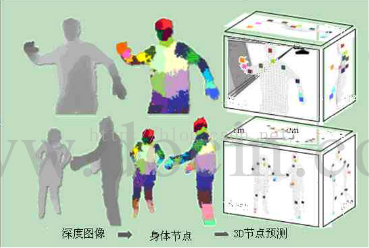
步骤1获取深度图
Kinect-V1(一款热门的RGBD相机):一种获得物体深度和位置的方法:激光(光栅)+相机(结构光)
- 本质:光栅通过激光对整个测量空间进行编码(不同位置对应不同的激光图案,因为不同位置上激光通过光栅投射在目标物体上成像,在其上产生的图样会产生偏移),然后用红外相机拍摄下空间图片,对图案进行解码得到深度信息
存在的问题:深度传感器通常仅限于室内环境,并且具有自己的3D重建问题。
Kinect-V2体感游戏获取深度图原理:
- 直接发射特殊红外线,然后再接收反射信号通过相位差,直接得到深度信息
步骤2分割深度图中的人体前景
追踪场景中的人,利用图像分割的思想用分割遮罩,只给下一步处理传送人体图像的前景深度图
步骤3训练分类器识别身体部位
最后机器学习分析每个部位(一段,比如头部,大臂,小臂,大腿,小腿)是什么,
步骤4根据关节点生成骨架
根据步骤3得到20个关节点生成骨架系统
模型的关节点输出包括三类
- 1模型直接确定的推断结果
- 2模型根据1推理得到的合理结果
- 3未识别到的部分