参考自【数据挖掘与R语言】
rpart包可实现回归树。通常分为两步建立回归树:1.生成一棵较大的树 2.通过统计估计删除一些结点来对树进行修剪。
回归树基础实现
library(rpart)
rpart(y~.,data=data1) 参数形式与lm()函数的参数形式相同
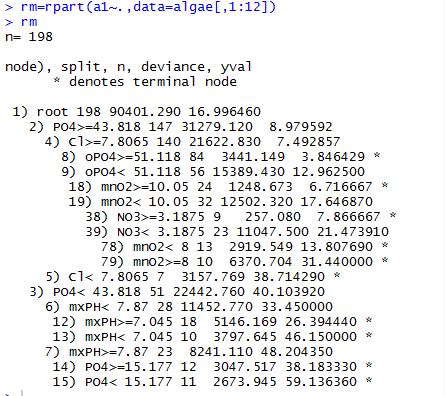
图形化展示:
plot(rm) text(rm)
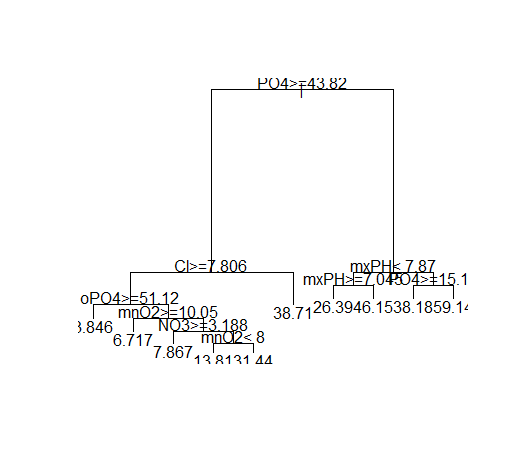
rpart()函数构建树时,满足下列条件,树构建过程将结束:
1、偏差的减少小于某一个给定界限值时;
2、当结点中的样本数量小于某个给定界限时;
3、当树的深度大于一个给定的界限值
这3个界限值由rpart()函数中的三个参数(cp、minsplit、maxdepth)来确定。默认值为0.01、20、30
修剪方法
rpart包中实现了一种复杂度损失修剪的修剪方法
这个方法使用R在每个树结点计算的参数值cp,这种修剪方法试图估计cp值以确保达到预测的准确性和树的大小之间的最佳折中。
可用printcp()函数可生成回归树的一些子树,并估计这些树的性能。
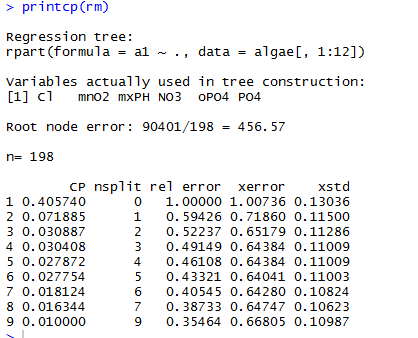
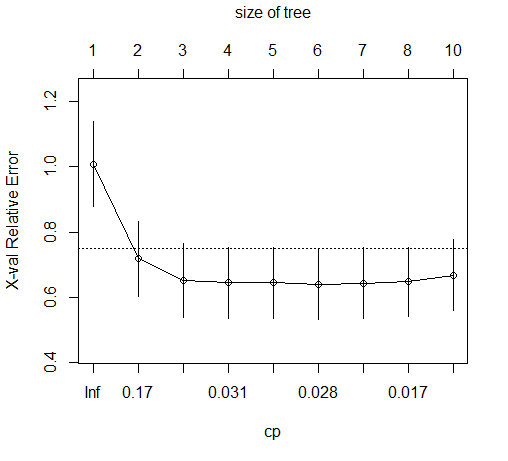
plotcp(rm)
由rpart()函数建立的回归树是上面列表中的最后一个树(树9)。这个树的cp值是0.01(cp的默认值),该树包括九个测试和一个相对误差值(与根结点相比)0.354。
R应用10折交叉验证的内部过程,评估该树的平均相对误差为0.70241+0.11523
根据这些更稳健的性能估计信息,可以避免过度拟合问题。
可以看到,8号树的预测相对误差(0.67733)最小。
选择好的回归树的准则:
1、以估计的cp值为准则;
2、1-SE规则;这包括检查交叉验证的估计误差(xerror列)以及标准误差(xstd列)。
在这个案例中,1-SE规则树是最小的树,误差小于0.67733+0.10892=0.78625,而由1检验的2号树的估计误差为0.73358.
若想要选择不是R建议的树,可通过使用不同的cp值来建立这棵树:
rm2=prune(rm,cp=0.08)
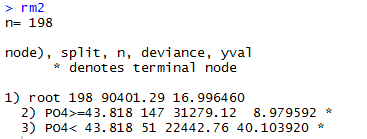
交互的对树进行修剪:snip.rpart()
两种方式:
1、指出需要修剪的那个地方的结点号(可以通过输出树对象来得到树的结点号),返回树对象
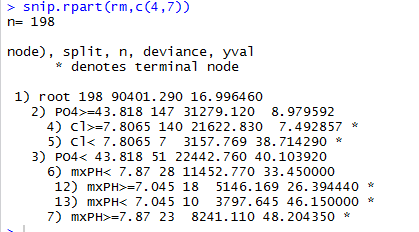
2、首先在图形窗口画出回归树,然后调用没有第二参数的函数。点击结点,即在这个结点对树进行修剪。可持续执行,直到右击结束。