第一次编程作业:论文查重。
一:GitHub链接:https://github.com/031804120/031804120
二:计算模块接口的设计与实现过程:
·总流程图:
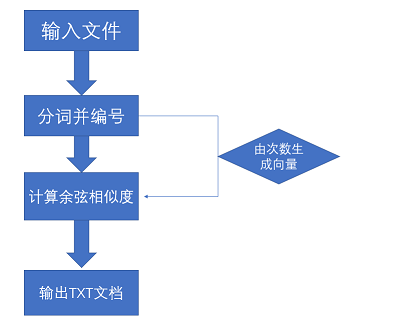
类和函数:
class Similarity():
`def vector(self):`
`def mix(self):`
`def mapminmax(vdict):`
`def similar(self):`
·实现过程:
大致的实现过程就是,先用open打开读取文件,然后再用jieba.analyse对文档进行分词,得到如['今天', '天气', '非常', ‘的’,'晴朗']的两个字符串数组。而后对得到的分词后的数组计算词频,得到相应的向量。再根据向量矩阵进行余弦相似度计算,从而得到文本相似度。
·算法的关键:
最主要的应该是余弦相似度的计算:
余弦相似度计算理论的主要的参考资料:http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
刚开始是因为好像大部分资料都调用了停词表文档,然后我也就按照调用外部文档的方式进行分词,然后一看要求,不行……那行吧,就得重新搞了。所以就用了基于VSM的余弦相似度计算,将代码差不多重新修整一遍了。
余弦计算文本相似度:
例句:
- 例句A:今天天气非常的晴朗。
- 例句B:今天天气格外的明媚。
第一步:分词。
A: 今天/天气/非常/的/晴朗。
B:今天/天气/格外/的/明媚。
第二步:列出所有的词、字,并计算词频
例句A:今天1,天气1,非常1,的1,晴朗1,格外0,明媚0。
例句B:今天1,天气1,格外1,的1,明媚1,非常0,晴朗0.
然后根据这个描述词频向量
第三步:计算夹角余弦
利用公式,我们可以得到,例句A与例句B的夹角的余弦。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫”余弦相似性”。
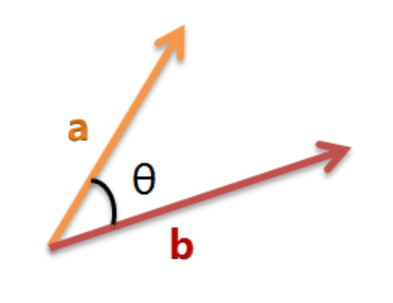
余弦定理:

假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:

余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:
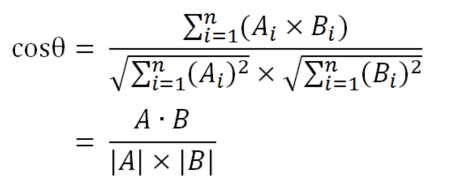
但同样的用这个方法也有需要注意的事项:
由于计算中打乱了关键词出现的顺序,所以即使夹角余弦的值为1,也有可能文本并不重复。
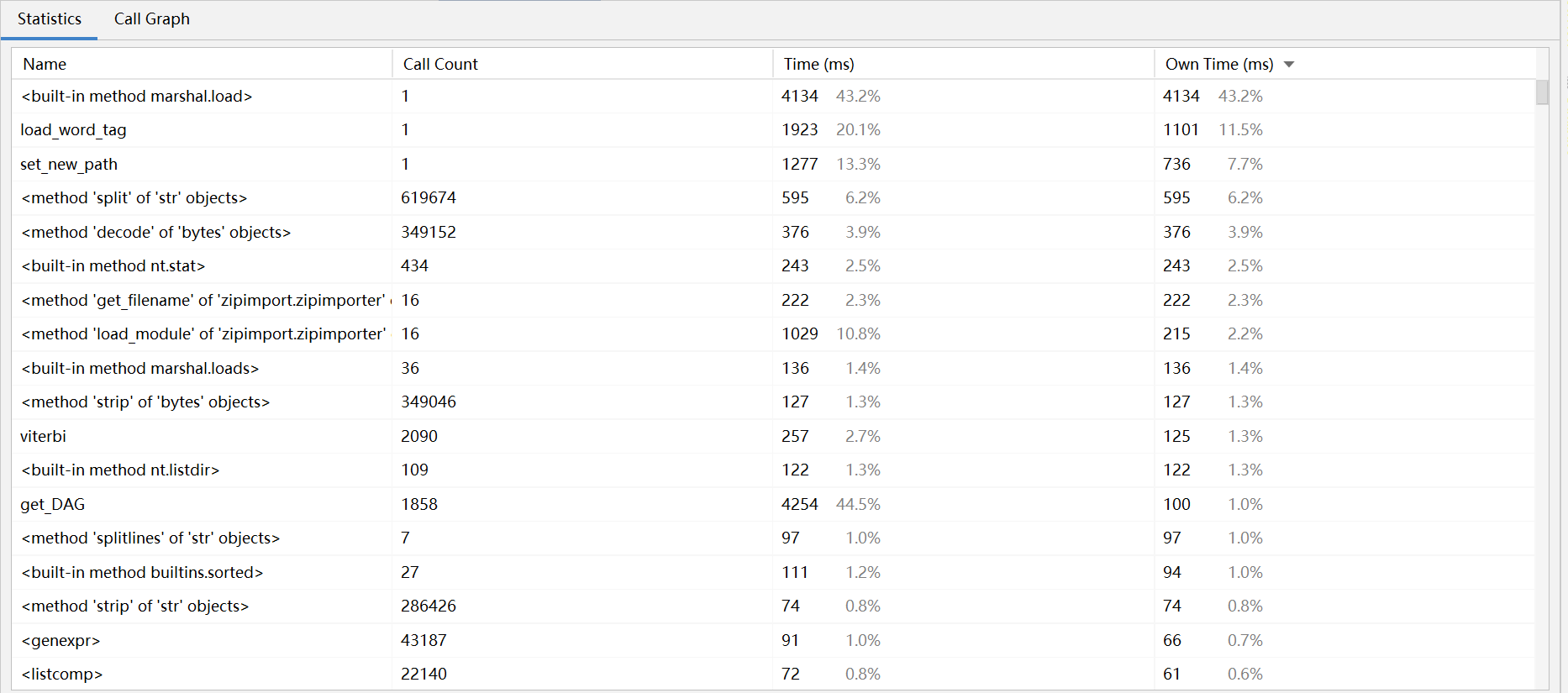
三:计算模块接口部分的性能改进:
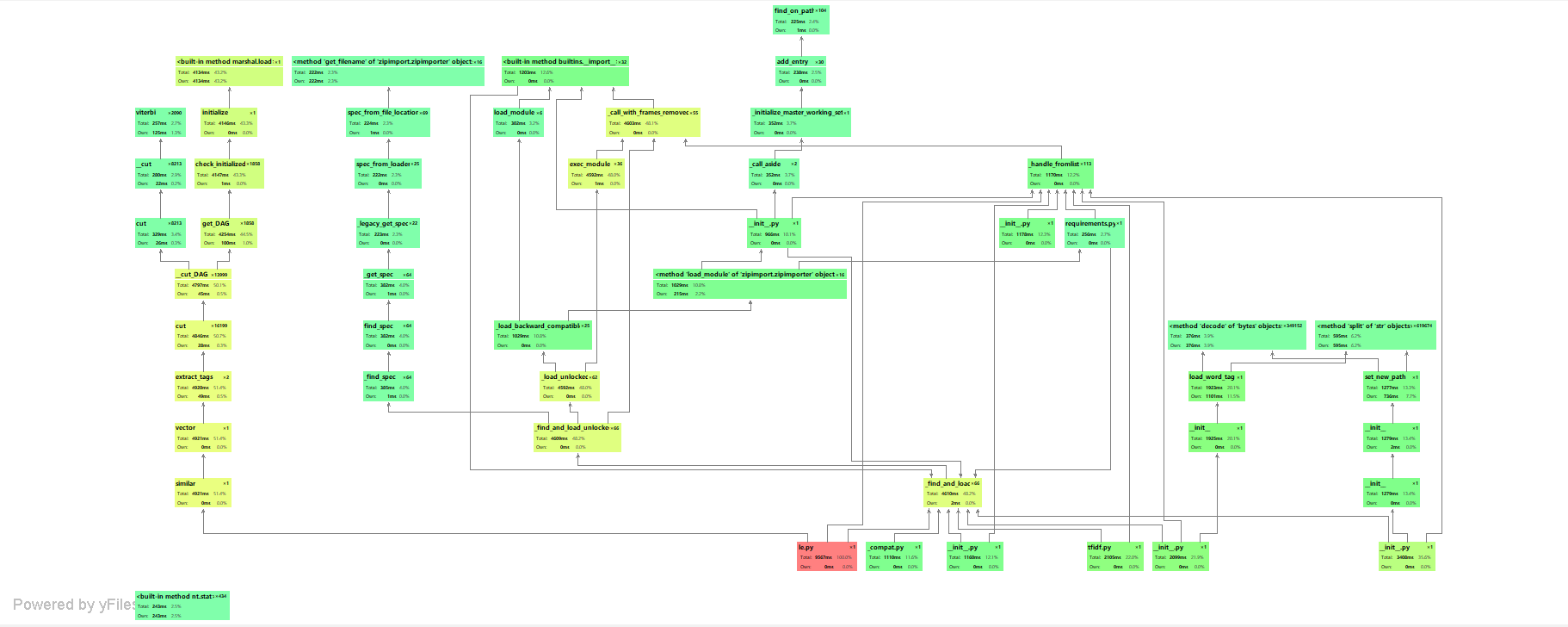
四:计算模块部分单元测试展示
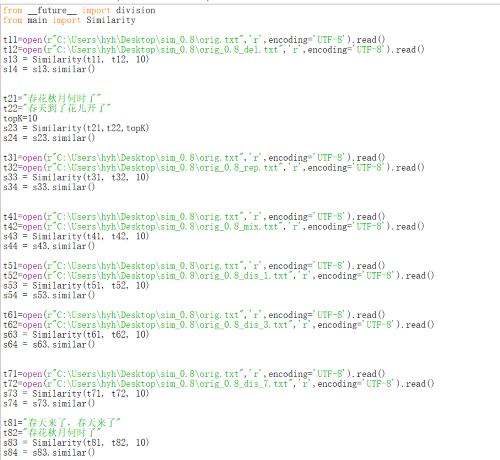
剩下的跟这个也差不多,就是文件名之类的改一下而已。
跑完后,得到的结果大概是这样的。

覆盖率的话,是这样的:
本来是用python自带的,后面换成pycharm,重新建file时名字错乱了(累得不想改了)。
unit_Test就是测试。

五:计算模块部分异常处理说明
异常处理:
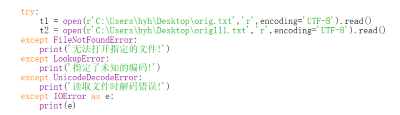
测试样例:
六:附录
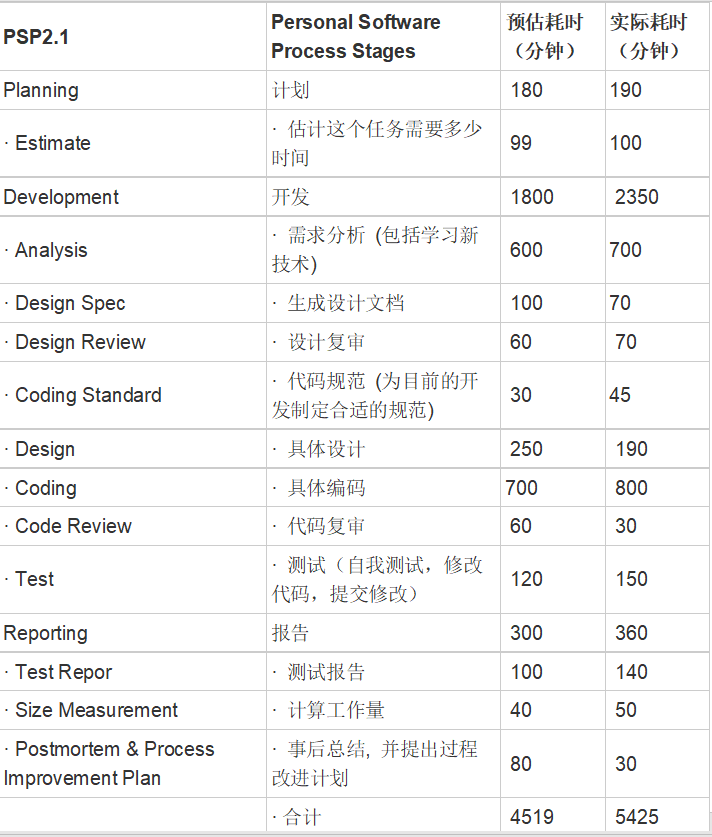
PSP:
七:总结
· 这次作业有难度啊,肝了好几个晚上啊。不过总体下来的收获应该还是可以的。