https://blog.csdn.net/amao1998/article/details/80366286

#encoding=utf-8
import jieba
import jieba.posseg as pseg
import re
filename='result.txt'
fileneedCut='./in_the_name_of_people.txt'
fn=open(fileneedCut,"r",encoding='UTF-8')
f=open(filename,"w+",encoding='UTF-8')
for line in fn.readlines():
words=jieba.cut(line)
words=' '.join(words)
for w in words:
f.write(w)
f.close()
fn.close()
import multiprocessing from gensim.models import Word2Vec from gensim.models.word2vec import LineSentence vocab = 'result.txt' model = Word2Vec(LineSentence(vocab), size=32, window=5, min_count=5,workers=multiprocessing.cpu_count())

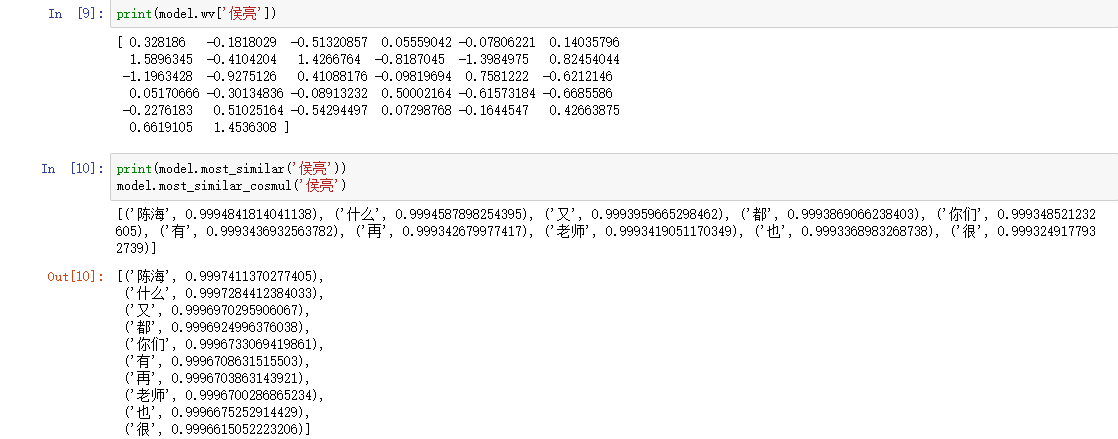
https://blog.csdn.net/zl_best/article/details/53433072
jieba分词原理:https://blog.csdn.net/baidu_33718858/article/details/81073093(较难理解)
