算术编码例题:
假设信源信号有{A, B, C, D}四个,他们的概率分别为{0.1, 0.4, 0.2, 0.3},如果我们要对CADACDB这个信号进行编码,那么应该怎样进行呢?
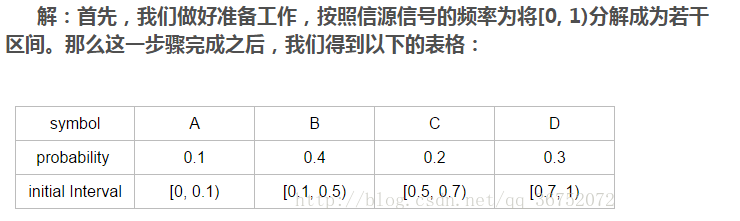
准备工作完成之后,我们便可以开始进行编码了。
那么我们首先读入信号:C——因为C在最初始的间隔中是[0.5, 0.7),所以读入C之后我们的编码间隔就变成[0.5, 0.7)了;
紧接着,我们读入的是A,A在初始区间内是占整个区间的前10%,因此对应这个上来也是需要占这个编码间隔的前10%,因此编码区间变为:[0.5, 0.52)了;
再然后是D,因为D占整个区间的70% ~ 100%,所以也是占用这个编码区间的70% ~ 100%,操作后的编码区间为[0.514, 0.52)
……
直到最后将信号量全部读出。
最后,我们将这个操作过程绘制成为一张表: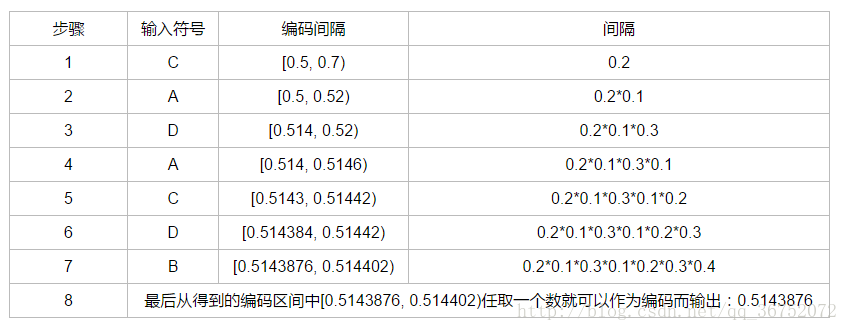
解码例题:
假设信源信号有{A, B, C, D}四个,他们的概率分别为{0.1, 0.4, 0.2, 0.3},当我们得到的编码是0.5143876的时候,问原始的信号串(7位)是怎样的?

准备工作完成之后,我们现在开始解码:
我们发现,待解码的数据0.5143876在[0.5, 0.7)内,因此,我们解出的第一个码值为C
同理,我们继续计算0.5143876处于[0.5, 0.7)的第一个10%内因此解出的第二个码值为A
……
这个过程持续直到执行七次全部执行完为止。
那么以上的过程我们同样可以列表表示: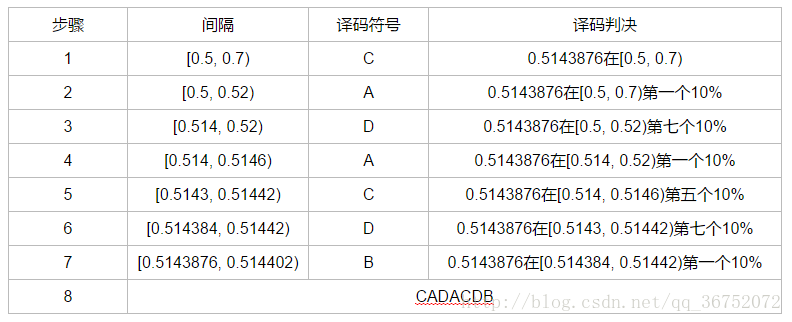
作业:对任一概率序列,实现算术编码,码长不少于16位,不能固定概率,语言自选。
基于Python实现:


from collections import Counter #统计列表出现次数最多的元素 import numpy as np print("Enter a Sequence ") inputstr = input() print (inputstr + " ") res = Counter(inputstr) #统计输入的每个字符的个数,res是一个字典类型 print (str(res)) # print(res) #sortlist = sorted(res.iteritems(), lambda x, y : cmp(x[1], y[1]), reverse = True) #print sortlist M = len(res) #print (M) N = 5 A = np.zeros((M,5),dtype=object) #生成M行5列全0矩阵 #A = [[0 for i in range(N)] for j in range(M)] reskeys = list(res.keys()) #取字典res的键,按输入符号的先后顺序排列 # print(reskeys) resvalue = list(res.values()) #取字典res的值 totalsum = sum(resvalue) #输入一共有几个字符 # Creating Table A[M-1][3] = 0 for i in range(M): A[i][0] = reskeys[i] #第一列是res的键 A[i][1] = resvalue[i] #第二列是res的值 A[i][2] = ((resvalue[i]*1.0)/totalsum) #第三列是每个字符出现的概率 i=0 A[M-1][4] = A[M-1][2] while i < M-1: #倒数两列是每个符号的区间范围,与输入符号的顺序相反 A[M-i-2][4] = A[M-i-1][4] + A[M-i-2][2] A[M-i-2][3] = A[M-i-1][4] i+=1 print (A) # Encoding print(" ------- ENCODING ------- " ) strlist = list(inputstr) LEnco = [] UEnco = [] LEnco.append(0) UEnco.append(1) for i in range(len(strlist)): result = np.where(A == reskeys[reskeys.index(strlist[i])]) #满足条件返回数组下标(0,0),(1,0) addtollist = (LEnco[i] + (UEnco[i] - LEnco[i])*float(A[result[0],3])) addtoulist = (LEnco[i] + (UEnco[i] - LEnco[i])*float(A[result[0],4])) LEnco.append(addtollist) UEnco.append(addtoulist) tag = (LEnco[-1] + UEnco[-1])/2.0 #最后取区间的中点输出 LEnco.insert(0, " Lower Range") UEnco.insert(0, "Upper Range") print(np.transpose(np.array(([LEnco],[UEnco]),dtype=object))) #np.transpose()矩阵转置 print(" The Tag is ") print(tag) # Decoding print(" ------- DECODING ------- " ) ltag = 0 utag = 1 decodedSeq = [] for i in range(len(inputstr)): numDeco = ((tag - ltag)*1.0)/(utag - ltag) #计算tag所占整个区间的比例 for i in range(M): if (float(A[i,3]) < numDeco < float(A[i,4])): #判断是否在某个符号区间范围内 decodedSeq.append(str(A[i,0])) ltag = float(A[i,3]) utag = float(A[i,4]) tag = numDeco print("The decoded Sequence is ") print("".join(decodedSeq))
参考: