Coursera课程《Using Python to Access Web Data》 密歇根大学
Week6 JSON and the REST Architecture
13.5 JavaScript Object Notation(JSON)
JSON是一种相比于XML更简单的格式,而且现在在互联网上非常普遍。XML是很强大,但是很多时候我们并不需要使用这么强大的格式,我们就能完成我们的任务。
import json
data = '''{
"name": "Chuck",
"phone": {
"type": "intl",
"number": "+1 734 303 4456"
},
"email": {
"hide": "yes"
}
}'''
info = json.loads(data)
print('Name:',info["name"])
print('Hide:',info["email"]["hide"])
JSON表示数据是用一种list与dictionary的组合的结构。
13.6 Service Oriented
有一些小应用需要使用其他网页提供的一些服务的时候,就会需要使用这些网页发布的“规则”来进行获取服务,这种我们叫做API(Application Program Interface)。
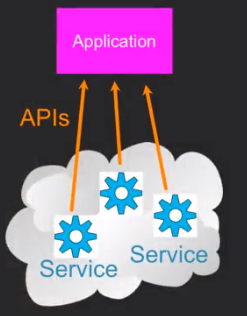
13.7 Using Application Programming Interfaces
以下是使用Google的geocoding API的代码。
import urllib.request, urllib.parse, urllib.error
import json
# Note that Google is increasingly requiring keys
# for this API
serviceurl = 'http://maps.googleapis.com/maps/api/geocode/json?'
while True:
address = input('Enter location: ')
if len(address) < 1: break
url = serviceurl + urllib.parse.urlencode(
{'address': address})
print('Retrieving', url)
uh = urllib.request.urlopen(url)
data = uh.read().decode()
print('Retrieved', len(data), 'characters')
try:
js = json.loads(data)
except:
js = None
if not js or 'status' not in js or js['status'] != 'OK':
print('==== Failure To Retrieve ====')
print(data)
continue
print(json.dumps(js, indent=4))
lat = js["results"][0]["geometry"]["location"]["lat"]
lng = js["results"][0]["geometry"]["location"]["lng"]
print('lat', lat, 'lng', lng)
location = js['results'][0]['formatted_address']
print(location)
使用这个API,Google可以给我们返回我们输入的地点的经纬度之类的信息。
需要说明的是,json.dumps()用于将dict类型的数据转成str,因为如果直接将dict类型的数据写入json文件中会发生报错,因此在将数据写入时需要用到该函数。而它带的那个参数indent可以使json显示为树形结构,更加方便阅读。
13.8 Securing API Requests
这里我们讲的Twitter的API和之前的Google Map APIs不同,它需要我们去注册,获得他们的API Key。
import urllib.request, urllib.parse, urllib.error
import twurl
import json
import ssl
# https://apps.twitter.com/
# Create App and get the four strings, put them in hidden.py
TWITTER_URL = 'https://api.twitter.com/1.1/friends/list.json'
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
while True:
print('')
acct = input('Enter Twitter Account:')
if (len(acct) < 1): break
url = twurl.augment(TWITTER_URL,
{'screen_name': acct, 'count': '5'})
print('Retrieving', url)
connection = urllib.request.urlopen(url, context=ctx)
data = connection.read().decode()
js = json.loads(data)
print(json.dumps(js, indent=2))
headers = dict(connection.getheaders())
print('Remaining', headers['x-rate-limit-remaining'])
for u in js['users']:
print(u['screen_name'])
if 'status' not in u:
print(' * No status found')
continue
s = u['status']['text']
print(' ', s[:50])
注意,headers = dict(connection.getheaders())这行代码是来获取headers的。
而print('Remaining', headers['x-rate-limit-remaining'])是获取限速的剩余次数的,是写在header里的。(好像只有Twitter API配置了这个?)
而我们要在Twitter的网页上获取下面代码里的这些东西。不然,我们是没法访问Twitter的服务的。
def oauth():
return {"consumer_key": "h7Lu...Ng",
"consumer_secret": "dNKenAC3New...mmn7Q",
"token_key": "10185562-eibxCp9n2...P4GEQQOSGI",
"token_secret": "H0ycCFemmC4wyf1...qoIpBo"}
以下是使用叫作OAuth的一种协议来获取访问Twitter的URL的。
import urllib.request, urllib.parse, urllib.error
import oauth
import hidden
# https://apps.twitter.com/
# Create App and get the four strings, put them in hidden.py
def augment(url, parameters):
secrets = hidden.oauth()
consumer = oauth.OAuthConsumer(secrets['consumer_key'],
secrets['consumer_secret'])
token = oauth.OAuthToken(secrets['token_key'], secrets['token_secret'])
oauth_request = oauth.OAuthRequest.from_consumer_and_token(consumer,
token=token, http_method='GET', http_url=url,
parameters=parameters)
oauth_request.sign_request(oauth.OAuthSignatureMethod_HMAC_SHA1(),
consumer, token)
return oauth_request.to_url()
def test_me():
print('* Calling Twitter...')
url = augment('https://api.twitter.com/1.1/statuses/user_timeline.json',
{'screen_name': 'drchuck', 'count': '2'})
print(url)
connection = urllib.request.urlopen(url)
data = connection.read()
print(data)
headers = dict(connection.getheaders())
print(headers)
作业代码1
import urllib.request, urllib.parse, urllib.error
import json
url=input('Enter location: ')
print('Retrieving ',url)
uh = urllib.request.urlopen(url)
data = uh.read().decode()
print('Retrieved', len(data), 'characters')
info = json.loads(data)
sum = 0
count = 0
for item in info["comments"]:
sum = sum + item["count"]
count+=1
print('Count: ', count)
print('Sum: ',sum)
作业代码2
import urllib.request, urllib.parse, urllib.error
import json
# Note that Google is increasingly requiring keys
# for this API
serviceurl = 'http://py4e-data.dr-chuck.net/geojson?'
while True:
address = input('Enter location: ')
if len(address) < 1: break
url = serviceurl + urllib.parse.urlencode({'address': address})
print('Retrieving', url)
uh = urllib.request.urlopen(url)
data = uh.read().decode()
print('Retrieved', len(data), 'characters')
try:
js = json.loads(data)
except:
js = None
if not js or 'status' not in js or js['status'] != 'OK':
print('==== Failure To Retrieve ====')
print(data)
continue
place_id = js["results"][0]["place_id"]
print('Place id ',place_id)