(for pursue, do accumulation)
个人笔记,纯属佛系分享,如有错误,万望不吝赐教。
强化学习(Reinforcement Learning)是模仿人类的学习方式(比如,学习一种新的技能,从入门到掌握总是不断地去寻错,改正,直至完全掌握),强化学习的主要思想就是智能体在与环境的交互过程中不断调整,以达到理想结果。
1. 强化学习的框架
强化学习的流程如下图所示,智能体首先洞悉环境的当前状态,再根据状态做出相应的动作,环境会根据动作给出反馈到智能体,此时环境也会做出相应改变,智能体通过得到的反馈和改变后的状态进行做出下一次的动作,如此迭代,最后达到最优效果。
(Reinforcement learning is learning what to do--how to map situations to actions--so as to maximize a numerical reward signal.)
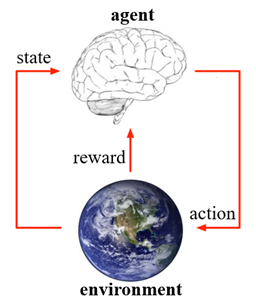
智能体(agent)是学习者和决策者,它能在某种程度上感知环境的状态,然后采取动作并影响环境的状态。
环境(environment)是强化学习问题中,除智能体以外与智能体交互的所有集合。
2. 强化学习的特点
强化学习两个最重要的特征就是“试错搜索(trial-and-error search)”和“延迟奖励(delayed reward)"。智能体不会被告知选择什么动作是最好的,而是需要通过尝试去发现哪些动作获得最大的奖励,而所执行的动作不但影响即时奖励,还可能使状态发生改变从而影响未来的奖励。因此,这给强化学习带来了一个独特的挑战:更新策略的过程是在探索(exploration)和开发(exploitation)之间权衡完成的。为了获得更多的奖励,智能体需要不断优化已经尝试过的动作,同时为了选取最优的动作,智能体还需要不断去尝试新的动作。强化学习还有一个特点,就是它需要明确考虑目标导向型智能体与不确定性环境交互的整体问题。
3. 强化学习的要素
上面框图展示了最简单的强化学习架构的三个基本要素,下面将具体讲述强化学习的几种要素的定义和作用:
状态(state),(S_t),表示环境在(t)时刻所处的状态(s)
动作(action),(A_t),表示智能体在(t)时刻采取的动作(a)
策略(policy),(pi(a|s)),表示智能体在给定时间(状态)下采取的行为方式,是环境状态到动作的映射,一般是随机函数,它是智能体的核心
奖励信号(reward signal),定义了强化学问题的目标,即环境会在每一个时间步长给智能体发送被称为“奖励(reward)”的标量信号,(R_t),它表示对智能体当前所执行策略的短期判断,而价值函数则是对智能体当前所执行的长期判断
环境模型(model of the environment),它是对外部环境运作规则的推断,它被用于规划(即在真正经历之前,先考虑未来所有可能的情况做出预先的决策)。强化学习的方法被分为两种:基于模型(model-based)的方法和不基于模型(model-free)的方法--基于模型方法是通过模型和规划解决实际问题,而无模型方法则通过试错的方式学习
4. 与其它学习方式的比较
区别于监督学习,监督学习是从外部监督者给出的带标签样本的训练集中学习,标签的实质就是先验知识,事先会告诉学习器什么是对什么是错,而强化学习只有奖励值,这与监督学习的输出不同,它是延迟给出的,这导致了智能体必须能够从自身的经验中学习。
区别于无监督学习,无监督学习是从无标签数据集中寻找隐藏的相似结构,无监督学习没有输出值,只有数据特征,而强化学习的目的是最大化奖励信号。
监督学习和无监督学习,它们的样本数据一般都是相互独立的,而强化学习每个时间步长得到的序列是迭代更新的,数据间的关联十分紧密。
(转载请注明出处:https://www.cnblogs.com/HughCai/p/12671340.html)
References
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction (Second Edition). Cambridge, Massachusetts London, England : The MIT Press, 2018.
Csaba Szepesvári, ‘Algorithms for Reinforcement Learning’, Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 4, no. 1, pp. 1–103, Jan. 2010, doi: 10.2200/S00268ED1V01Y201005AIM009.
UCL Reinforcement Learning Course by David Silver:https://www.bilibili.com/video/BV1b7411y7ax