用 Excel 处理数据时,经常会涉及到多页 sheet 数据之间的关联运算需求,用 vlookup 可以完成部分简单关联,但较复杂的情况时仍然不太方便,常常需要多次操作才能完成。另外,当要做关联的文件比较多,需要批量处理时,虽然可以借助 VBA 来实现,但 VBA 不是个专门为结构化计算设计,实现计算非常繁琐。这里给出一些关联运算的示例,分析解决方法并给出 SPL 代码。SPL 是专业计算引擎 esProc 使用的语言,用于处理结构化数据运算非常方便,比 vlookup 及 VBA 更简单。
一、引用复制其它页的列
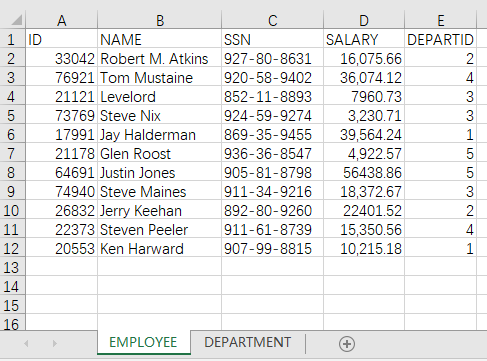
现有从财务部获取的员工工资表(EMPLOYEE 页),但是其中的部门信息只有部门编号(DEPARTID 列),不方便阅读和出报表。从人事部获取到部门信息表(DEPARTMENT 页)后,需要将员工工资表的 DEPARTID, 逐一到部门信息表中查找到对应的 ID,然后复制部门名称(DEPARTMENT 列)到员工工资表。
文件 salary.xlsx 中数据如下:
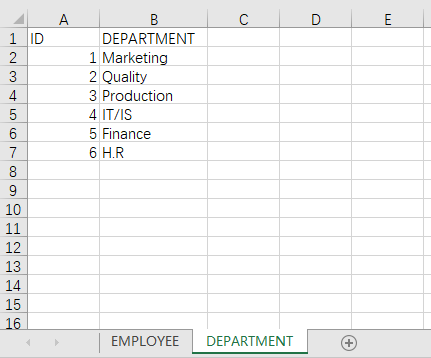
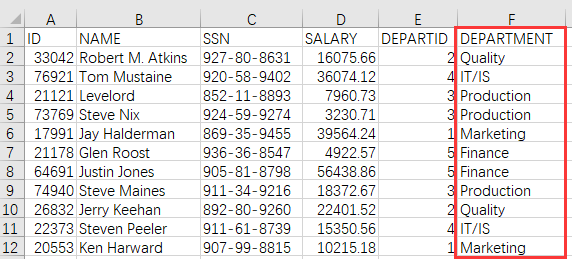
目标结果:
这是最简单的关联,采用 vlookup 函数可以实现,但仍有些注意事项。vlookup 函数在做查找时,必须清楚地知道要返回列和查找列的相对位置,如果中间插入删除了列,就需要调整公式;而且还要求被查找列必须位于区域的首列,当返回列在查找列的前面时,要对数据列先做次序调整才能用。
SPL 按列名访问,没有这些问题:
| A | B | |
| 1 | =file("salary.xlsx").xlsimport@t() | /导入第一页的带标题工资表 |
| 2 | =file("salary.xlsx").xlsimport@t(;"DEPARTMENT") | /导入 DEPARTMENT 工作页的部门表 |
| 3 | =A1.join(DEPARTID,A2:ID,DEPARTMENT) | /采用序表外键关联方法,用工资表的 DEPARTID 字段关联部门表 (A2) 的 ID,并选出 DEPARTMENT 字段 |
| 4 | =file("out.xlsx").xlsexport@t(A3) | /将关联好的结果写出到另一文件 |
二、多列匹配
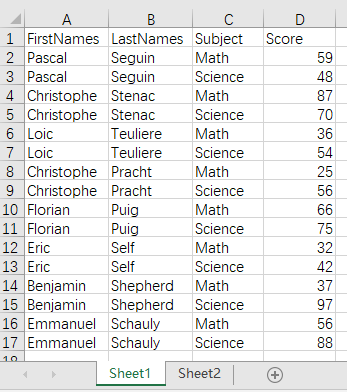
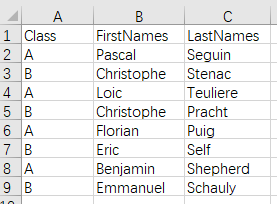
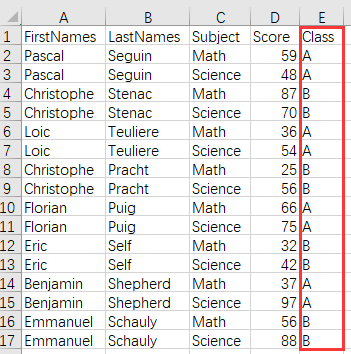
如果获取到的文件数据中不包含某种 ID 主键时,则需要根据多个列来做匹配。如下的学生成绩单,学生的姓和名是分开的列。现在需要根据姓和名,查找出每个学生的所属班级,以方便根据班级统计各班的成绩。
文件 scores.xlsx 中数据如下:
目标结果:
使用 vlookup 函数时,被查找的数据必须位于指定范围的第一列,也就是次序很重要,且一次只能查找一个值。像这样的多列匹配,没法直接使用 vlookup,需要过渡的办法。比如将要查找的列用 textjoin 合并到一个辅助列,目的表也得做同样的合并。最后再通过辅助列来查找,而这些查找前的准备工作,使得复杂度又更上一层楼。
SPL 不需要构成中间辅助列,直接用多个查找列名即可:
| A | B | |
| 1 | =file("scores.xlsx").xlsimport@t() | /导入第一页的带标题分数表 |
| 2 | =file("scores.xlsx").xlsimport@t(;"Sheet2") | /导入 Sheet2 工作页的班级表 |
| 3 | =A1.join(FirstNames:LastNames,A2:FirstNames:LastNames,Class) | /采用序表外键关联方法,用分数表的 FirstNames 和 LastNames 字段关联班级表的对应字段,并选出 Class 字段 |
| 4 | =file("out.xlsx").xlsexport@t(A3) |
三、一对一的匹配
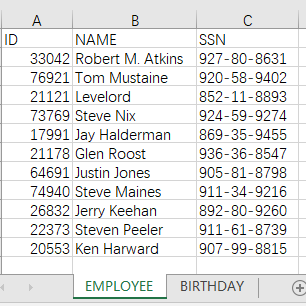
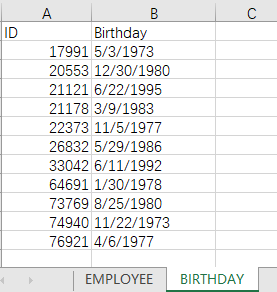
一个宽表的字段过多时,为了存储以及检索效率,往往需要将字段拆分到主键相同的多个小表中。如下的职员表跟生日表都是小表,现在需要通过 ID 字段来关联,方便查看员工的整体信息。
文件 employee.xlsx 中数据如下:
目标结果:

采用 vlookup 处理一对一关联时,复杂度跟前面的多对一是一样的,仍然有位置问题。但一对一关联的表有时会多于两个时,vlookup 函数没法同时处理多个表关联,只能一个一个来,稍显繁琐。
SPL 可以一次处理多个表和多个关联列:
| A | B | |
| 1 | =file("employee.xlsx").xlsimport@t() | /导入第一页的带标题员工表 |
| 2 | =file("employee.xlsx").xlsimport@t(;"BIRTHDAY") | /导入 BIRTHDAY 页的生日表 |
| 3 | =join(A1:Employee,ID;A2:Birthday,ID).new(Employee.ID,Employee.NAME,Employee.SSN,Birthday.Birthday) | /采用多序表关联,匹配两个表的 ID 字段后,并产生所需字段的新序表 |
| 4 | =file("out.xlsx").xlsexport@t(A3) |
注意跟前面的 A.join 不同,这里关联好的结果要用 new 方法选出关注的字段。
vlookup 只能依据左边的数据为准,即所谓的左连接,意思是当关联表数据有缺失(找不到可关联数据时)用空值填充。但一对一匹配时,我们有时还希望获得内连接和全连接的效果。所谓内连接,即指将关联不上的数据删除掉,只保证可以关联上的数据,如果用 vlookup 实现,就需要在关联后将有空值的数据行删除。而全连接是指如果被关联表有数据在关联表中找不到,也需要抄录过来,vlookup 无法直接实现了,只能分别做关联,然后合并,再去除重复数据,非常繁琐。
文件 employees.xlsx 中数据如下:
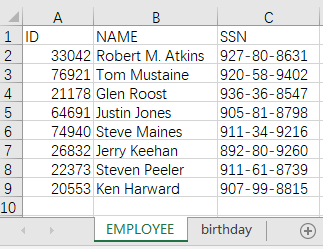
查看上面的数据,员工表缺失了21121,73769,17991;生日表缺失了 22373,26832。
左连接
现在要实现左连接,也即没填写生日的记录也保留,目标结果为:
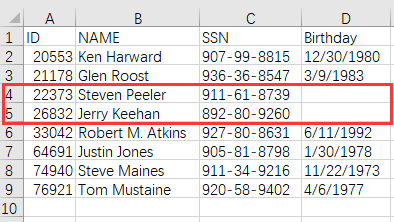
在 SPL 中实现左连接,只需加上选项 1。将上面代码中 A3 改为:
=join@1(A1:Employee,ID;A2:Birthday,ID).new(Employee.ID,Employee.NAME,Employee.SSN,Birthday.Birthda
内连接
join 函数缺省选项时,就是内连接,内连接仅包含两边都匹配的数据。
目标结果:
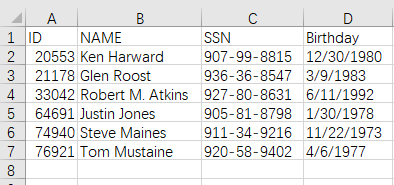
内连接时,A3 中 SPL 代码为:
=join(A1:Employee,ID;A2:Birthday,ID).new(Employee.ID,Employee.NAME,Employee.SSN,Birthday.Birthday)
右连接
也即保留所有生日表中的记录,目标结果为:

实现右连接,其实就是将源和目标对调后的左连接,注意右连接时,选出的 ID 号要从右表 Birthday 中获取,否则就为空了,所以 A3 中的 SPL 代码为:
=join@1(A2:Birthday,ID;A1:Employee,ID).new(Birthday.ID,Employee.NAME,Employee.SSN,Birthday.Birthday)
全连接
全连接相当于左右连接的并集,目标结果为:

全连接时,使用选项 f,注意此时的 ID 需要用表达式从非空的表中获取,所以 A3 中的 SPL 代码为:
=join@f(A2:Birthday,ID;A1:Employee,ID).new(if(Birthday==null,Employee.ID,Birthday.ID):ID,Employee.NAME,Employee.SSN,Birthday.Birthday)
四、一对多的匹配
业务场景中常见的订单,通常会是一个订单下面有多个明细。也就是这类匹配中的一条订单记录会对应多条明细记录,属于一对多的关联。如下的订单跟明细数据,现在需要将每个订单和明细用 OrderID 关联起来,方便用时间维度来统计订单的总额。
文件 orders.xlsx 的数据:
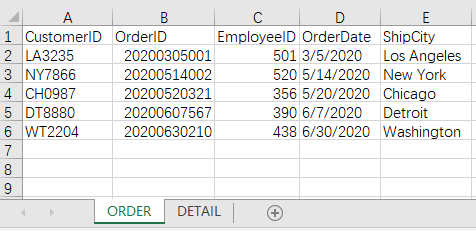
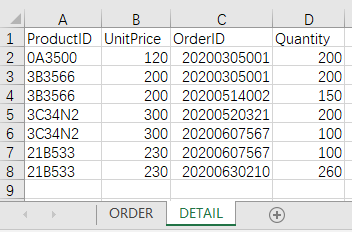
目标结果:
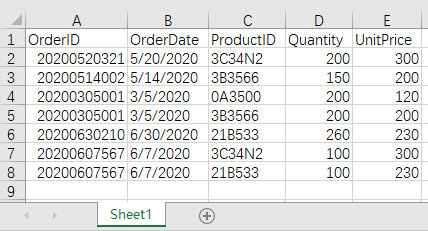
由于 vlookup 只能以左边数据为基准,而像这类一对多的关联,需要匹配后添加记录,所以没法实现左连接。而如果是做内连接的话,倒是可以将明细当源表,精确匹配后,再去掉订单为空的记录。又因为没法实现左连接,所以全连接也没法实现。
SPL 指定关联字段,不用考虑对应关系,便可关联:
| A | B | |
| 1 | =file("orders.xlsx").xlsimport@t() | /导入第一页的带标题订单表 |
| 2 | =file("orders.xlsx").xlsimport@t(;"DETAIL") | /导入 DETAIL 页的明细表 |
| 3 | =join(A1,OrderID;A2,OrderID).new(_1.OrderID,_1.OrderDate,_2.ProductID,_2.Quantity,_2.UnitPrice) | /关联相应字段,并选出关注的字段产生新序表 |
| 4 | =file("out.xlsx").xlsexport@t(A3) |
一对多和一对一的关联方法一样,也是用多表关联方法 join,且同样只需简单指定关联字段名,所以对于左连接、右连接等不同连接方式,都跟第三节一样,这里不再赘述。
五、非等值匹配
前面例子中,不管是哪种对应方式,都是根据条件相等去匹配。实际应用中,还有按非相等条件来匹配的情形。比如第二节中的成绩表,现在需要根据分数段来评级,此时没法直接用分数去目的表中做相等匹配。
评级数据表如下:
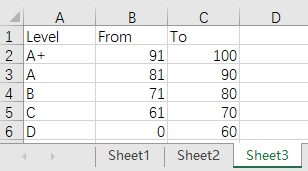
目标结果:
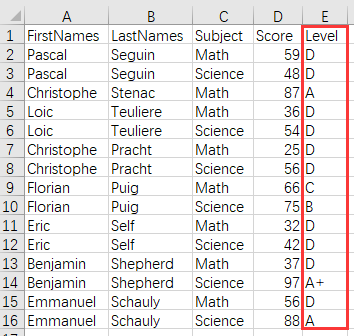
抛开关联的条件是按照相等还是范围来匹配,这种关联类似于第一节的多对一关联。用 vlookup 函数时,需要先将分段值按升序排好序,然后再用模糊匹配方式,来实现按范围匹配。
SPL 也提供了非等值连接:
| A | B | |
| 1 | =file("scores.xlsx").xlsimport@t() | /导入第一页的带标题成绩表 |
| 2 | =file("scores.xlsx").xlsimport@t(;"Sheet3") | /导入 Sheet3 页的评级表 |
| 3 | =xjoin(A1:Score;A2:Level,A2.From<Score.Score && Score.Score<A2.To) | /使用叉乘关联 xjoin,再用过滤条件留下符合要求的匹配 |
| 4 | =A3.new(Score.FirstNames,Score.LastNames,Score.Subject,Score.Score,Level.Level) | /匹配完成后,产生包含所需字段的新序表 |
| 5 | =file("out.xlsx").xlsexport@t(A4) |
可以使用完全叉乘方法 xjoin,然后再用过滤条件去掉不合要求的匹配。