spark06

总共提交的任务分为四个阶段,提交+执行
- 解析代码生成DAG有向无环图,在分配完毕executor以后
- 将生成的DAG图提交给DAGScheduler这个组件在哪里(driver),driver中的DAGScheduler负责切分阶段,按照DAG图中的shuffle算子进行阶段的切分,切分完毕阶段以后,按照每个阶段分别生成task任务的集合,将所有的task任务放入到set集合中,一次性提交每个解阶段的所有任务(每个阶段准备 好就提交哪个阶段)
- 将任务的集合提交给taskScheduler(Driver),这个组件会将数据通过集群管理器提交给集群(executor),对任务进行监控,分配资源,负责提交,负责执行,负责故障重试,负责落后任务的重启
- 真正提交到executor端,在executor中进行执行,保存执行过后的数据,或者存储数据
从spark-submit开始,剖析所有的运行流行(重点,重点,重点)

spark-submit方法的时候,SparkSubmit 类
spark-submit --master xxx --class xxx --name xxx xxx.jar input output

运行sparksubmit中的main方法
所以--master xxx --class com.bw.spark.wordcount --name xxx xxx.jar input output 这些东西都是main方法的参数
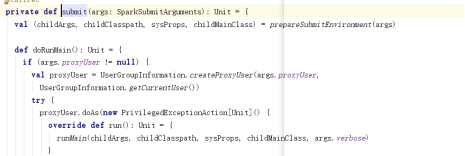

通过反射机制,将mainClass的字符串转换成一个主类

根据主类找到这个类中的main方法

通过反射机制执行main方法,将传递的参数放置到main方法中执行
总结:其实任务的提交就是运行main方法,解析代码解析main方法,到此为止不动了
开始初始化driver端的东西 初始化上下文sparkContext DAGScheduler TaskScheduler
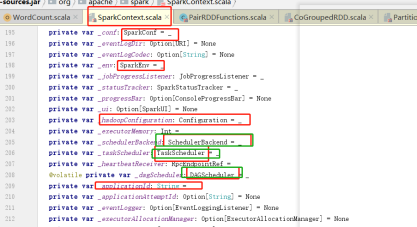
在提交任务的时候就要初始化组件,DAGScheduler TaskScheduler 提交任务的通信组件SchedulerBackEnd
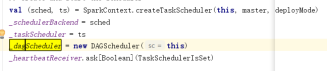
根据部署的集群模式不一样。创建不同的DAGScheduler和Task Scheduler、
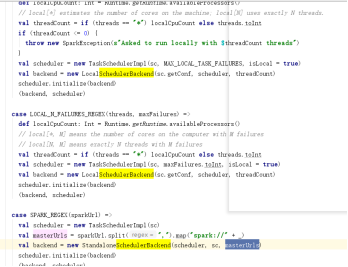
根据部署模式不一样创建的SchedulerBackEnd也不一样,根据资源分配不同的核数
- 创建实例完毕以后,开始解析代码(executors已经启动),记录textFile从什么位置开始读取数据,记录每个算子生成rdd的数量,分区个数,逻辑,各个rdd之间的血缘关系,只有遇见真正的action算子才开始执行,会生成DAG有向无环图,rdd就是点,算子就是线
将任务提交给DAGScheduler进行有向无环图的切分阶段






从saveASTextFile开始进入,找到最后一步,将任务提交给DAGScheduler
到DAGScheduler中进行任务的切分阶段,将每一个准备好的阶段提交给TaskScheduler

在DAGScheduler中的doOnReceive方法进行任务的处理

DAGScheduler中负责将任务进行拆分,按照shuffle算子进行拆分不同的stage

找到最后一个阶段,根据这个阶段向前推,一直递归调用,找到没有为止
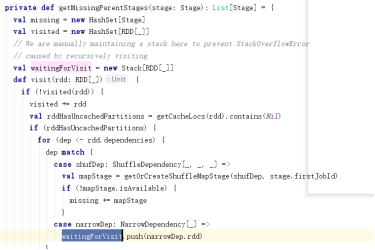
其实阶段的推理很简单,通过最后一个rdd向前推,如果是宽依赖就将stage+1,如果是窄依赖就将当前阶段中的rdd+1.当每个阶段都推衍完毕以后,将每个阶段中的所有的task组成一个taskSet,然后提交。
task是什么?
最小的执行单位,每个分区会产生一个task任务,一个stage中task任务的数量,这个stage中的最后一个rdd的分区数量就是task任务的数量,什么是stage?一组业务逻辑的集合,这个组的业务逻辑中,所有的rdd之间的依赖关系都是一对一的管道形式的任务
task是什么?


shuffleMapStage中产生的任务就是shuffleMapTask resultStage中产生的任务就是resultTask
接上!!!!!
每个阶段匹配一下,如果是shuffleMapStage就组装一个集合。这个集合中装入的都是shuffleMapTask 如果是resultStage那么这个stage中装入的就是resultTask
将任务组成集合提交给TaskScheduler

将任务集合提交给taskScheduler,TaskScheduler进行任务的提交到集群中,然后执行操作,负责监控,申请资源,故障重试

ctrl+alt+b找到接口的实现类
|
override def submitTasks(taskSet: TaskSet) {
|
在taskSchedulerImpl中通过submitTasks方法将任务提交SchedulerBackEnd组件进行提交任务
SchedulerBackEnd是什么?

他是一个接口,这个接口存在两个实现类,一个是本地的实现类,一个是负责集群通信的实现类
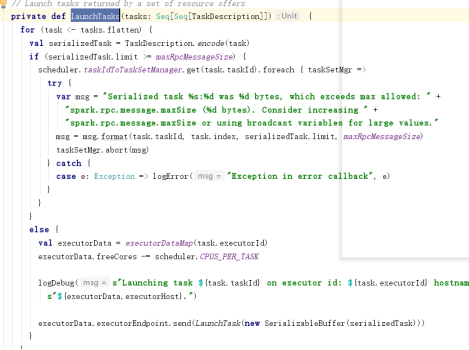

首先将任务进行序列化为了传输数据,然后通过rpc协议进行任务传输到executor端
executor开始执行任务

executor就是线程池
一个池子中已经含有很多线程,使用的时候不需要创建,直接去取,用完以后放入线程池,并且线程的生命周期不需要人为管理
singleThreadPool 单个线程线程池
cachedThreadPool 缓存线程池,含有已经创建好的线程,如果不够可以继续创建
fixThreadPool:固定数量的线程池
ScheduledTheadPool:定时线程池
executor就是一个线程池,这个线程池中能够执行的只有多线程的类,而task任务不是多线程的,所以用一个taskRunner多线程的类进行包装,可以放入到线程池中!!!!

在运行任务的时候调用taskRunner中的run方法,先进行任务的反序列化,然后交给执行其进行执行,执行完毕的任务从taskset中去除
task -->shuffleMapTask resultTask

任务的执行就是在task中调用runTask方法
driver端是所有应用的老大,他会管理每一个executor中的任务执行,监听,数据管理,任务重启。。。。 TaskScheduler
通信框架netty spark1.6以后的 spark1.6以前的事akka
netty框架和akka框架一样,组件的类型变了,逻辑和代码没变化
actorSystem:RCPEnv
actor:RPCEndPoint
actorRef:RpcEndPointRef
receive:receive
preStart:onstart
spark任务的四大调度
application
spark-submit spark-shell提交的任务就是一个应用,会生成一个application
job
遇见一个action算子就会生成一个job
stage
遇见shuffle就会 切分stage,stage = shuffle+1
task
运行任务的最小单位,一个stage中最后一个rdd的分区数量就是这个stage中task任务的个数
几个重要的数值:
读取外部文件的时候,rdd的分区数量,存在多少个block快就有多少个分区
stage中task的个数取决于最后一个rdd的分区数量
写入到hdfs中的文件个数(saveAsTextFile),存储的rdd的分区数量
一个job每个能够运行多少个task任务?每个stage中的最后一个rdd的分区的总和
同时并行能够运行多少task任务?集群中总核数,如果任务数量比总的核数多,等待
自定义排序
|
object UDFSort { |