作业描述
| 作业描述 | 链接 |
|---|---|
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W |
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W/homework/2688 |
| 结对学号 | 221600131、221600439 |
| 作业目标 | 实现一个能够对文本文件中的单词的词频进行统计的控制台程序。 |
GitHub
基础需求:https://github.com/temporaryforfzuse/PairProject1-C
进阶需求:https://github.com/temporaryforfzuse/PairProject2-C
分工
221600131:WordCount基础、测试数据构造、爬虫、附加题
221600439:WordCount主体
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| - Estimate | 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | ||
| - Analysis | 需求分析 (包括学习新技术) | 30(学习新技术被计入具体编码部分) | 240 |
| - Design Spec | 生成设计文档 | 10 | 10 |
| - Design Review | 设计复审 | 10 | 10 |
| - Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 0 | |
| - Design | 具体设计 | 10 | |
| - Coding | 具体编码 | 240 | 660 |
| - Code Review | 代码复审 | 贯穿代码开发过程,不作为单独流程 | 0 |
| - Test | 测试(自我测试,修改代码,提交修改) | 贯穿代码开发过程,不作为单独流程 | 0 |
| Reporting | 报告 | 30 | 30 |
| - Test Report | 测试报告 | 30 | 30 |
| - Size Measurement | 计算工作量 | 5 | 5 |
| - Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 370 | 1020 |
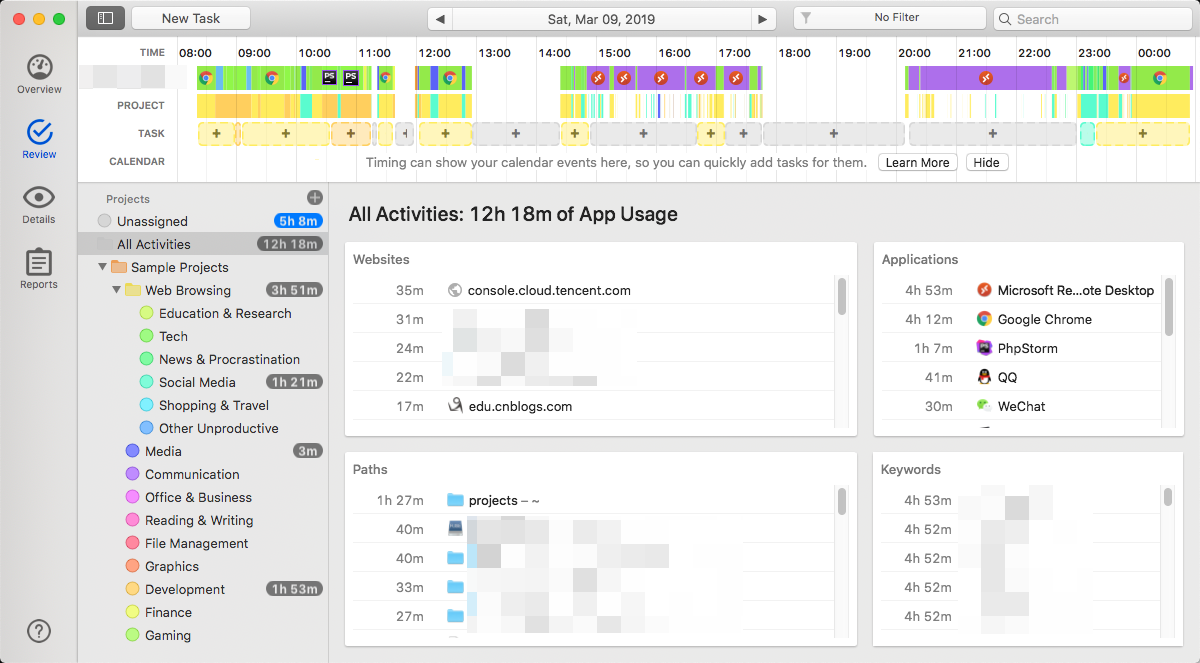
如截图。因不明原因助教只使用Windows评测C++,必须使用远程桌面开发。此处即为计时。可以注意到,因为需求严重不明确,本身周末就搞定了的项目,不得不在工作日进行大量修改。
“时间总能挤在重写上的。”
遇到的困难及解决方法
结对本身不存在困难,合作非常愉快。
221600131 被评价为:思维活跃、创新能力强,学习热情高,非常认真。熟练掌握 Python 语言,擅长数据挖掘。
221600439 被评价为:代码能力强,工程能力强,有较强的Bug查找能力。
困难
需求极度不明确。
解决
硬写啊。
解题思路描述
公共部分
划分一个DLL和一个MainProject。考虑到今后可能会被其他语言调用,暴露出的接口必须为C式,那么就不能以C++ STL结构作为输入或输出,必须自己构造struct。同时需要考虑内存回收,谁初始化的内存,谁负责清理。
考虑作业需求,只需要读一次就够了,具体行为由DLL内部自行处理,返回数据的处理让外部调用者来做。因此,DLL内暴露2个API:
extern "C" __declspec(dllexport) WordCountResult CalculateWordCount(const char * fileName);
extern "C" __declspec(dllexport) void ClearWordAppear(WordCountResult * resultStruct);
基础需求
解题思路描述 / 设计实现过程
没什么好思考的,一个大循环就写完了……仅需一个函数,一百行不到的算法就能解决的事情,硬要把它拆成三四个部分完全是over design。
优化思路
本算法时间复杂度肯定是O(n)(n为字符数量)的,其中使用的HashMap读取的时间复杂度为O(1),排序算法时间复杂度为O(nlgn)(n为单词数量)。慢应当慢在I/O上和STL上。
初步实现是直接逐字节读文件。以下为对4400万的规律数据进行测试,用时4.296秒。
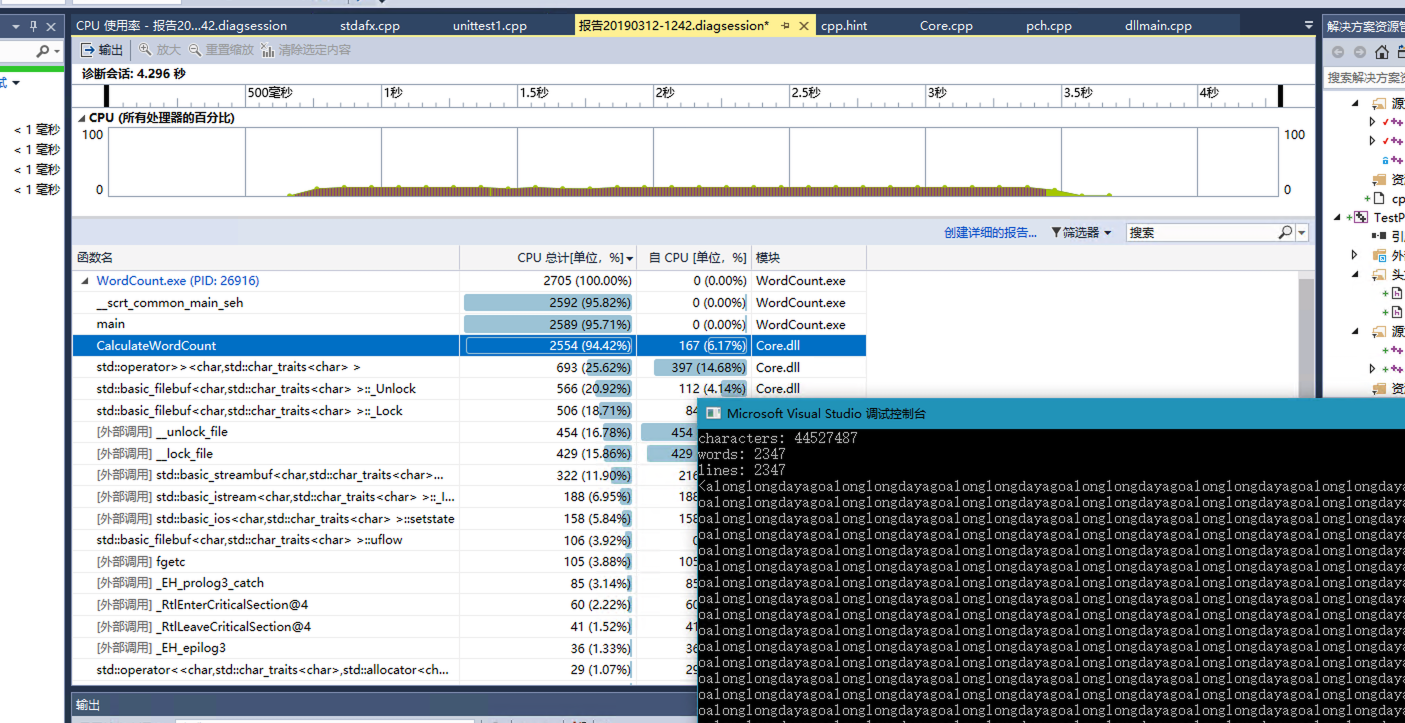
这种做法可能较慢,因为I/O次数较大。性能优化方法是把文件读到内存Buffer里,再从Buffer里逐字节取出。将其改为stringstream后,优化至3秒。

观察性能得知,最慢的代码在此处。相信只要弃用stringstream而直接从内存数组取数据,性能就能更高。同时因std::map使用红黑树而非HashMap,更换为HashMap还可以更加优化性能。

换成C式读写,并将std::map换成std::unordered_map后,仅需0.3秒。此处性能低在:单词出现次数排序上、HashMap的增查、内存比较,基本可认为无继续优化的必要。
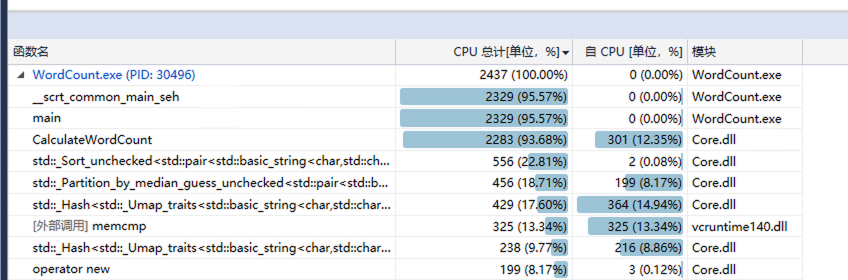
接下来还需要优化的话,重点在于内存占用上。目前因文件是一次读入,且需要在内存内记录所有单词,导致可能需要3倍于文件大小的内存,因此大文件也需要编译为64位才可处理。对此可增加I/O,例如一次只读入100M文件。至于内存中的单词计数,暂时还没有比较好的解决方案。
当前对一个大约760M的文本文件进行了测试,4字节长的单词约有70万个,耗时37秒。
测试脚本
测试数据以及脚本:https://files.cnblogs.com/files/aaaaaaaaaaaaaa/结对2测试数据.rar
我认为,一个合理的测试方式是:
- GitHub 加一个tests文件夹,里面存放测试数据。
- GitHub 加一个TestProject,作为测试工程,丢在Repo里。
- GitHub 加一个
.travis.yml或appveyor.yml,自动构建并自动测试。
但此次作业完全没有提到CI的重要性,且不允许一并提交测试数据。 我直接使用脚本来处理而非而非使用VS的单元测试工程,原因即在于不允许提交测试工程。另外,我个人认为,一个好的测试,如非必要,不应与外界环境耦合。这一点我的测试并不佳。与其说它是单元测试,更应该说它是回归测试 。
代码覆盖率测试仅 Visual Studio Enterprise 有,免费的 Community 无。由于我日常并不进行Windows开发,不再花费时间找各类工具/破解版。
const testCaseDir = 'cases-1/'
const testCaseCount = 11
const cp = require('child_process')
const fs = require('fs')
const path = require('path')
for (let i = 1; i <= testCaseCount; i++) {
const randomFileName = (Math.random() * 10000000000 + new Date().getTime()).toString(16)
const inFileName = path.resolve(__dirname, `${testCaseDir}input${i}.txt`)
const outFileName = path.resolve(__dirname, `${testCaseDir}result${i}.txt`)
const stdout = cp.execSync(`"D:\Projects\Homework\fzuse-hw3\221600131&221600439\src\x64\Release\WordCount.exe" ${inFileName}`).toString('utf-8')
if (fs.existsSync(outFileName)) {
const fout = fs.readFileSync(outFileName, 'utf-8')
if (stdout.trim() !== fout.trim()) {
console.log(`Failed at ${i}`)
console.log(`=== Excepted ====`)
console.log(fout)
console.log(`=== Actual ====`)
console.log(stdout)
} else {
console.log(`OK at ${i}`)
}
} else {
fs.writeFileSync(outFileName, stdout, 'utf-8')
}
}
构造测试数据的思路
- 特殊符号
- 边界条件
- 如何定义一个单词?举例,
aaaa是,0aaaa不是,a0aa不是,a|aa不是,aaaa0是。 - 如何定义一行?
- 如何定义空白字符?
- 如何定义一个单词?举例,
基本思想就是在各处if周边试探,写各种可能让if出错的edge case。把这些处理清楚,测试数据就写完了。部分测试数据如图。
关键代码
配合注释,基本做到代码自解释。
EXTERN WordCountResult CalculateWordCount(const char * fileName)
{
auto ret = WordCountResult();
bool runStateMachine = true;
char c = 0;
std::ifstream file(fileName);
std::string word = ""; // 不想做动态分配内存,std::string省事
size_t wordLength = 0; // <= wordAtLeastCharacterCount,超过则不再计数
bool isValidWordStart = true;
bool hasNotBlankCharacter = false;
auto map = std::unordered_map<std::string, size_t>();
FILE* f;
if (fopen_s(&f, fileName, "rb") != 0) {
ret.errorCode = WORDCOUNTRESULT_OPEN_FILE_FAILED;
return ret;
}
fseek(f, 0, SEEK_END);
long fileLength = ftell(f);
fseek(f, 0, SEEK_SET);
char * string = (char*)malloc(fileLength + 1);
fread(string, fileLength, 1, f);
fclose(f);
string[fileLength] = 0;
size_t currentPosition = 0;
while (runStateMachine) {
c = string[currentPosition];
if (currentPosition == fileLength) {
runStateMachine = false; // 文件读取结束,不立即退出,处理一下之前未整理干净的状态
c = 0;
}
else {
currentPosition++;
if (c == '
') continue; // Thanks God
ret.characters++;
}
if (c >= 'A' && c <= 'Z') {
c = c - 'A' + 'a';
}
if (!isEmptyChar(c)) {
hasNotBlankCharacter = true;
}
if (isCharacter(c)) {
if (isLetter(c)) {
// 判断一下首几个字母是不是字母,不是的话就不是单词
if ((wordLength > 0 && wordLength < wordAtLeastCharacterCount) || (wordLength == 0 && isValidWordStart)) {
if (isAlphabet(c)) {
word += c;
wordLength++;
}
else {
isValidWordStart = false;
word = "";
wordLength = 0;
}
}
else {
word += c;
}
}
}
if (!isLetter(c)) {
if (wordLength >= wordAtLeastCharacterCount) { // 不是数字字母了,就可能是个单词的结束
if (map.find(word) == map.end()) {
map[word] = 0;
ret.uniqueWords++;
}
map[word]++;
ret.words++;
}
word = "";
wordLength = 0;
if (isSeparator(c)) { // 只有有分隔符分割的,才是一个单词的开始
isValidWordStart = true;
}
}
if (isLf(c) || !runStateMachine) {
if (hasNotBlankCharacter) { // 任何包含非空白字符的行,都需要统计。
ret.lines++;
}
hasNotBlankCharacter = false;
}
}
auto sortedMap = std::vector<WordCountPair>(map.begin(), map.end());
std::sort(sortedMap.begin(), sortedMap.end(), [](const WordCountPair& lhs, const WordCountPair& rhs) noexcept {
if (lhs.second == rhs.second) {
return lhs.first < rhs.first;
}
return lhs.second > rhs.second;
});
ret.wordAppears = new WordCountWordAppear[ret.uniqueWords];
size_t i = 0;
for (auto &it : sortedMap) {
ret.wordAppears[i].word = new char[it.first.length() + 1];
strcpy_s(ret.wordAppears[i].word, it.first.length() + 1, it.first.c_str());
ret.wordAppears[i].count = it.second;
i++;
}
free(string);
return ret;
}
进阶需求
爬虫
解题思路描述 / 设计实现过程
爬虫选用的是python语言,因为请求库和解析库有很多而且方便。我这里主要用的是Request请求库和BeautifulSoup + lxml解析库。由于这部分只要求爬取title和abstract部分,所以首先分析前端html发现这两个部分的div都有很明显的id标志,所以直接通过xpath定位到这两个div取出text即可。第一遍常规套路爬一遍耗时超过十分钟。
性能优化
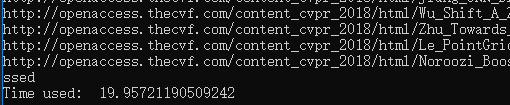
因为总共将近一千篇论文爬一遍耗时太久了,所以我使用多进程爬虫以使性能得到提升。我们知道在python下多进程更好,因为每个进程有独立的GIL,互不干扰,可以真正意义上实现并行执行。而python多线程下,每个线程执行方式是获取GIL,执行代码直到sleep或是虚拟机将其挂起,最后释放GIL。而每次释放GIL后线程都会进行锁的竞争,切换线程,从而造成资源的消耗。所以我这里选择用多进程爬虫。
修改代码后开到32进程再次测试,爬取一遍不用20秒。
WordCount
解题思路描述 / 设计实现过程
先是命令行处理。这一点,直接用库即可。我选用CLI11,避免重复造轮子。
这题更好的解法是正则表达式。应当用正则的理由如下:
- 我写的这种自动机难以维护,需要提前预知所有状态,一旦添加状态就要检查状态有无遗漏。
- 状态机对于数据的封闭不利,需要共享数据。
- 如果我的理解没问题,进阶需求没有特殊字符。
我不用正则表达式的原因如下:
- 需求不明确,不知道要改几次需求。比调正则相对好调些。
既然不用正则表达式,那就直接一个状态机解决了。词法分析、语法分析、语义分析全部忽略,直接使用最简单的状态转换算法,连词法带语义一起处理。
至于找资料..找啥?
图
核心仅一个函数,画类图有点强人所难。状态转换图如下:
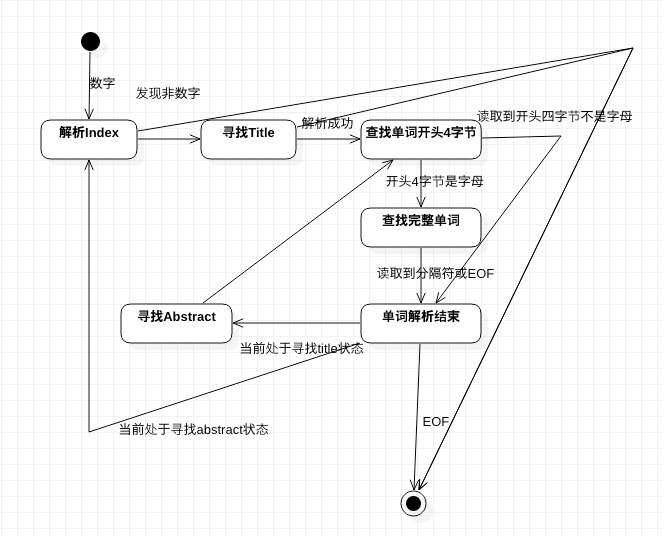
性能优化
和基础类似,不再赘述。

单元测试
分 C++ 内部测试与 Nodejs 外部测试两个部分。使用Nodejs测试的原因是,不方便将测试数据进行PR,更不方便把它丢到 C++ 代码内部。
C++部分的部分测试:
TEST_METHOD(TestPharse)
{
auto config = WordCountConfig();
config.statByPharse = true;
config.pharseSize = 3;
config.useDifferentWeight = false;
auto out = doTest("0
Title: Monday Tuesday Wednesday Thursday
Abstract: Friday", &config);
Assert::AreEqual(out.characters, (size_t)40);
Assert::AreEqual(out.words, (size_t)5);
Assert::AreEqual(out.lines, (size_t)2);
Assert::AreEqual(out.uniqueWordsOrPharses, (size_t)2);
Assert::AreEqual(out.wordAppears[0].word, "monday tuesday wednesday");
Assert::AreEqual(out.wordAppears[0].count, (size_t)1);
Assert::AreEqual(out.wordAppears[1].word, "tuesday wednesday thursday");
Assert::AreEqual(out.wordAppears[1].count, (size_t)1);
ClearWordAppear(&out);
}
Nodejs部分的测试:
const testCaseDir = 'cases-2/'
const testCaseCount = 7
const cp = require('child_process')
const fs = require('fs')
const path = require('path')
for (let i = 1; i <= testCaseCount; i++) {
const randomFileName = (Math.random() * 10000000000 + new Date().getTime()).toString(16) + '.txt'
const inFileName = path.resolve(__dirname, `${testCaseDir}input${i}.txt`)
const argFileName = path.resolve(__dirname, `${testCaseDir}arg${i}.txt`)
const outFileName = path.resolve(__dirname, `${testCaseDir}result${i}.txt`)
const arg = fs.readFileSync(argFileName, 'utf-8')
cp.execSync(`"D:\Projects\Homework\fzuse-hw3-2\221600131&221600439\src\Debug\WordCount.exe" -i ${inFileName} -o ${randomFileName} ${arg}`)
const stdout = fs.readFileSync(randomFileName, 'utf-8')
if (fs.existsSync(outFileName)) {
const fout = fs.readFileSync(outFileName, 'utf-8')
if (stdout.trim() !== fout.trim()) {
console.log(`Failed at ${i}`)
console.log(`=== Excepted ====`)
console.log(fout)
console.log(`=== Actual ====`)
console.log(stdout)
} else {
console.log(`OK at ${i}`)
}
} else {
fs.writeFileSync(outFileName, stdout, 'utf-8')
}
fs.unlinkSync(randomFileName)
}
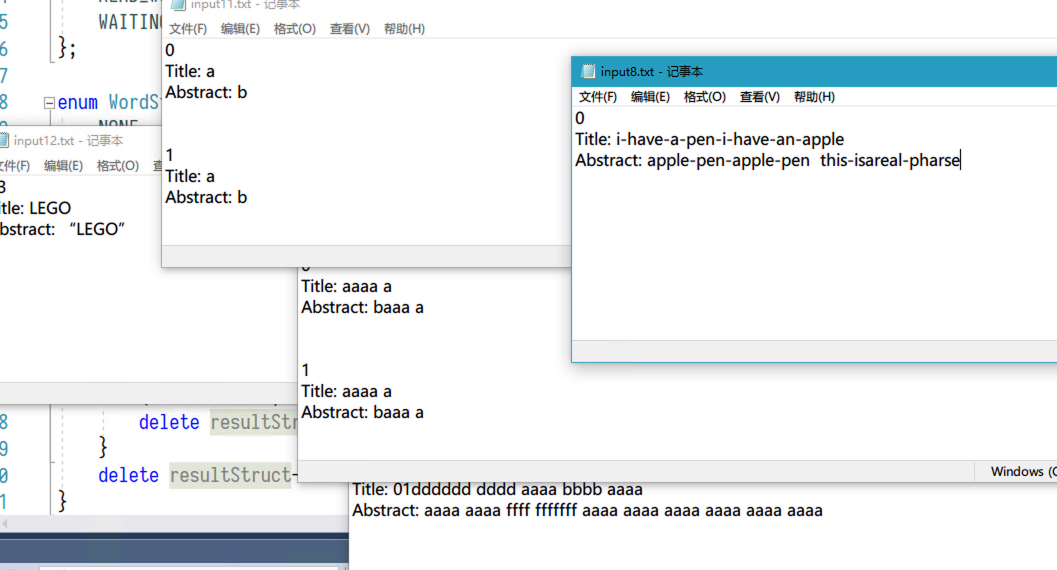
部分测试如图:
核心算法
需要搭配状态转换图查看,注释数量尚可。
EXTERN WordCountResult CalculateWordCount(struct WordCountConfig config)
{
auto ret = WordCountResult();
bool runStateMachine = true;
char prev = 0, c = 0;
std::string word = ""; // 不想做动态分配内存,std::string省事
std::string separator = "";
std::string token = "";
size_t wordLength = 0; // <= wordAtLeastCharacterCount,超过则不再计数
auto map = std::unordered_map<std::string, size_t>();
bool isValidWordStart = false;
FILE* f;
if (fopen_s(&f, config.in, "rb") != 0) {
ret.errorCode = WORDCOUNTRESULT_OPEN_FILE_FAILED;
return ret;
}
fseek(f, 0, SEEK_END);
long fileLength = ftell(f);
fseek(f, 0, SEEK_SET);
char * string = (char*)malloc(fileLength + 1);
fread(string, fileLength, 1, f);
fclose(f);
string[fileLength] = 0;
ReadingStatus currentStatus = ALREADY;
WordStatus wordStatus = NONE;
std::list<WordInPharse> pharse;
size_t currentPosition = 0;
while (runStateMachine) {
prev = c;
c = string[currentPosition];
if (currentPosition == fileLength) {
runStateMachine = false; // 文件读取结束,不立即退出,处理一下之前未整理干净的状态
c = 0;
}
else {
currentPosition++;
}
if (c >= 'A' && c <= 'Z') {
c = c - 'A' + 'a';
}
bool switchStatusInCurrentToken = true;
// 直接把read token和parse做在一起,就不拆开了
while (switchStatusInCurrentToken) {
switchStatusInCurrentToken = false;
// 避免这个大switch的方法是把这个状态转换写成一个类
// 不过没啥必要,不考虑后续维护
switch (currentStatus) {
case ALREADY:
if (isNumber(c)) {
currentStatus = READING_PAPER_INDEX;
switchStatusInCurrentToken = true;
continue;
}
// else if (isEmptyChar(c)) { // 正常, do nothing
// }
else { // @TODO: 此处要抛错
}
break;
case READING_PAPER_INDEX:
if (isNumber(c)) {
token += c;
}
else if (isEmptyChar(c)) { // 编号读完,状态转换开始
token = ""; // 这个编号数据没啥用,我也不知道读了干啥
currentStatus = WAITING_FOR_TITLE;
}
else { // @TODO: 此处要抛错
}
break;
case WAITING_FOR_TITLE:
if (isEmptyChar(c) && c != ':') { // 可能是还没读完Title,也可能是已经读完了
if (token == "title:") { // 读完了
isValidWordStart = true;
currentStatus = FINDING_WORD_START;
wordStatus = TITLE;
token = "";
}
else { // @TODO: 此处要抛错
}
}
else {
token += c; // 暂不判断title:是否完全正确,假设其规范;之后加入错误提示
}
break;
case WAITING_FOR_ABSTRACT:
if (isEmptyChar(c) && c != ':') { // 同title
if (token == "abstract:") { // 读完了
isValidWordStart = true;
currentStatus = FINDING_WORD_START;
wordStatus = ABSTRACT;
token = "";
}
else { // @TODO: 此处要抛错
}
}
else {
token += c;
}
break;
case FINDING_WORD_START:
if (isLetter(c)) {
if (wordLength == 0) {
separator = token;
token = "";
}
// 后半部分判断是为了处理01abcdefg这种情况
if ((wordLength > 0 && wordLength < wordAtLeastCharacterCount) || (wordLength == 0 && isValidWordStart)) {
if (isAlphabet(c)) {
wordLength++;
if (wordLength == wordAtLeastCharacterCount) {
currentStatus = READ_WORD;
switchStatusInCurrentToken = true;
}
else {
ret.characters++;
word += c;
}
continue;
}
}
}
if (config.statByPharse) {// 单词长度不达标则清空词组
if (wordLength > 0) {
pharse.clear();
}
}
isValidWordStart = false;
word = "";
wordLength = 0;
currentStatus = READ_WORD_END;
switchStatusInCurrentToken = true;
continue;
break;
case READ_WORD: // 确定已经是单词了,继续搞
if (isLetter(c)) { // 仍然是字母的情况下,继续读
word += c;
ret.characters++; // 非单词的情况下字符统计交给READ_WORD_END
}
else { // 不是字母了,开始处理剩下的了
currentStatus = READ_WORD_END;
switchStatusInCurrentToken = true;
continue;
}
break;
case READ_WORD_END:
if (word != "") {
ret.words++; // 这个时候就能确定读到了一个完整的单词了
if (config.statByPharse) {
pharse.push_back(WordInPharse{
word = word,
separator = separator
});
if (pharse.size() == config.pharseSize) {
auto pharseString = getPharse(pharse);
if (map.find(pharseString) == map.end()) {
map[pharseString] = 0;
ret.uniqueWordsOrPharses++;
}
if (config.useDifferentWeight) {
if (wordStatus == TITLE) {
map[pharseString] += titleWeight;
}
else {
map[pharseString] += 1;
}
}
else {
map[pharseString]++;
}
pharse.pop_front();
}
}
else {
// 略微重复代码,建议抽象成宏
if (map.find(word) == map.end()) {
map[word] = 0;
ret.uniqueWordsOrPharses++;
}
if (config.useDifferentWeight) {
if (wordStatus == TITLE) {
map[word] += titleWeight;
}
else {
map[word] += 1;
}
}
else {
map[word]++;
}
}
isValidWordStart = false;
}
word = "";
wordLength = 0;
if (isLf(c) || !runStateMachine) { // 如果是个换行符,就可以切换状态是读TITLE还是读ABSTRACT了
ret.lines++;
pharse.clear();
token = "";
if (wordStatus == TITLE) {
currentStatus = WAITING_FOR_ABSTRACT;
}
else {
currentStatus = ALREADY;
}
if (isLf(c)) {
ret.characters++;
}
}
else { // 单词处理完成了,该等新的单词了。
if (!isValidWordStart) {
if (isSeparator(c)) {
isValidWordStart = true;
token += c;
}
}
if (isCharacter(c)) {
ret.characters++;
}
currentStatus = FINDING_WORD_START;
}
break;
}
}
}
auto sortedMap = std::vector<WordCountPair>(map.begin(), map.end());
std::sort(sortedMap.begin(), sortedMap.end(), [](const WordCountPair& lhs, const WordCountPair& rhs) {
if (lhs.second == rhs.second) {
return lhs.first < rhs.first;
}
return lhs.second > rhs.second;
});
ret.wordAppears = new WordCountWordAppear[ret.uniqueWordsOrPharses];
size_t i = 0;
for (auto &it : sortedMap) {
ret.wordAppears[i].word = new char[it.first.length() + 1];
strcpy_s(ret.wordAppears[i].word, it.first.length() + 1, it.first.c_str());
ret.wordAppears[i].count = it.second;
i++;
}
return ret;
}
附加题
解题思路描述 / 设计实现过程
要进行数据分析首先得有足够的数据集。所以我将前面的爬虫程序进行改进,将CVPR官网上有用的信息都爬取下来。我这里是通过Request获取前端代码分析时发现底部有个神奇的bibref类,里面存放了很多信息,甚至还有没展示的属性,比如月份。通过观察这些信息的结构都一样。
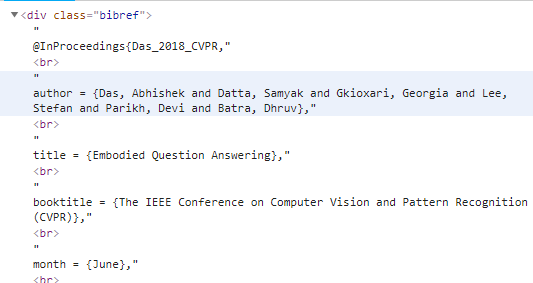
所以直接编写正则一次性将所需信息取出。结果如下

但是就这些数据种类可玩性还是太低了,一开始我的想法是能根据论文的研究方向做一个聚类,或者是通过论文使用的测试数据集来画一个研究进展的趋势图(也可以通过时间序列进行未来预测),又或者是根据作者所属国家画一个区域热力图。但可惜的是这些数据都没有,去GitHub上找别人整理的信息也无非是多了一个论文属性,并不是我想要的。虽然有一种操作是利用已有的作者名或者论文名再去其它地方爬相关信息,以后有时间再尝试。
所以最后就只能在作者这个属性上做点文章了。我的目的是绘制一个作者关系图,用圆来代表作者,一起发过论文的作者用线相互连接。发论文量越多的作者圆越大。代码过程是通过pandas将作者属性提取,之后将所有作者放入list里进行遍历计数,先计算所有作者的发文数,之后进行两重循环计算作者之间的关联。最后可视化使用的是基于百度echarts上的pyecharts,可以在jupyter上处理完数据后直接导入做可视化,也可以导出像echarts的Web,而不必另写js代码。
可视化结果

当鼠标放到某个作者圆圈上时,其它圆圈变暗,与其一起发表过论文的作者圆圈和连线高亮。放大效果如下:
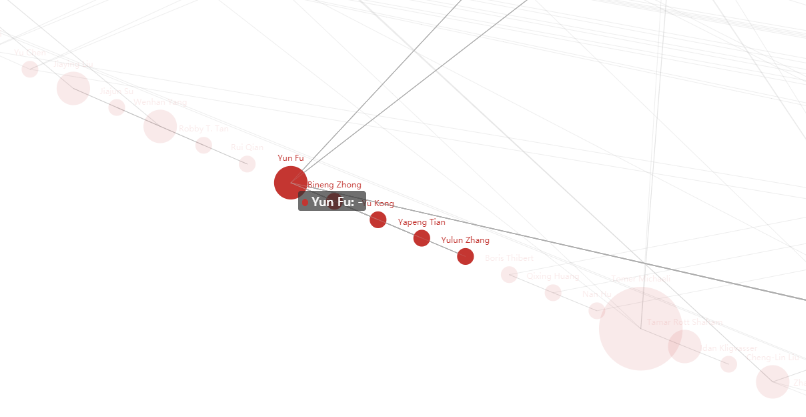
有兴趣可点链接下载,即可打开Web。
性能优化
跟之前一样使用多进程爬虫。32进程时用时20秒左右,与之前差不多,这里不再赘述。