时间序列是按时间顺序的一组真实的数字,比如股票的交易数据。通过分析时间序列,能挖掘出这组序列背后包含的规律,从而有效地预测未来的数据。在这部分里,将讲述基于时间序列的常用统计方法。
1 用rolling方法计算移动平均值
当时间序列的样本数波动较大时,从中不大容易分析出未来的发展趋势的时候,可以使用移动平均法来消除随机波动的影响。可以说,移动平均法是针对时间序列的常用分析方法,其基本思想是,根据时间序列样本数据、逐步向后推移,依次计算指定窗口序列的平均值。
股票的移动平均线是个比较常见的范例,通过它可以分析未来股价的走势。从技术上来讲,可以通过pandas的rolling方法,以指定时间窗口的方式来计算移动均值,在如下的CalMA.py范例中,就将演示通过收盘价,演示通过rolling方法计算移动平均线的做法。
1 #coding=utf-8
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 filename='D:\work\data\ch9\6007852019-06-012020-01-31.csv'
5 df = pd.read_csv(filename,encoding='gbk',index_col=0)
6 fig = plt.figure()
7 ax = fig.add_subplot(111)
8 df['Close'].plot(color="green",label='收盘价')
9 df['Close'].rolling(window=5).mean().plot(color="red",label='5日均线')
10 plt.legend(loc='best') # 绘制图例
11 ax.grid(True) # 带网格线
12 plt.title("演示时间序列的移动平均线")
13 plt.rcParams['font.sans-serif']=['SimHei']
14 plt.setp(plt.gca().get_xticklabels(), rotation=30)
15 plt.show()在这个范例中,用到了matplotlib可视化控件,具体而言,在通过第5行的代码从csv文件得到数据后,先是通过第8行的plot方法,依次连接df对象里每天收盘价的点,从而绘制了描述“收盘价”的折线。
在第9行rolling方法里,通过window参数指定了移动分析的窗口是5天,再结合mean方法,绘制了基于收盘价的5天移动平均线。请注意在第8行和第9行绘制两条折线时,均通过label参数设置了图例,所以在之后的第10行里,能通过legend方法设置图例效果。
另外值得注意的可视化细节还有,在第11行里,通过grid方法设置了网格线,通过第12行和第13行的代码设置了中文标题,在第14行里指定了x轴坐标文字标签需要旋转30度。
运行上述代码,大家能看到如下图所示的效果。如果对比其中的收盘价和移动平均线,会发现后者平滑了许多,从中大家能感受到,基于时间序列的移动平均线能一定程度消除随机性的波动,能更有效地展示样本数据的波动趋势。
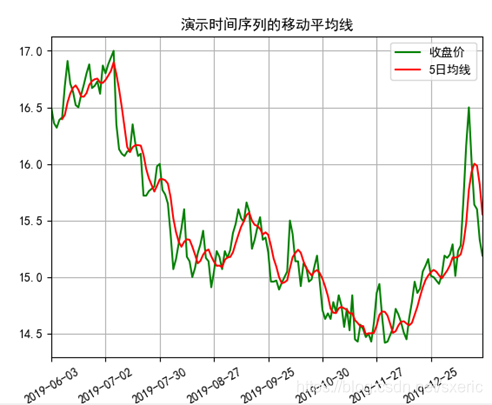
![]()
2 收盘价基于时间序列的自相关性分析
相关性是指两组数据间是否有关联,即一组数据的变动是否会影响到另一组数据。而自相关性,则是指同一个时间序列上两个不同点的变量间是否有关联。
这里还是拿股票收盘价举例,在这个场景里,自相关性是指两个交易日的收盘价之间是否有关联性。和相关性一样,自相关性同样是用-1到1的一个数来表示,其中0同样表示不相关,1同样表示完全相关,-1则表示完全反向相关。自相关性在统计学上有什么意义呢?
- 如果时间序列上,两个相近的值不相关,即相关系数为0,则表示该时间序列上的各个点间没有关联,那么就没有必要再通过观察规律来预测未来的数据。具体在股票收盘价案例上,如果本交易日收盘价和上个交易日收盘价间没有关联,那么就没必要再分析之前交易日的收盘价来预测未来交易日的收盘价。也就是说,只有当时间序列上不同点的值之间有相关性,才有必要分析过去的规律,以此来推算未来的值。
- 平稳序列的自相关系数应当很快会收敛(或叫衰减)到零。平稳序列是指,该时间序列里数据的变动规律会基本维持不变,这样才可以用从过去数据里分析出的规律来推算出未来的值。在股票收盘价案例中,当天收盘价可以和未来一周内的收盘价有关联,但在平稳序列里,当天收盘价和未来长远的(假设是50天)某天收盘价没关联。相反则说明任何一天收盘价的变动会影响很长一段时间,日积月累,那么在预测未来某天收盘价时还要考虑过去太多影响时间很长的规律,那么该时间序列的变动规律就会变得过于复杂,从而会导致不可测,
也就是说,针对一个时间序列,只有当该序列里相近时间的数据有关联,且间隔很长的数据间无关联,该序列才有被统计分析的意义。自相关性的算法不简单,不过可以通过statsmodels库里封装的方法来计算时间序列里的自相关性。
在使用这个库前,依然需要通过pip3 install statsmodels的命令来安装,作者安装的是当前最新的0.11.1版本。安装后,为了能正确使用,还需要安装mkl和scipy库。在如下的AcfDemo.py范例中,将通过股票收盘价的案例,让大家直观地感受到时间序列里的自相关性。
1 #coding=utf-8
2 import pandas as pd
3 import statsmodels.api as stats
4 filename='D:\work\data\ch9\6007852019-06-012020-01-31.csv'
5 df = pd.read_csv(filename,encoding='gbk',index_col=0)
6 stats.graphics.tsa.plot_acf(df['Close'],use_vlines=True,lags=50, title = 'ACF Demo')在第3行里,引入了计算自相关系数的statsmodels库,在第5行里,从指定的文件里读到股票收盘价的数据,并在第6行,通过stats.graphics.tsa.plot_acf方法来计算并绘制收盘价的相关性系数的图表。
该方法的use_vlines参数表示是否要设置点到x轴的连线,这里取值是True,表示需要设置,lags参数表示计算当天数据到后面50天的自相关系数,而title参数则表示该图表的标题。运行本范例,能看到如下图所示的效果。
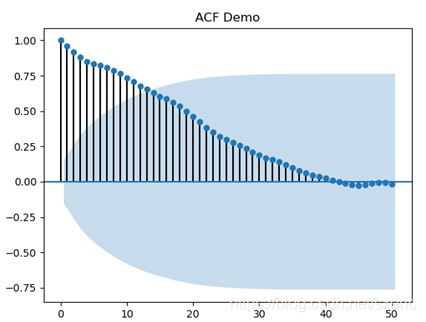
![]()
从上图中能看到,x轴的刻度从0到50,这和lags参数的取值相匹配,而y轴的刻度从-1到1,表示自相关性的系数。再进一步分析,从上图里能看出如下的统计方面的意义。
- x轴取值为0的自相关系数是1,表示当天数据和自身完全相关。
- x轴靠近0的一些自相关系数非常接近1,再如,第13天和第14天第15天的自相关系数相对差别不大,这说明当天收盘价对未来近期的收盘价有一定的影响。
- 随着x轴取值的变大,自相关系数是逐步衰减的,当在靠近40的位置基本衰减为0。这说明某天收盘价的变动不会对长远未来的数据有影响,进而说明该序列是平稳的。
- 除了描述自相关系数的点和线之外,还有描述95%置信区间的蓝色区域,从图上看出,13天的自相关系数约是0.7,同时落在了蓝色区域内。这表示第1天和第13天数据的自相关系数有95%的可信度,而之前没达到95%的可信度。之前没达到95%可信度的原因是,在本场景里的数据是从2019年6月1日开始的,实际场景里,该交易日的收盘价会受之前数据影响,但这里数据只从6月1日开始,所以就丢失了和之前数据的关联,从而导致可信度下降。
- 再观察落在95%置信区间里的第13、第14和第15天的自相关系数,它们的相对差别并不大。
综上所述得出的结论是,基于时间序列的该股收盘价,在比较短的周期内具有一定的自相关性,且可信度达到或高于95%,且该序列是平稳的,所以有分析该股收盘价序列的必要,从中得到的规律能一定程度上预测未来的走势。对于其它的时间序列,也可以照此步骤分析其自相关性,并能照此方式得出对应的结论。
3 收盘价基于时间序列的偏自相关性分析
从上例中可以看到,如果基于时间序列的数据具有自相关性,那么这种自相关性非常有可能会传递,即第n天的数据受第n-1天数据的影响,而第n-1天的数据受n-2天的影响,再以此类推,第n天的数据就有可能受之前若干数据的综合影响。具体到收盘价的案例,即当天收盘价不仅会受前一个交易日的影响,更会间接地受之前若干个交易日的影响。
在某些统计场景里,需要剔除更早数据的间接影响,只衡量之前数据对当前数据的直接影响,这就可以用到“偏自相关系数”。
“偏自相关系数”的计算过程相当复杂,根据算法,已经剔除其中自相关系数包含的“间接影响”,在实际应用中,也可以通过调用statsmodels库里的相关方法来实现,在如下的PacfDemo.py范例中,就将演示计算并绘制偏自相关系数的做法。
1 #coding=utf-8
2 import pandas as pd
3 import statsmodels.api as stats
4 filename='D:\work\data\ch9\6007852019-06-012020-01-31.csv'
5 df = pd.read_csv(filename,encoding='gbk',index_col=0)
6 stats.graphics.tsa.plot_pacf(df['Close'],use_vlines=True,lags=50, title = 'PACF Demo')本范例和之前求自相关性的范例很相似,差别是在第6行,调用了plot_pacf方法计算并绘制偏自相关系数,运行本范例,能看到如下图所示的效果。
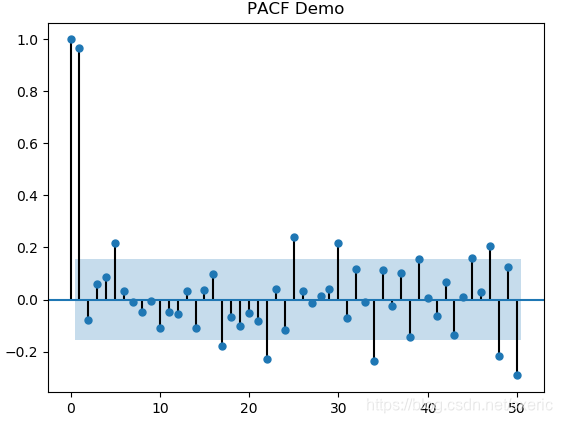
![]()
除去开始的两个数据,大多数数据落在蓝色的95%置信区间内,且偏自相关系数约在-0.15到0.15之间。这说明如果剔除更早交易日数据的影响,单纯看当天和后一个交易日的收盘价,它们的相关度约在0.15左右,这个结论有95%的可信度。再综合自相关系数,说明再预测未来的收盘价时,不能仅仅考虑前一个交易日的影响,还要引入更早交易日收盘价作为参考因素。
4 用热力图分析不同时间序列的相关性
之前是通过自相关系数和偏自相关系数来衡量单一时间序列里前后数据间的影响,在应用中,也会量化分析不同时间序列的相关性。
比如在制定股票的配对交易策略时,会量化计算不同股票收盘价之间的相关性,如果它们的正向相关性强,则说明它们的走势规律非常相似。在本小节里,会以热力图的形式,向大家展示如下表所示的股票收盘价之间的的相关性。
表 分析相关性的股票信息一览表
|
股票代码 |
股票名称 |
所属板块 |
|
603005 |
晶方科技 |
半导体 |
|
600360 |
华微电子 |
半导体 |
|
600640 |
号百控股 |
互联网传媒 |
在如下CompareCorrByHeatMap.py范例中,将首先从网络接口里抓取指定股票的数据,在此基础上计算股票间的相关度,并以热力图的形式直观地展示不同时间序列间相关性的效果。
1 #coding=utf-8
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 import pandas_datareader
5 # 603005 晶方科技 半导体
6 # 600360 华微电子 半导体
7 # 600640 号百控股 互联网传媒
8 stockCodes = ['603005', '600360', '600640']
9 start='2019-12-01'
10 end='2020-01-31'
11 stockCloseDF = pd.DataFrame()
12 for code in stockCodes:
13 thisClose = pandas_datareader.get_data_yahoo(code + '.ss', start, end)
14 stockCloseDF[code] = thisClose['Close'].values
15 #print(stockCloseDF) #可以观察结果
16 fig = plt.figure()
17 ax = fig.add_subplot(111)
18 ax.set_xticklabels(stockCodes)
19 ax.set_xticks(range(len(stockCodes)))
20 ax.set_yticklabels(stockCodes)
21 ax.set_yticks(range(len(stockCodes)))
22 im = ax.imshow(stockCloseDF.corr(), cmap=plt.cm.hot_r)
23 # 添加颜色刻度条
24 plt.colorbar(im)
25 # 添加中文标题
26 plt.rcParams['font.sans-serif']=['SimHei']
27 plt.title("用热力图观察股票间的相关性")
28 plt.xlabel('股票代码')
29 plt.ylabel('股票代码')
30 plt.show()在第8行的stockCodes变量里,定义了待分析的股票代码,这些股票的具体信息请参考第5行到第7行的注释,同时在第9行和第10行的代码里,定义待分析股票的开始和结束日期。
随后在第12行到第14行的for循环里,依次遍历股票代码,并从网络接口得到对应的数据,并在第14行把三个股票的收盘价放入DataFrame类型的stockCloseDF对象里。至此完成数据的准备工作,大家也可以打开第15行的注释,通过print语句观察结果。
在得到数据后,会在第22行和第24行的代码里,两两计算各股间的相关性,并绘制成热力图,并在右边显示图例性质的颜色刻度条。运行本范例,能看到如下图所示的效果。
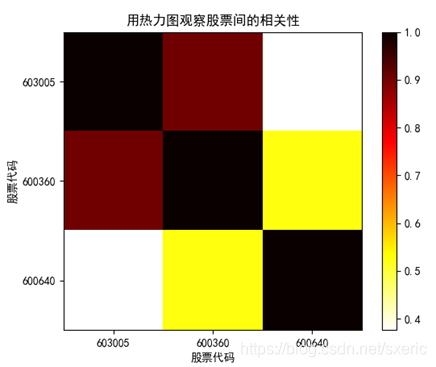
![]()
从上图里能看到,x轴和y轴刻度都是股票代码,两两比对后,自身的相关性都是1,而603005(晶方科技)和600360(华微电子)均属于半导体板块,所以它们间的相关性比较高,而600640(号百控股)属于互联网传媒板块,所以它和其它两个股票的相关性就很低。
本文出自我写的书: Python爬虫、数据分析与可视化:工具详解与案例实战,https://item.jd.com/10023983398756.html

![]()
请大家关注我的公众号:一起进步,一起挣钱,在本公众号里,会有很多精彩文章。

![]()