作业描述
| 作业描述 | 链接 |
|---|---|
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W |
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W/homework/2642 |
| 结对学号 | 221600131、221600439 |
| 作业目标 | 了解NABCD模型,学习分析用户需求,利用相关软件设计原型 |
结对过程
快速组好了队,之后就是进行需求分析。参考《构建之法》第八章第8.1节《软件需求》指出的步骤,我们分析如下:
- 需求捕捉:题目已经代我们完成了这个步骤。
- 分析和定义需求:这个是我们最核心的步骤,明确这个需求究竟是为了什么而出现的。
我们分析认为,我们的产品面向的人员是高校内相关领域的师生,根据需求得出的用户画像如下:
- 用户是高校从事科研的师生。
- 提出需求的用户关注计算机视觉, CVPR、ICCV、ECCV 等会议是该领域的顶会。
而目的则是为这些人提供论文检索与数据分析,方便他们查找到相关论文。我们整理需求得出以下核心需求:
- 用户需要快速下载/查询一系列论文。
- 用户需要各类关键词对比等数据分析。
我们参考知网等论文查询网站,写下了基本需求。但知网等作为通用型查询网站,需要满足所有人的需求,势必只能提取出公共部分。类似什么论文推荐都属于这一部分。但我们不同的是,我们的客户有指向性。我们需求的初期目标针对的是计算机视觉领域,这个领域和其他领域比有以下不同:
- 相当一部分论文在GitHub上开源了源码,供大家Clone。GitHub是一个程序员社交平台,可以看出一个项目的热度。
- 计算机视觉有一些公共数据集供大家benchmark,涉及某个子领域的论文一般都会写明自己benchmark的数据。
因此,我们找到了这个项目的需求和创新点,接下来的事情就是结队写需求+墨刀原型了。
NABCD模型
Needs
用户的原始需求
- 用户可给定论文列表
- 通过论文列表,爬取论文的题目、摘要、关键词、原文链接;
- 可对论文列表进行增删改操作(今年、近两年、近三年);
- 对爬取的信息进行结构化处理,分析top10个热门领域或热门研究方向;
- 可对论文属性(oral、spotlight、poster)进行筛选及分析;
- 形成如关键词图谱之类直观的查看方式;
- 可进行论文检索,当用户输入论文编号、题目、关键词等基本信息,分析返回相关的paper、source code、homepage等信息;
- 可对多年间、不同顶会的热词呈现热度走势对比(这里将范畴限定在计算机视觉的三大顶会CVPR、ICCV、ECCV内)。
- 可进行数据统计,例如每个国家录用文章的分析、每个学校录用文章的分析、哪个学校哪方面的研究方向比较强等。
分析
《构建之法》第八章,8.1节《软件需求》指出,我们需要“对从各个方面获取的需求进行规整,定义需求的内涵”。我们认为,目前布置的这个需求,只是一个给高校内相关领域成员使用的论文检索与数据分析平台,一切都围绕着这个点进行设计与开发。因此,我们不应该做太多不相关需求。既要做加法,也要做减法。
为此,我们整理需求如下:
用户
系统支持多用户登录。
用户新增论文
- 用户给定列表。该列表可能是一组论文标题,也可能是会议名称。
- 当用户输入为一组论文标题时,先进行内部查询。如该论文未被入库,尝试从互联网查找到相应论文URL。
- 当用户输入为会议名称时,尝试抓取该会议所有论文标题,并从标题查找对应URL。
- 分析指定列表,列入论文爬取待处理队列。 用户可随时对待处理队列进行修改。
- 论文爬取:
- 从待处理队列中取出相应URL,获得论文的题目、摘要、关键词、原文链接、领域、研究方向、源码、数据集等,对爬取的信息进行结构化处理,并存入公用论文库。
- 对公用论文库内的论文,定期更新其下载量及被引量(如果被爬取方可提供的话)。当其被其他论文引用时,一并收录引用其的论文。
用户个人页面
- 显示用户关注的领域、作者、机构的最新论文。
- 显示用户关注的论文的最新动向(如被引列表)。
- 为用户个性化推荐最新论文。这部份暂时预留,不做实现。
检索论文
- 用户可依据以下维度检索论文:论文编号、论文题目(模糊)、关键词(模糊)、发表时间(年份及月份区间)、属性(oral、spotlight、poster)、领域、作者、单位、研究方向、会议、对当前用户是否可见。
- 检索结果列表需满足:
- 检索摘要包括论文题目、属性、作者、单位、会议、下载量、被引量。
- 可按照指定列排序。
- 点击进入论文详细页面。
- 提供论文批量管理:
- 允许有删除权限的用户(如管理员)删除本篇论文。
- 允许当前用户标记本论文为当前用户永不可见。
- 允许当前用户设置是否关注本篇论文。
- 详细页面需满足:
- 点击“关键词”等可被数据分析的范围,进入数据分析页面。范围见数据分析一节。
- 显示论文题目、属性、作者、单位、会议、下载量、被引量、摘要、关键词、引用列表、被引列表、可能相关论文列表。
- 显示源码下载链接、作者个人主页(如果有的话)。
- 可直接下载论文,或跳转到论文所在杂志页面/会议页面,或跳转到索引页面。
- 提供论文管理功能,即:删除、是否可见、是否关注。
数据分析
数据分析指针对论文库整体的分析,“当前用户不可见”的选项对其无效。
总体监控
- 显示最近抓取的新论文列表。
- 显示最近关注最多的新论文列表,计算维度包括:
- 若该论文在GitHub上有提供源码,以GitHub Star和Issue的数量为其中之一计算维度。
- Twitter等社交媒体的提及数量。
- 被引用次数。
关键词
列表
- 依据关键词,显示 Top 10 热门领域或热门研究方向。同时绘制关键词云图,以便直观显示出哪些关键词最引人注目。
- 显示以论文数量倒序排序的关键词排行。
- 展示多年间不同顶会的热词对比。(顶会:暂只考虑CVPR、ICCV、ECCV)
- 每个顶会各一个柱状图。柱状图取当年Top X关键词,每个关键词为一组,每组内含三个柱,分别代表这三年的该词论文数量。
详细
- 允许用户关注或取消关注。
- 显示热度趋势(按月?按年?待细化)。
- 显示该领域论文,可通过排序获得:
- 该领域最新论文
- 显示该领域指定时间(默认为1年内)被引最多论文。
- 该领域最近最热论文
- 显示折线图:该关键词每年的热度。
- 数据集对比。
数据集对比
每一个关键词对应的数据集均不同,可以针对每一个关键词设置不同的数据集,由爬虫对论文内提到的数据集进行分析,提取出该数据集的对比数据。 该页面需要:
- 准确率进展趋势。
- 领域排行榜。
国家
国家数据过于泛,对于单个领域的研究几乎是没什么作用的。因此国家数据应当依托于关键词,在关键词之上对不同国家进行对比。
列表
- 显示以论文数量倒序排序的国家排行。
- 展示TOP X国家的历年论文发表数量,以折线图显示。
- 展示不同国家论文发表比例,以饼图显示。
详细
- 显示以论文数量倒序排序的机构排行。
- 显示国家论文,可排序获得:
- 该国家在该领域的最新论文。
- 显示该国家指定时间(默认为1年内)被引最多论文。
- 显示折线图:该国家每年(月?)在该关键词发表论文的数量,即热度趋势。
机构
基本同国家。
Approachs
基于 Web 开发技术,前端采用 React + ant.design。后端使用 MySQL 数据库,并包括以下几个部分:
-
后端API:Java,配合Spring Boot + MyBatis。
-
搜索:ElasticSearch。
-
服务间通信:Kafka。
-
爬虫:从Kafka接收队列并爬取数据,爬取后存储入对象存储并将结构化数据入库。
-
论文存储:上云使用阿里云OSS,自建使用Minio(Amazon S3 API 兼容)。
目前由于数据分析需求不复杂,暂不需要专用数据处理端并保存结果,直接由大后端统一处理即可。以上架构可方便地上云或自建。
Benefits
用户
- 贴近学术前沿,相对通用性查询网站来说会更贴合相关方向的课题组。
- 提供个性化论文推荐,可使用户快速获知所在领域最新动态。
- 可自动分析不同论文对相同公共数据集的准确性并排序,快速筛选效果最好的一系列论文。
开发机构
- 自主知识产权,避免受制于人。
- 对于开发机构自身,可通过自己定制化开发完成自己的特殊需求。
- 自动化爬取最新信息,避免手动下载与分享带来的繁琐。
- 锻炼相关课题组学生开发与工程水平。
Competitors
优势
优势和“B”似乎意义相近。
劣势
- 爬取速度。类似知网、万方等数据库均可接触到一手资源,本项目只能爬取二手资讯,时效性差。
- 数据量。需要相当长一段时间可能才能爬取数目足够的论文。考虑到即使机构订阅了相关数据库,对方也禁止使用爬虫下载,这违反了使用协议,且对方也有相关反制措施,必须控制爬虫速度。
- 稳定性。项目初期稳定性相对差。
- 搜索。自己做的搜索效果远比不上对方专业搜索,这需要之后进一步维护。
Delivery
对外开放部分只能开放索引查询及数据分析。考虑到,相当一部分论文不处于Public Domain,下载与存储部分涉嫌侵犯版权,且CDN流量相对贵,初期暂不允许校外机构下载论文。
我们不认为盲目面向非特定目标人群推广存在意义,推广应当“快、准、狠”。由于学术圈本身较小,我们认为,应当在初期交由学生及相关导师,请其使用。由导师以及学生私下交际圈口口相传并提出进一步改进需求,逐渐完善程序本身的同时根据用户使用情况来制定下一步推广策略。
协作工具
- 关于Markdown文档,我们采用 https://hackmd.io 进行协作。
- 关于原型开发工具,我们采用墨刀。
原型模型
《构建之法》第七章,7.2.7节《投资质量》指出,“在做快速原型的过程中,有些部分可以做得粗糙一点。”。我们认为,原型只是为了指出这个页面有哪些功能,并不是具体到去做某个页面设计。况且,我们的初步需求还是有相当大的被推翻的可能性。因此,我们做了以下较为粗糙的原型。
论文列表
待爬取队列

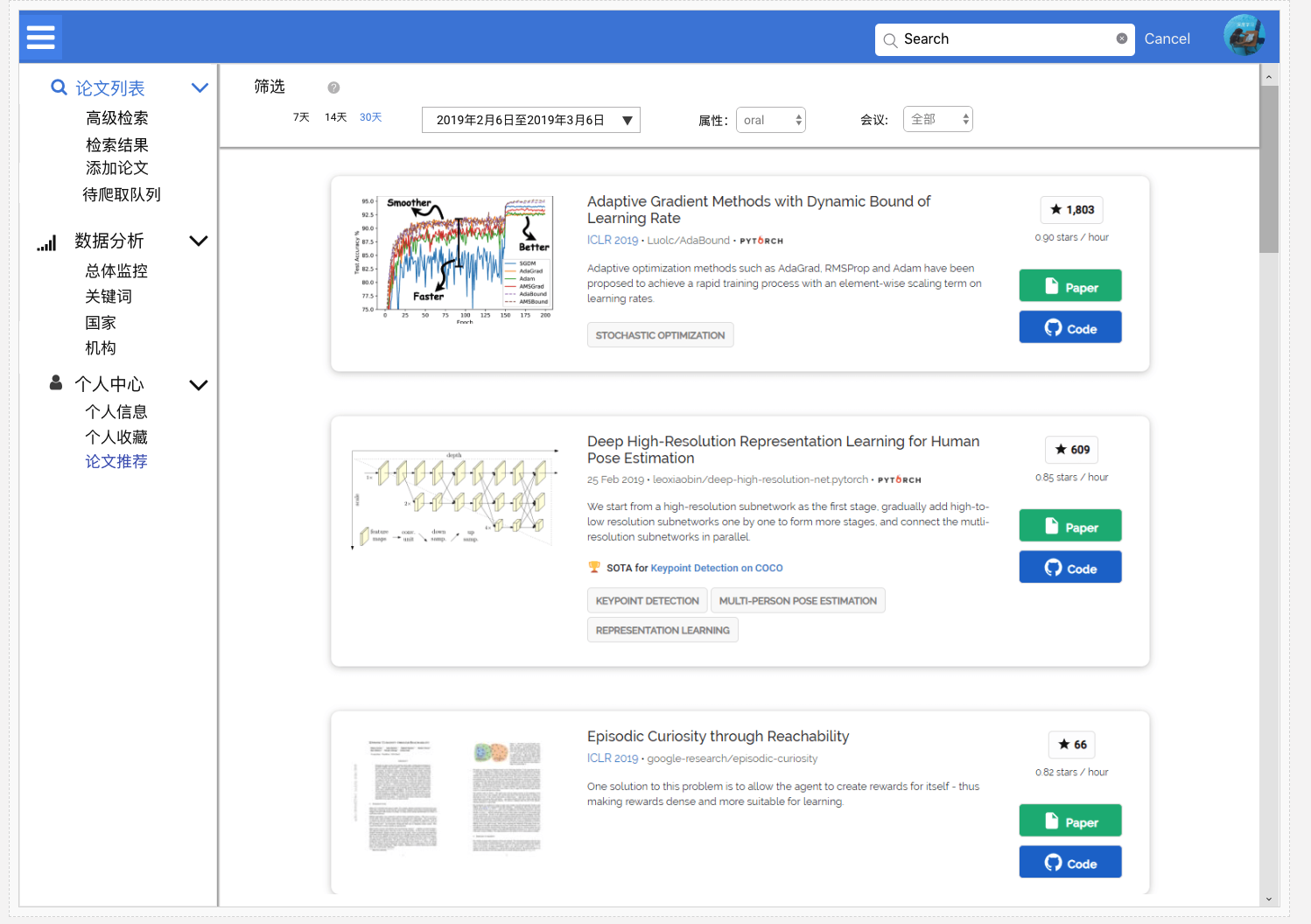
高级检索
基本参考知网设计。
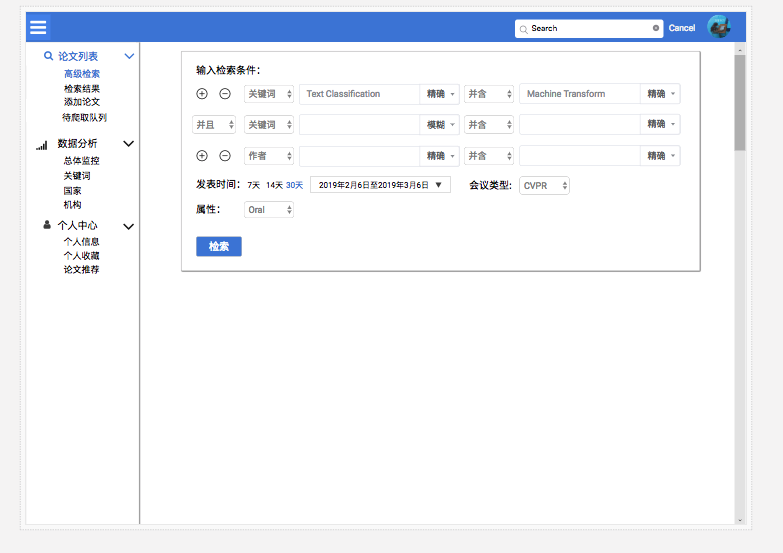
检索结果
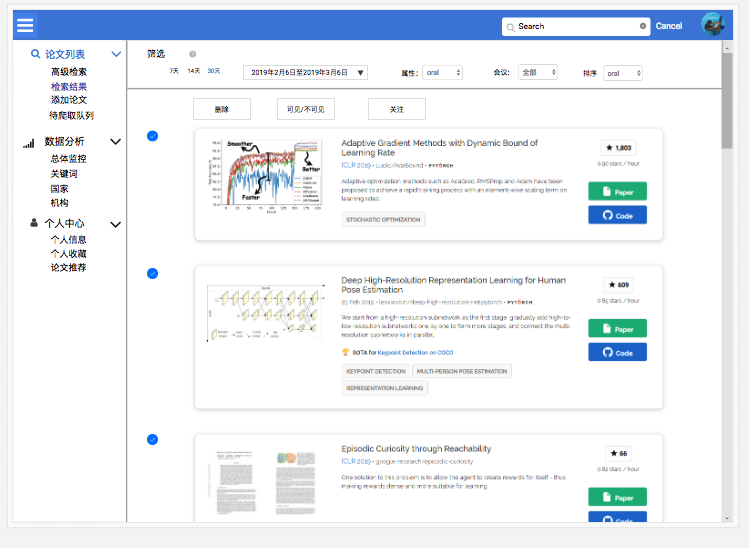
添加论文

论文详细页面

数据分析
总体监控

关键词

关键词详细信息
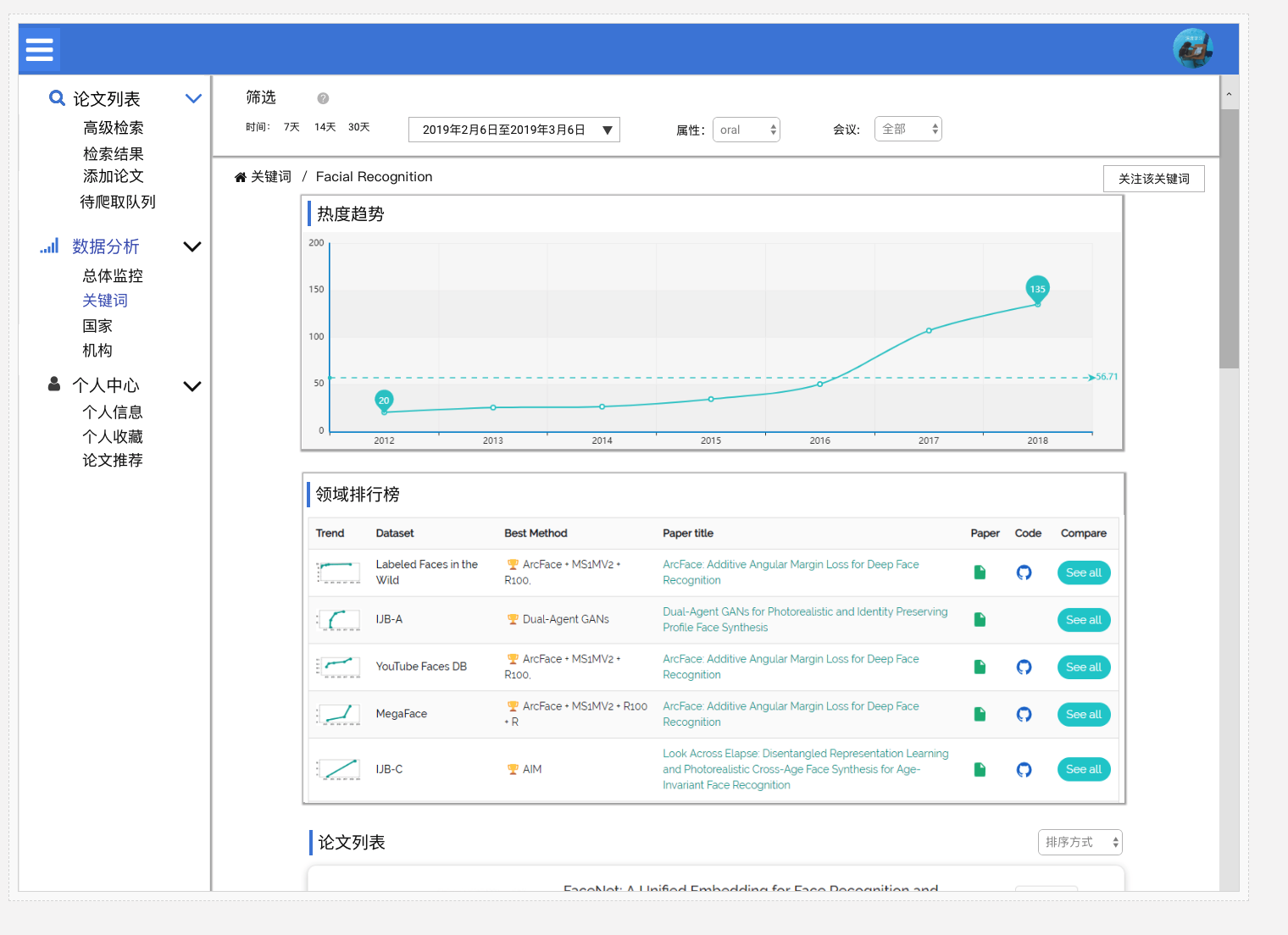
领域最新方法

国家分析
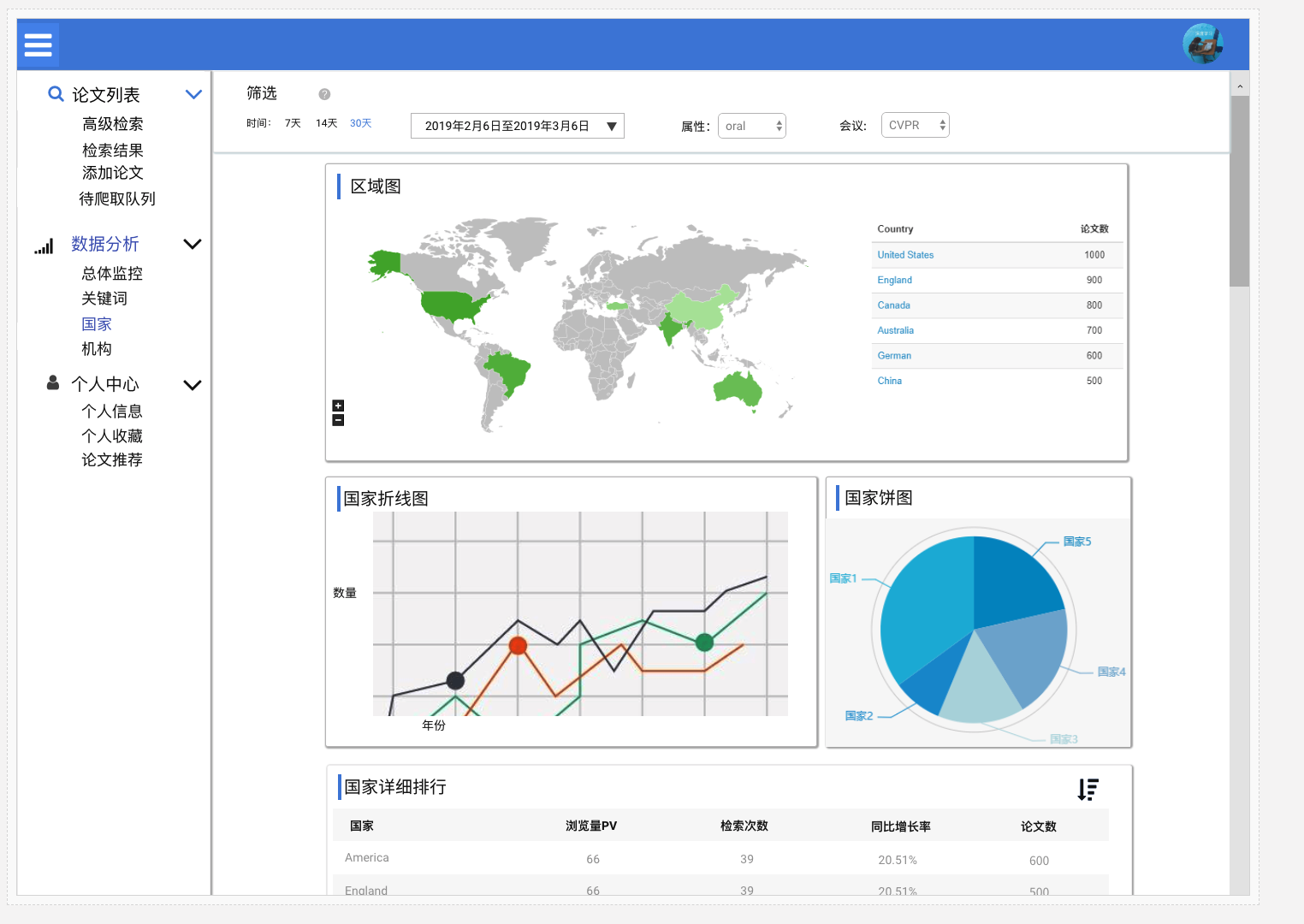
国家详细信息
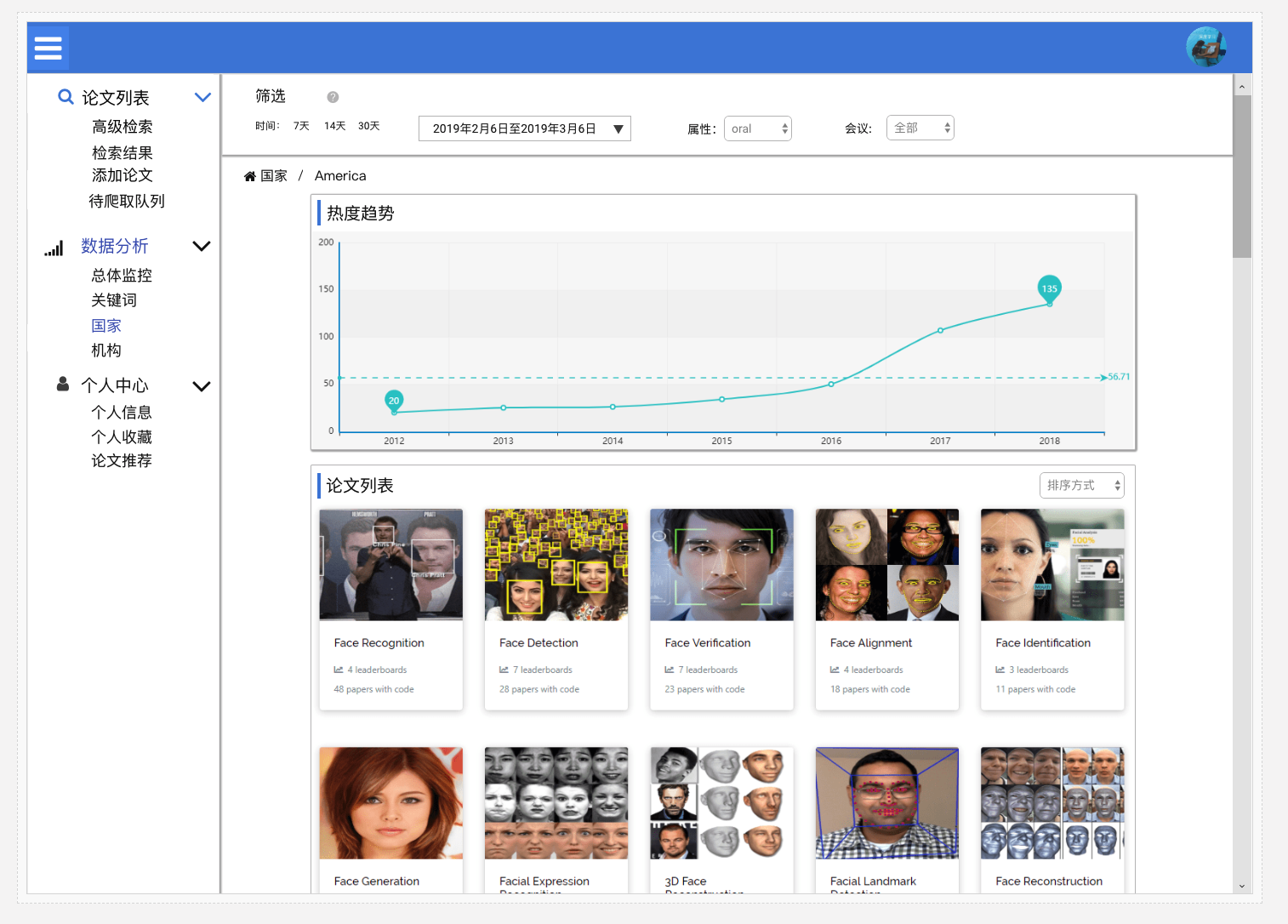
论文推荐
结对照片

PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| - Estimate | 估计这个任务需要多少时间 | 30 | 10 |
| Development | 开发 | ||
| - Analysis | 需求分析 (包括学习新技术) | 180(学习新技术被计入具体编码部分) | 240 |
| - Design Spec | 生成设计文档 | 360 | 240 |
| - Design Review | 设计复审 | 240 | 120 |
| - Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 1 | |
| - Design | 具体设计 | 1440 | |
| - Coding | 具体编码 | 13440 | 项目未开始 |
| - Code Review | 代码复审 | 贯穿代码开发过程,不作为单独流程 | 0 |
| - Test | 测试(自我测试,修改代码,提交修改) | 贯穿代码开发过程,不作为单独流程 | 0 |
| Reporting | 报告 | ||
| - Test Report | 测试报告 | 240 | 0 |
| - Size Measurement | 计算工作量 | 120 | |
| - Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 240 | |
| 合计 | 16051 |
遇到的困难及解决方法
困难1
困难描述
需求设计后难以取舍。
解决尝试
讨论。
是否解决
已解决。
有何收获
需求设计不能一口吃成个大胖子,必须紧扣核心需求,围绕核心需求进行扩展。
困难2
困难描述
博客园的编辑器太难用。
解决尝试
使用Hackmd
是否解决
已解决。