得一个良好的效果,然而在工业场景中,特征的数量会很多,可能达到成千上万,甚至数十万,这时特征工程就很难做,还不一定能取得更好的效果。
-
DNN模型不需要做太精细的特征工程,就可以取得很好的效果,DNN可以自动交叉特征,学习到特征之间的相互作用,尤其是可以学到高阶特征交互,具有很好的泛化能力。另外,DNN通过增加embedding层,可以有效的解决稀疏数据特征的问题,防止特征爆炸。推荐系统中的泛化能力是很重要的,可以提高推荐物品的多样性,但是DNN在拟合数据上相比较LR会较弱。
-
总结一下:
- 线性模型无法学习到训练集中未出现的组合特征;
- FM或DNN通过学习embedding vector虽然可以学习到训练集中未出现的组合特征,但是会过度泛化。
为了提高推荐系统的拟合性和泛化性,可以将LR和DNN结合起来,同时增强拟合能力和泛化能力,wide&deep就是将LR和DNN组合起来,wide部分就是LR,deep部分就是DNN,将两者的结果组合进行输出。
2、模型细节
再简单介绍下两个名词的实现:
Memorization:之前大规模稀疏输入的处理是:通过线性模型 + 特征交叉。所带来的Memorization以及记忆能力非常有效和可解释。但是Generalization(泛化能力)需要更多的人工特征工程。
Generalization:相比之下,DNN几乎不需要特征工程。通过对低纬度的dense embedding进行组合可以学习到更深层次的隐藏特征。但是,缺点是有点over-generalize(过度泛化)。推荐系统中表现为:会给用户推荐不是那么相关的物品,尤其是user-item矩阵比较稀疏并且是high-rank(高秩矩阵)
两者区别:Memorization趋向于更加保守,推荐用户之前有过行为的items。相比之下,generalization更加趋向于提高推荐系统的多样性(diversity)。
2.1、Wide 和 Deep
Wide & Deep:
Wide & Deep包括两部分:线性模型 + DNN部分。结合上面两者的优点,平衡memorization和generalization。
原因:综合memorization和generalizatio的优点,服务于推荐系统。在本文的实验中相比于wide-only和deep-only的模型,wide & deep提升显著。下图是模型整体结构:
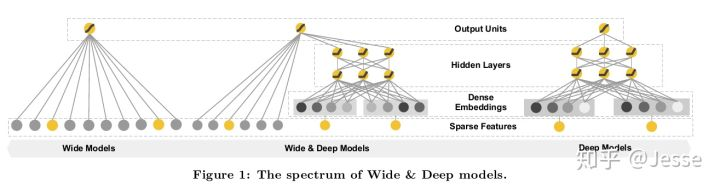
可以看出,Wide也是一种特殊的神经网络,他的输入直接和输出相连,属于广义线性模型的范畴。Deep就是指Deep Neural Network,这个很好理解。Wide Linear Model用于memorization;Deep Neural Network用于generalization。
左侧是Wide-only,右侧是Deep-only,中间是Wide & Deep。
2.2、Cross-product transformation
论文Wide中不断提到这样一种变换用来生成组合特征,这里很重要。它的定义如下:
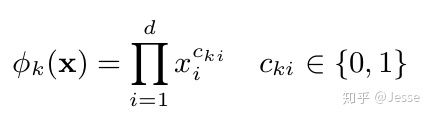
其中k表示第k个组合特征。i表示输入X的第i维特征。C_ki表示这个第i维度特征是否要参与第k个组合特征的构造。d表示输入X的维度。到底有哪些维度特征要参与构造组合特征,这个是人工设定的(这也就是说需要人工特征工程),在公式中没有体现。
其实这么一个复杂的公式,就是我们之前一直在说的one-hot之后的组合特征:仅仅在输入样本X中的特征gender=female和特征language=en同时为1,新的组合特征AND(gender=female, language=en)才为1。所以只要把两个特征的值相乘就可以了。
(这样Cross-product transformation 可以在二值特征中学习到组合特征,并且为模型增加非线性)
2.3、The Wide Component
如上面所说Wide Part其实是一个广义的线性模型。使用特征包括:
-
raw input: 原始特征
-
cross-product transformation :上面提到的组合特征
用同一个例子来说明:你给model一个query(你想吃的美食),model返回给你一个美食,然后你购买/消费了这个推荐。 也就是说,推荐系统其实要学习的是这样一个条件概率: P(consumption | query, item)。
Wide Part可以对一些特例进行memorization。比如AND(query=”fried chicken”, item=”chicken fried rice”)虽然从字符角度来看很接近,但是实际上完全不同的东西,那么Wide就可以记住这个组合是不好的,是一个特例,下次当你再点炸鸡的时候,就不会推荐给你鸡肉炒米饭了。
2.4、The Deep Component
如模型右边所示:Deep Part通过学习一个低纬度的dense representation(也叫做embedding vector)对于每一个query和item,来泛化给你推荐一些字符上看起来不那么相关,但是你可能也是需要的。比如说:你想要炸鸡,Embedding Space中,炸鸡和汉堡很接近,所以也会给你推荐汉堡。
Embedding vectors被随机初始化,并根据最终的loss来反向训练更新。这些低维度的dense embedding vectors被作为第一个隐藏层的输入。隐藏层的激活函数通常使用ReLU。
3、模型训练
训练中原始的稀疏特征,在两个组件中都会用到,比如query="fried chicken" item="chicken fried rice":
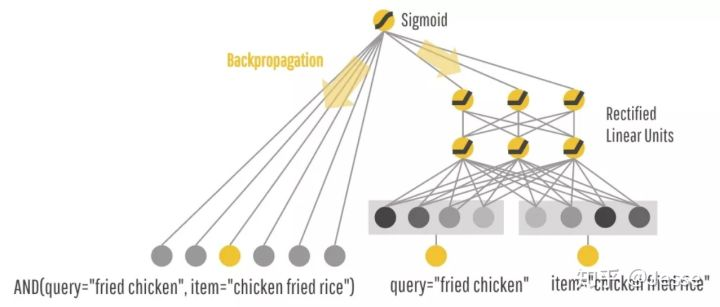
在训练的时候,根据最终的loss计算出gradient,反向传播到Wide和Deep两部分中,分别训练自己的参数。也就是说,两个模块是一起训练的(也就是论文中的联合训练),注意这不是模型融合。
-
Wide部分中的组合特征可以记住那些稀疏的,特定的rules
-
Deep部分通过Embedding来泛化推荐一些相似的items
Wide模块通过组合特征可以很效率的学习一些特定的组合,但是这也导致了他并不能学习到训练集中没有出现的组合特征。所幸,Deep模块弥补了这个缺点。
另外,因为是一起训练的,wide和deep的size都减小了。wide组件只需要填补deep组件的不足就行了,所以需要比较少的cross-product feature transformations,而不是full-size wide Model。
具体的训练方法和实验请参考原论文。
4、总结
缺点:Wide部分还是需要人工特征工程。
优点:实现了对memorization和generalization的统一建模。能同时学习低阶和高阶组合特征