MyCAT是一个开源的分布式数据库组件,在项目里,一般用这个组件实现针对数据库的分库分表功能,从而提升对数据表,尤其是大数据库表的访问性能。而且在实际项目里,MyCAT分库分表组件一般会和MySQL以及Redis组件整合使用,这样就能从“降低数据表里数据量规模”和“缓存数据”这两个维度提升对数据的访问性能。
1 分库分表概述
先通过一个实例来看下分库分表的概念,比如在某电商系统里,存在一张主键为id的流水表,如果该电商系统的业务量很大,这张流水表很有可能达到“亿”级规模,甚至更大。如果要从这张表里查询数据,哪怕用到索引等数据库优化的措施,但毕竟数据表的规模太大,这会成为性能上的瓶颈,所以可以按如下的思路拆分这张大的流水表。
1 在不同的10个数据库,同时创建这10张流水表,这些表的表结构完全一致。
2 在1号数据库里,只存放id%10等于1的流水记录,比如存放id是1、11和21等的流水记录,在2号数据库里只存放id%10等于2的流水记录,以此类推。
也就是说,通过上述步骤,能把这张流水表拆分成10个字表,而MyCAT组件能把应用程序对流水表的请求分散到10张子表里,具体的效果下图所示。

在实际项目里,子表的个数可以根据实际需求来设置。由于把大表的数据分散到若干张子表里,所以每次数据请求所面对的数据总量能有效降低,从中大家能感受到“分表”做法对提升数据库访问性能的帮助。
并且在实际项目里,会尽量把子表分散创建到不同的主机上,而不是单纯地在同一台主机同一个数据库上创建多个子表,也就是说,需要尽量把这些子表分散到不同的数据库上,具体效果如下图所示。

尽量对子表进行“分库”还是出于提升性能的考虑。由于单台数据库处理请求时总会有性能瓶颈,比如每秒最多能处理500个请求。如果把这些子表放在同一台主机的同一个数据库上,那么对该表的请求速度依然无法突破单台数据库的性能瓶颈。但如果把这些子表分散到不同主机的不同数据库上,那么对该表的请求就相当于被有效分摊到不同的数据库上,这样就能成n倍地提升数据库的有效负载。
在实际项目里,出于成本上的考虑,或许无法为每个子表分配一台主机,在这种情况下可以退而求其次,可以把不同的子表分散创建在同一主机的不同数据库上,总之尽量别在同一主机同一数据库上创建不同的子表。
也就是说,通过“分表”,能有效降低大表的数据规模,通过“分库”,能整合多个数据库,从而能提升处理请求的有效负载。而MyCAT分布式数据库组件,实现这种“分库分表”的效果,所以通常就把它叫做“MyCAT分库分表组件”。
事实上,MyCAT组件能解析SQL语句,并根据预先设置好的分库字段和分库规则,把该SQL发送到对应的子表上执行,再把执行好的结果再返回给应用程序。
2 用MyCAT组件实现分库分表
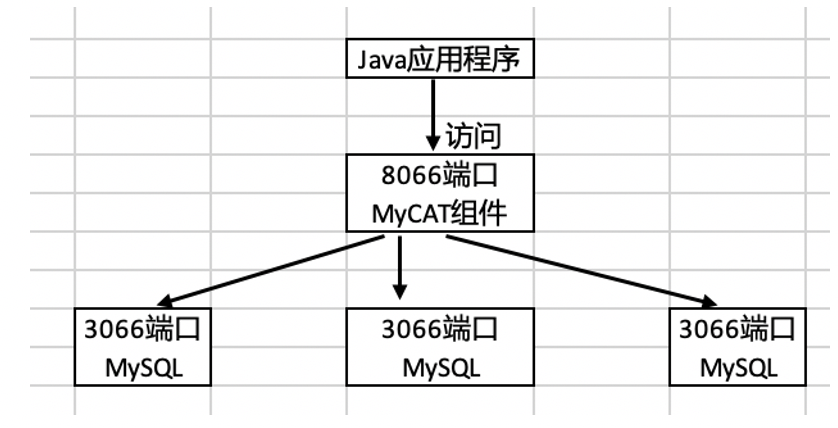
在上文里已经提到,用MyCAT可以实现分库分表的效果,该组件默认工作在8066端口,它和应用程序以及数据库的关系如下图所示。从中大家可以看到,Java应用程序不是直接和MySQL等数据库互连,而是和MyCAT组件连接。应用程序是把SQL请求发送到MyCAT,而MyCAT根据配置好的分库分表规则,把请求发送到对应的数据库上,得到请求再返回给应用程序。
为了实现分库分表的效果,一般需要配置MyCAT组件里如下表所示的三个文件。

这里将以一个MyCAT组件连接三个数据库为例,具体给出上述三个配置文件的编写范例。
第一,server.xml配置文件的代码如下所示。
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE mycat:server SYSTEM "server.dtd"> 3 <mycat:server xmlns:mycat="http://io.mycat/"> 4 <system> 5 <property name="serverPort">8066</property> 6 <property name="managerPort">9066</property> 7 </system> 8 <user name="root"> 9 <property name="password">123456</property> 10 <property name="schemas">redisDemo</property> 11 </user> 12 </mycat:server>
在第5行和第6行里,分别配置了该MyCAT组件的工作端口和管理端口为8066和9066,在第8行到第11行的代码里,配置了连接该MyCAT组件的用户名是root,连接密码是123456,同时,该root登录后,可以访问MyCAT组件里的redisDemo数据库。
请注意这里redisDemo是MyCAT组件的数据库,而不是MySQL里的,在实践过程中,这个数据库一般和MySQL里的同名。
第二,schema.xml配置文件的代码如下所示。
1 <?xml version="1.0"?> 2 <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> 3 <mycat:schema xmlns:mycat="http://io.mycat/"> 4 <schema name="redisDemo"> 5 <table name="student" dataNode="dn1,dn2,dn3" rule="mod-long"/> 6 </schema> 7 <dataNode name="dn1" dataHost="host1" database="redisDemo" /> 8 <dataNode name="dn2" dataHost="host2" database="redisDemo" /> 9 <dataNode name="dn3" dataHost="host3" database="redisDemo" /> 10 <dataHost name="host1" dbType="mysql" maxCon="10" minCon="3" balance="0" writeType="0" dbDriver="native"> 11 <heartbeat>select user()</heartbeat> 12 <writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="123456"></writeHost> 13 </dataHost> 14 <dataHost name="host2" dbType="mysql" maxCon="10" minCon="3" balance="0" writeType="0" dbDriver="native"> 15 <heartbeat>select user()</heartbeat> 16 <writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="123456"></writeHost> 17 </dataHost> 18 <dataHost name="host3" dbType="mysql" maxCon="10" minCon="3" balance="0" writeType="0" dbDriver="native"> 19 <heartbeat>select user()</heartbeat> 20 <writeHost host="hostM3" url="172.17.0.4:3306" user="root" password="123456"></writeHost> 21 </dataHost> 22 </mycat:schema>
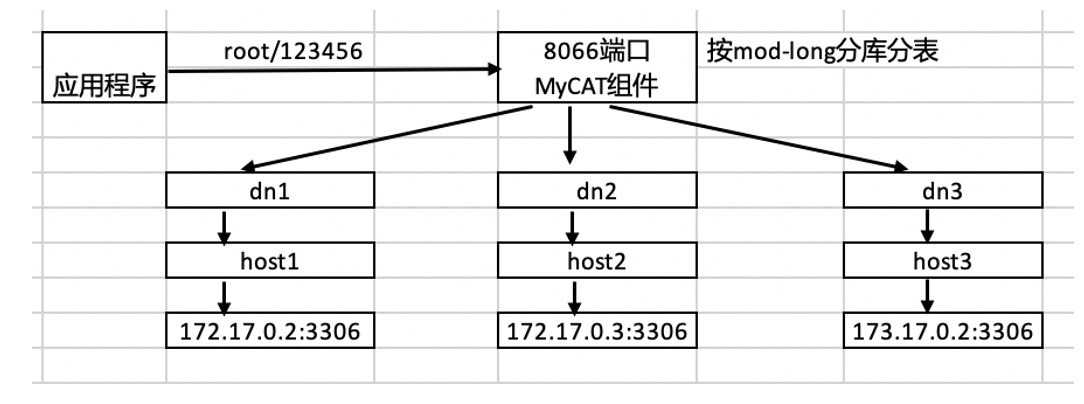
在第4行到第6行里,定义了redisDemo数据库里的student表,将按照mod-long规则,分布到dn1,dn2,dn3这三个数据库节点上。随后在第7行到第9行的代码里,给出了dn1,dn2,dn3这三个节点的定义,它们分别指向host1,host2和host3的redisDemo数据库。
在第10行到第21行的代码里,给出了针对host1到host3的定义,它们的配置很相似,这里就以第10行到第13行的host1配置来说明。
在第10里,首先通过dbType参数,定义了host1是mysql类型的数据库,随后通过maxCon和minCon参数指定了该host数据库的最大和最小连接数,通过balance和writeType参数,指定了向host1读写的请求,其实是发送到第12行定义的,url是172.17.0.2:3306的mysql数据库,同时在第12行里,还指定了连到172.17.0.2:3306的mysql数据库的用户名和密码。在第11行定义的heartbeat参数,则定义了MyCAT组件用select user()这句sql语句来判断host1这个数据库能否处于“连接”状态。也就是说,在第5行定义的dn1节点,最终是指向172.17.0.2:3306所在的MySQL数据库的stduent表。
类似的在第14行到第21行针对host2和host3的定义里,分别也定义里这两个数据库的具体url地址。也就是说,定义在第4行的redisDemo数据库里的student表,根据dataNode的定义,最终会分散到172.17.0.2:3306、172.17.0.3:3306和172.17.0.4:3306这三个redisDemo数据库里的stduent表里。
通过下图,大家能更清晰地看到通过配置文件里相关参数定义的分库关系。
在本范例中,是用Docker容器在同一台主机里创建三个MySQL实例,所以172.17.0.2:3306、172.17.0.3:3306和172.17.0.4:3306是本机三个Docker容器的地址。如果在项目里,是在多台主机上部署MySQL服务器,那么对应的地址就应该修改成这些主机的IP地址。
第三,rule.xml配置文件的代码如下所示。
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> 3 <mycat:rule xmlns:mycat="http://io.mycat/"> 4 <tableRule name="mod-long"> 5 <rule> 6 <columns>id</columns> 7 <algorithm>mod-long</algorithm> 8 </rule> 9 </tableRule> 10 11 <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> 12 <property name="count">3</property> 13 </function> 14 </mycat:rule>
在第4行里定义了mod-long这个规则,该规则在schema.xml第5行里被用到,再结合第11行到第13行的代码,能看到利用该规则对student表分库时,将先对id进行模3处理,然后再根据取模后的结果,到host1到host3所在的数据表的student库里进行处理。这里取模的数值3,是需要和MySQL主机的数量相同。
上述三个配置文件综合起来,给出了如下针对分库分表相关动作的定义。
1. 应用程序如果如果要使用MyCAT,需要用root用户名外带123456密码连接到该MyCAT组件。
2. 比如要插入id为1的stduent数据,根据在schema.xml里的定义,会先根据mod-long规则,对id进行模3处理,结果是1,所以会插入到host2所定义的172.17.0.3:3306数据库的student表里,如果要进行读取、删除和更新操作,也会先对id模3,然后再把该请求发送到对应的数据库里。
这里仅给出了MyCAT分库的一种比较常用的规则(即取模),也只是把stduent表分散到3个物理数据表里,事实上通过编写配置,可以用其它算法,让MyCAT组件把数据表分散到更多的子表里。
3 Java、MySQL与MyCAT的整合范例
这里将以“一个MyCAT组件连接三个MySQL数据库,对student表进行分库”的需求为例,结合上文给出的MyCAT三个配置文件,给出基于Docker容器设置MyCAT分库分表的详细步骤,并在此基础上,给出Java应用程序连接MyCAT以实现分库分表的代码范例。
步骤一,先通过如下3个Docker命令,准备3个包含MySQL的Docker容器。
1 docker run -itd -p 3306:3306 --name mysqlHost1 -e MYSQL_ROOT_PASSWORD=123456 mysql:latest 2 docker run -itd -p 3316:3306 --name mysqlHost2 -e MYSQL_ROOT_PASSWORD=123456 mysql:latest 3 docker run -itd -p 3326:3306 --name mysqlHost3 -e MYSQL_ROOT_PASSWORD=123456 mysql:latest
这里创建的三个MySQL的docker容器分别叫mysqlHost1、mysqlHost2和mysqlHost3,在容器里它们都工作在3306端口,但它们分别映射到主机的3306、3316和3326端口。并且,通过-e参数,分别指定了这三个数据库root用户名的密码是123456。
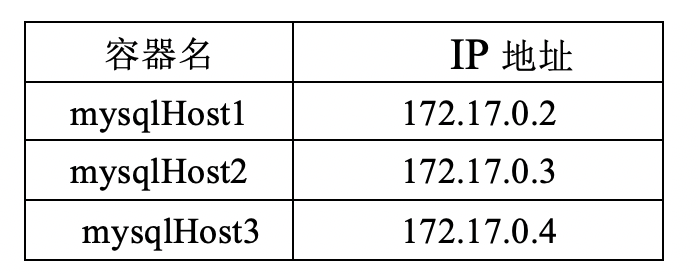
创建完成后,再分别通过如下的命令,观察它们所在docker容器的ip地址。
1 docker inspect mysqlHost1 2 docker inspect mysqlHost2 3 docker inspect mysqlHost3
观察到的IP地址如下表所示,大家在自己电脑上操作时,如果看到的是其它的IP地址,就需要更改下文步骤里的相关配置项。
步骤二,通过docker exec -it mysqlHost1 /bin/bash命令进入到mysqlHost1容器,随后再用mysql -u root -p命令进入到mysql数据库,进入时需要输入的密码是123456,随后运行如下的命令创建redisDemo数据库和student表。
1 create database redisDemo; 2 use redisDemo; 3 create table student( id int not null primary key,name char(20),age int,score float);
其中第1行语句是用于建库,第2行语句是进入redisDemo库,第3行语句是用于建表。
完成后,通过docker exec -it mysqlHost2 /bin/bash和docker exec -it mysqlHost3 /bin/bash这两条命令进入到另外两个MySQL容器里,也通过mysql命令进入到数据库,也再通过上述语句进行创建数据库和数据表的动作。至 此完成了针对三个MySQL数据库的创建动作。
步骤三,通过docker pull命令下载mycat组件的镜像,如果无法下载,则可以通过docker search mycat命令寻找可用的镜像并下载。
步骤四,新建C:workmycatconf目录,在其中放入在10.2.2部分里给出的针对MyCAT组件的server.xml、rule.xml和schema.xml这三个配置文件。
其中在schema.xml里,针对数据库url的定义如下第3行、第7行和第11所示。请注意它们指向的是具体Docker容器里的MySQL的IP地址,它们的值需要和表10.3里给出的值一致。如果大家用docker inspect命令观察到三个Docker的地址有变,就需要对应第修改schema.xml里的url值。
1 <dataHost name="host1" dbType="mysql" maxCon="10" minCon="3" balance="0" writeType="0" dbDriver="native"> 2 <heartbeat>select user()</heartbeat> 3 <writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="123456"></writeHost> 4 </dataHost> 5 <dataHost name="host2" dbType="mysql" maxCon="10" minCon="3" balance="0" writeType="0" dbDriver="native"> 6 <heartbeat>select user()</heartbeat> 7 <writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="123456"></writeHost> 8 </dataHost> 9 <dataHost name="host3" dbType="mysql" maxCon="10" minCon="3" balance="0" writeType="0" dbDriver="native"> 10 <heartbeat>select user()</heartbeat> 11 <writeHost host="hostM3" url="172.17.0.4:3306" user="root" password="123456"></writeHost> 12 </dataHost>
步骤五,再确保上述三个Docker里包含的My SQL都处于可用状态后,通过如下的Docker命令启动MyCAT对应的docker容器。
1 docker run --name mycat -p 8066:8066 -p 9066:9066 -v C:workmycatconfserver.xml:/opt/mycat/conf/server.xml:ro -v C:workmycatconfschema.xml:/opt/mycat/conf/schema.xml:ro -v C:workmycatconf ule.xml:/opt/mycat/conf/rule.xml:ro -d mycat:latest
请注意该docker命令的如下要点。
1 通过-p参数,把该MyCAT组件的工作端口8066和管理端口9066映射到主机里的同名端口。
2 通过三个-v参数,把容器外C:workmycatconf目录里的三个MyCAT配置文件映射到容器内的/opt/mycat/conf/目录里,这样启动时,就能读到这三个配置文件。这样做的前提是,事先已经确认过容器内的server.xml等三个配置文件存在于/opt/mycat/conf/目录里,如果有些mycat镜像里的这三个配置文件不存在于这个目录,则可以先用docker exec -it mycat /bin/bash命令进入该mycat容器,找到这三个配置文件对应的位置后,再改写上述启动mycat容器的docker run命令。
3 通过mycat:latest参数指定该容器是基于mycat:latest镜像生成的。
运行完上述docker run命令后,可以通过docker logs mycat命令观察包含在该容器内的MyCAT组件的启动日志。如果成功启动,就能看到日志里有如下图10.12所示的提示成功的信息。如果有错误,那么或者去检查三个MySQL数据库的连接状态,或者根据日志里给出的错误提示来排查问题。

至此完成了MyCAT组件和三个MySQL数据库的相关配置,在如下的MyCATSimpleDemo范例中,将给出Java程序通过MyCAT组件向MySQL数据库插入数据的做法,从中大家能感受到分库分表的效果。
1 import java.sql.*; 2 public class MyCATSimpleDemo { 3 public static void main(String[] args){ 4 //定义连接对象和PreparedStatement对象 5 Connection myCATConn = null; 6 PreparedStatement ps = null; 7 //定义连接信息 8 String mySQLDriver = "com.mysql.jdbc.Driver"; 9 String myCATUrl = "jdbc:mysql://localhost:8066/redisDemo"; 10 String user = "root"; 11 String pwd = "123456"; 12 try{ 13 Class.forName(mySQLDriver); 14 myCATConn = DriverManager.getConnection(myCATUrl, user, pwd); 15 ps = myCATConn.prepareStatement("insert into student (id,name,age,score) values (?,'test',18,100)"); 16 ps.setString(1,"11"); 17 ps.addBatch(); 18 ps.setString(1,"12"); 19 ps.addBatch(); 20 ps.setString(1,"13"); 21 ps.addBatch(); 22 ps.executeBatch(); 23 } catch (SQLException se) { 24 se.printStackTrace(); 25 } catch (Exception e) { 26 e.printStackTrace(); 27 } 28 finally{ 29 //如果有必要,释放资源 30 if(ps != null){ 31 try { 32 ps.close(); 33 } catch (SQLException e) { 34 e.printStackTrace(); 35 } 36 } 37 if(myCATConn != null){ 38 try { 39 myCATConn.close(); 40 } catch (SQLException e) { 41 e.printStackTrace(); 42 } 43 } 44 } 45 } 46 }
在本范例的第14行里,创建了指向MyCAT组件的连接对象myCATConn,请注意它是指向localhost的8066端口,用root和123456连接到redisDemo数据库,这和在server.xml里的配置相吻合。在随后的第15行里,是用myCATConn创建PreparedStatement类型的ps对象,并在第16行到第21行的代码里,通过addBatch方法批量组装了三条insert语句,请注意它们的id分别是11、12和13,最后在第22行的代码里,通过executeBatch语句执行了这三条insert语句。
从中大家可以看到,通过MyCAT连接对象执行SQL语句的方式和直接用MySQL连接对象的方式基本相同,而且在获取MyCAT连接对象时,只需要对应地更改连接url即可。也就是说,MyCAT组件在实现分库分表时,对应用程序来说是透明的,它完全分离了“数据操作的业务动作”和“数据操作的底层实现”,所以如果要在一个系统里引入MyCAT分库分表组件,修改的点非常有限,对原有业务的影响并不大。
再来看下分库分表的效果,通过docker exec -it mysqlHost1 /bin/bash命令进入到mysqlHost1容器,随后再用mysql -u root -p命令进入到mysql数据库,用use redisDemo;命令进入到redisDemo数据库后,执行select * from student;命令,只能看到一条数据,如下图所示。

同样地,在mysqlHost2和mysqlHost3所在的数据库里,也只能看到一条数据,这三个数据库里存储的student数据如下表所示。
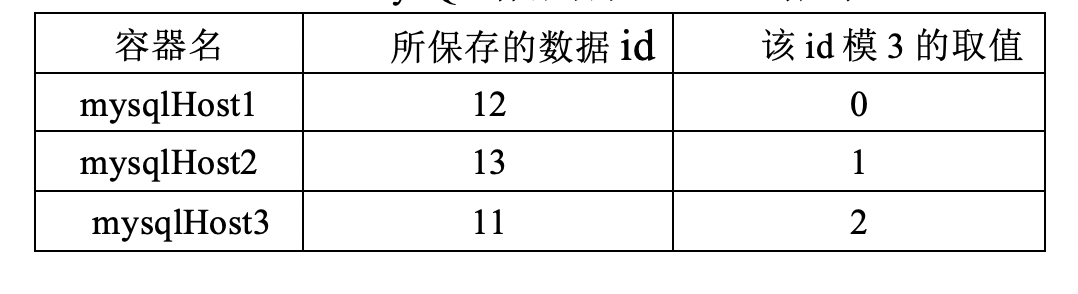
从中大家可以看到,根据id模3取值的不同,MyCAT组件分别把它们分散到了3个数据库里。由于本书的重点是Redis,所以就不再给出用MyCAT组件进行删除、更新和查询操作的相关范例,不过如果大家用上述范例中的myCATConn连接对象以及用它生成的ps对象,实现相关操作的效果也不难。
这里student表中的数据规模很小,其实无法体现出分库分表的优势,但如果这张表的规模很大,比如达到百万级甚至更高,那么通过MyCat组件引入分库分表效果后,就相当于把针对这张大表的压力均摊到了若干张子表上,就能更好地应对高并发的场景。