spark01
spark的特点
搭建spark的集群
提交spark的任务
spark的运行机制
spark wordcount
spark的官网spark.apache.org
spark运行速度比较快:因为使用内存
mr存在昂贵的shuffle
mr 只有两个算子 (map reduce)*N
mr每次计算的时候中间结果落地到磁盘中
spark 算子比较多
不需要落地中间结果到磁盘上
spark支持多种语言
spark DAG有向无环图 可以先生成图,然后将图进行切分整理,然后按照图进行优化执行
spark存在容错 mr不存在容错,spark是一次性运行完毕的
spark的部署模式
spark部署模式分为四种
local 本地模式,开箱即用
standalone:spark自带的模式,这个模式是最常用的模式
yarn:资源管理框架
mesos:和yarn一样
按照spark集群
下载安装包
官网中下载
部署spark master worker worker worker
spark -- scala --- jdk1.8

根据进程号查看任务的端口号
7077是master的通信端口,这个端口tcp
6066是restful风格的http请求接口
8080master的监控页面
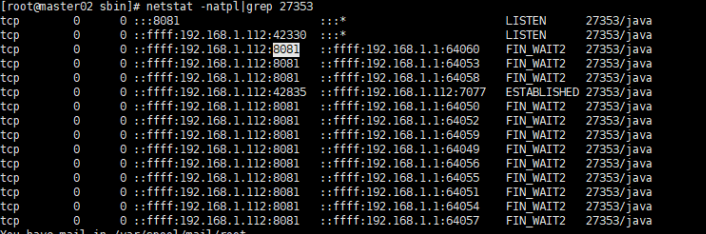
8081是worker的监控页面
7077是woker连接master的地址
master里面的每个worker都是8cores 1G


查看系统内存
worker cores = all cores memory = all memory minus 1G
spark任务的提交
spark-submit 提交的是jar包
spark-shell 交互式命令行

spark-shell中含有spark-submit的内容。其实spark-shell提交任务是使用的spark-submit
spark-submit的使用:
spark-submit [options] <app jar | python file> [app arguments]
--master 提交任务到哪个集群中
--class 运行jar包中的哪个类
--name 运行的任务再监控页面中可以看到任务的名字
|
spark-submit --master spark://master02:7077 --class org.apache.spark.examples.SparkPi /home/ghostwowo/Downloads/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 10 |
spark-submit --master local本地模式的单个cores local[N]本地模式的n个核数 local[*]
executor执行其

每个worker默认启动一个executor,每个executor默认使用1g内存所有的cores
sparks-shell交互式命令行
spark-shell --master spark://master02:7077 这个命令是再集群中开启一个长应用,但是不会运行任务,交互式命令行
任务的监控页面是4040端口,任务运行的时候spark集群的上下文文件对象是sc实例,通过使用sc就可以和集群进行沟通会话
spark版本的wordcount
再spark中读取文件的时候发现文件不存在
因为spark是集群模式,sc.textFile(“”)读取文件的时候,每台机器都读取自身的文件
为什么读取的时候不报错?
读取的数据都是rdd,rdd上面的操作方法都叫做算子,算子分为两种 转换类的算子 行动类的算子
将一个rdd转换为另一个rdd的算子就是转换类算子,是懒加载的
行动类算子,一旦一个应用中遇见了行动类的算子,那么才会真正的执行
transformation action
其实spark任务读取文件的时候都从hdfs中读取
|
scala> sc.textFile("hdfs://master:9000/aaa.txt") res8: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/aaa.txt MapPartitionsRDD[8] at textFile at <console>:25 scala> res8.flatMap(_.split(" ")) res9: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[9] at flatMap at <console>:27 scala> res9.map((_,1)) res10: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[10] at map at <console>:29 scala> res10.groupBy(_._1) res11: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[12] at groupBy at <console>:31 scala> res11.mapValues(_.size) res12: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[13] at mapValues at <console>:33 scala> res12.collect res13: Array[(String, Int)] = Array((tom,1), (hello,4), (jerry,1), (rose,2), (jack,2)) |
一般的算子都是转换类算子
collect将数据从多个rdd中收集起来
saveAsTextFile(“”)将数据保存到一个文件介质中
foreach(println)遍历每一个元素,进行处理
idea中的wordcount
|
def main(args: Array[String]): Unit = { |
运行内存不足的时候-Xmx512M增加运行内存
spark-submit --master spark://master02:7077 --class com.bw.spark.WordCount Spark1807-1.0-SNAPSHOT.jar hdfs://master:9000/aaa.txt hdfs://master:9000/aaares1
提交任务到集群中,如果已经有任务再运行了,那么就不存在足够的资源;需要等待资源分配
再提交任务的时候查看spark的集群进程


再master02上面多了一个spark-submit的进程,这个进程主要是提交的进程,再什么位置提交任务就会多了一个spark-submit的进程
CoarseGrainedExecutorBackEnd 简称为executor,每个worker都会生成一个executor的执行器
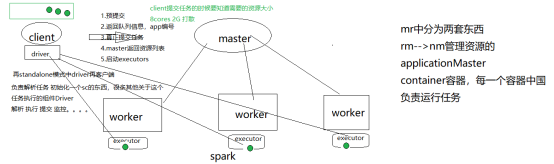
Driver是一个应用的进程老大,管理所有的应用执行和切分以及分配,再standalone模式中driver就在client端,driver负责初始化工作,初始化sc,初始化很多运行时候需要的组件,再哪里提交的任务,哪里就是客户端,spark on yarn 这个driver就在集群中
任务的资源分配
worker的资源分配 一个worker再启动的时候,本台机器上的所有cores 和all memory-1G
worker启动一个executor,一个executor占用的资源是多少?

executor默认使用的cores是所有的核数 memory是1G
再运行spark-shell脚本的时候,运行spark-submit提交的任务,这个任务没有资源分配,所以一直处于等待状态

这就是资源占用的提示
自定义资源分配
cores memory
all cores and 1G executor占用worker的资源分配
spark-shell spark-submit
8cores 1G
spark-shell 3 executor 4cores 512M
spark-submit 3 executor 4cores 512M
以上资源分配就可以形成两个应用并行运行
--executor-cores executor再启动的时候使用的cores核数
--executor-memory executor再启动的时候需要的内存
--total-executor-cores 所有的executor再启动的时候需要的总的cores
spark-shell --master spark://master02:7077 --executor-cores 4 --executor-memory 512M
spark-shell --master spark://master02:7077 --executor-cores 4 --executor-memory 512M --total-executor-cores 12