1. HashMap
标准链地址法实现(下图)。数组方式存储key/value,线程非安全,允许null作为key和value,key不可以重复,value允许重复,不保证元素迭代顺序是按照插入时的顺序,key的hash值是先计算key的hashcode值,然后再进行计算,每次容量扩容会重新计算所以key的hash值,会消耗资源,要求key必须重写equals和hashcode方法。默认初始容量16,加载因子0.75,扩容为旧容量乘2,查找元素快,如果key一样则比较value,如果value不一样,则按照链表结构存储value。如果需要同步,可以用 Collections的synchronizedMap方法(Map m = Collections.synchronizedMap(new HashMap(…));)。使HashMap具有同步的能力,或者使用ConcurrentHashMap。
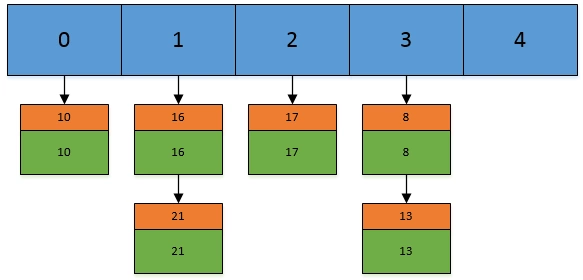
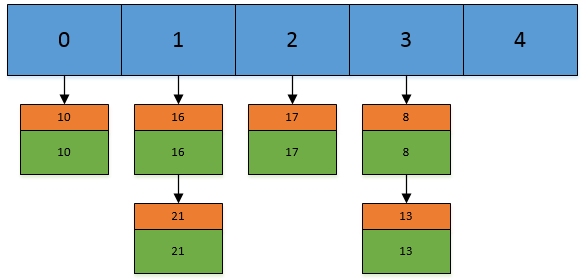
JDK 1.8之后,加入了static final int TREEIFY_THRESHOLD = 8;,当同一桶内元素个数超过8个,就会将链表结构进行树化。
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;2. HashTable
线程安全,不允许有null的键和值,线程安全的,它在所有涉及到多线程操作的都加上了synchronized关键字来锁住整个table,这就意味着所有的线程都在竞争一把锁,在多线程的环境下,它是安全的,但是无疑是效率低下的。
3. ConcurrentHashMap
HashTable有很多的优化空间,锁住整个table这么粗暴的方法可以变相的柔和点,比如在多线程的环境下,对不同的数据集进行操作时其实根本就不需要去竞争一个锁,因为他们不同hash值,不会因为rehash造成线程不安全,所以互不影响,这就是锁分离技术,将锁的粒度降低,利用多个锁来控制多个小的table,这就是ConcurrentHashMap JDK1.7版本的核心思想。
JDK1.7的实现
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
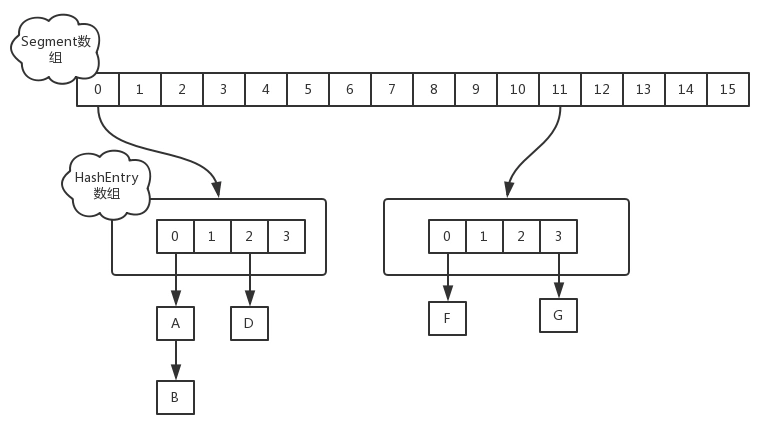

Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
JDK1.8的实现
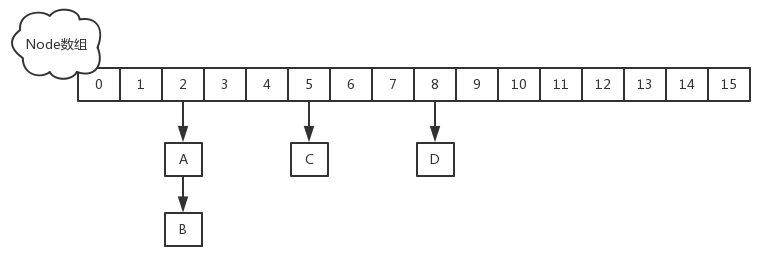
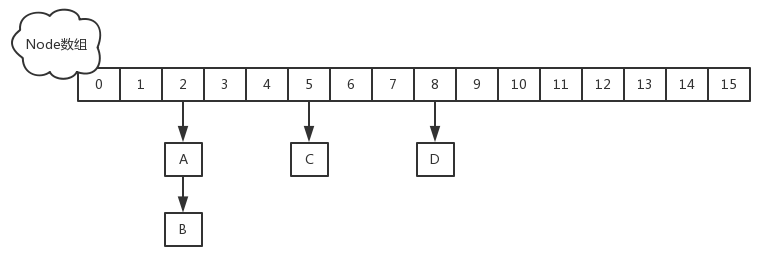
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
4. TreeMap
TreeMap实现SortMap接口,基于红黑二叉树的NavigableMap的实现,线程非安全,不允许null,key不可以重复,value允许重复,存入TreeMap的元素应当实现Comparable接口或者实现Comparator接口,会按照排序后的顺序迭代元素,两个相比较的key不得抛出classCastException。主要用于存入元素的时候对元素进行自动排序,迭代输出的时候就按排序顺序输出
5. LinkedHashMap
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
6. WeakHashMap
WeakHashMap,从名字可以看出它是某种 Map,允许null作为key和value(Both null values and the null key are supported.),非线程安全(this class is not synchronized)。它的特殊之处在于 WeakHashMap 里的entry可能会被GC自动删除,即使程序员没有调用remove()或者clear()方法。
更直观的说,当使用 WeakHashMap 时,即使没有显示的添加或删除任何元素,也可能发生如下情况:
- 调用两次
size()方法返回不同的值;- 两次调用
isEmpty()方法,第一次返回false,第二次返回true;- 两次调用
containsKey()方法,第一次返回true,第二次返回false,尽管两次使用的是同一个key;- 两次调用
get()方法,第一次返回一个value,第二次返回null,尽管两次使用的是同一个对象。
WeekHashMap的这个特点特别适用于需要缓存的场景。在缓存场景下,由于内存是有限的,不能缓存所有对象;对象缓存命中可以提高系统效率,但缓存MISS也不会造成错误,因为可以通过计算重新得到。
要明白WeekHashMap的工作原理,还需要引入一个概念:弱引用(WeakReference)。Java中内存是通过GC自动管理的,GC会在程序运行过程中自动判断哪些对象是可以被回收的,并在合适的时机进行内存释放。GC判断某个对象是否可被回收的依据是,是否有有效的引用指向该对象。如果没有有效引用指向该对象(基本意味着不存在访问该对象的方式),那么该对象就是可回收的。这里的“有效引用”并不包括弱引用。也就是说,虽然弱引用可以用来访问对象,但进行垃圾回收时弱引用并不会被考虑在内,仅有弱引用指向的对象仍然会被GC回收。
WeakHashMap内部是通过弱引用来管理entry的,弱引用的特性对应到WeakHashMap上意味:将一对key, value放入到WeakHashMap里并不能避免该key值被GC回收,除非在WeakHashMap之外还有对该key的强引用。