IO流

IO类中常用的类
5个类(File、OutputStream、InputStream、Writer、Reader)和1个接口(Serializable)
-
File(文件特征与管理):用于文件或者目录的描述信息,例如生成新目录,修改文件名,删除文件,判断文件所在路径等。
-
InputStream(二进制格式操作):抽象类,基于字节的输入操作,是所有输入流的父类。定义了所有输入流都具有的共同特征。
-
OutputStream(二进制格式操作):抽象类。基于字节的输出操作。是所有输出流的父类。定义了所有输出流都具有的共同特征。
4.Reader(文件格式操作):抽象类,基于字符的输入操作。
-
Writer(文件格式操作):抽象类,基于字符的输出操作。
-
RandomAccessFile(随机文件操作):一个独立的类,直接继承至Object.它的功能丰富,可以从文件的任意位置进行存取(输入输出)操作。
两个定义
流:代表任何有产出数据的数据源对象或者接受数据的接收端对象
流的本质:将数据传输特性抽象为各种类,方便直观的进行数据操作
Java IO所采用的模型
Java的IO模型设计非常优秀,它使用Decorator(装饰者)模式,按功能划分Stream,您可以动态装配这些Stream,以便获得您需要的功能。
例如,您需要一个具有缓冲的文件输入流,则应当组合使用FileInputStream和BufferedInputStream。
IO流的分类
· 根据处理数据类型的不同分为:字符流和字节流
· 根据数据流向不同分为:输入流和输出流
· 按数据来源(去向)分类:
1、File(文件): FileInputStream, FileOutputStream, FileReader, FileWriter
2、byte[]:ByteArrayInputStream, ByteArrayOutputStream
3、Char[]: CharArrayReader,CharArrayWriter
4、String:StringBufferInputStream, StringReader, StringWriter
5、网络数据流:InputStream,OutputStream, Reader, Writer
** 字符流和字节流**
流序列中的数据既可以是未经加工的原始二进制数据,也可以 是经一定编码处理后符合某种格式规定的特定数据。因此Java 中的流分为两种:
1) 字节流:数据流中最小的数据单元是字节
2) 字符流:数据流中最小的数据单元是字符, Java中的字符是Unicode编码,一个字符占用两个字节。
特性
相对于程序来说,输出流是往存储介质或数据通道写入数 据 而输入流是从存储介质或数据通道中读取数据,一般 来说关于流的特性有下面几点:
1、先进先出,最先写入输出流的数据最先被输入流读取到。
2、顺序存取,可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile可以从文件的任意位置进行存取(输入输出)操作)
3、只读或只写,每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
Java IO流的对象
1.输入字节流InputStream

1. InputStream是所有的输入字节流的父类,它是一个抽象类。
-
ByteArrayInputStream、StringBufferInputStream(上图的StreamBufferInputStream)、FileInputStream是三种基本的介质流,它们分别从Byte数组、StringBuffer、和本地文件中读取数据。
-
PipedInputStream是从与其它线程共用的管道中读取数据.
-
ObjectInputStream和所有FilterInputStream的子类都是装饰流(装饰器模式的主角)。
2.输出字节流OutputStream
IO 中输出字节流的继承图可见上图,可以看出:
-
OutputStream是所有的输出字节流的父类,它是一个抽象类。
-
ByteArrayOutputStream、FileOutputStream是两种基本的介质流,它们分别向Byte数组、和本地文件中写入数据。PipedOutputStream是向与其它线程共用的管道中写入数据。
-
ObjectOutputStream和所有FilterOutputStream的子类都是装饰流。
4.字符输出流Writer
-
Writer是所有的输出字符流的父类,它是一个抽象类。
-
CharArrayWriter、StringWriter是两种基本的介质流,它们分别向Char数组、String中写入数据。PipedWriter是向与其它线程共用的管道中写入数据,
-
BufferedWriter是一个装饰器为Writer提供缓冲功能。
-
PrintWriter和PrintStream极其类似,功能和使用也非常相似。
-
OutputStreamWriter是OutputStream到Writer转换的桥梁,它的子类FileWriter其实就是一个实现此功能的具体类(具体可以研究一SourceCode)。功能和使用和OutputStream极其类似.
-




字节流和字符流的区别(重点)
字节流没有缓冲区,是直接输出的,而字符流是输出到缓冲区的。因此在输出时,字节流不调用colse()方法时,信息已经输出了,而字符流只有在调用close()方法关闭缓冲区时,信息才输出。要想字符流在未关闭时输出信息,则需要手动调用flush()方法。
· 读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
· 处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
结论:只要是处理纯文本数据,就优先考虑使用字符流。除此之外都使用字节流。
File类
File类的操作包括文件的创建、删除、重命名、得到路径、创建时间等,以下是文件操作常用的函数。

File类是对文件系统中文件以及文件夹进行封装的对象,可以通过对象的思想来操作文件和文件夹。File类保存文件或目录的各种元数据信息,包括文件名、文件长度、最后修改时间、是否可读、获取当前文件的路径名,判断指定文件是否存在、获得当前目录中的文件列表,创建、删除文件和目录等方法。
构造函数:
1)File (String pathname)
例:File f1=new File("FileTest1.txt"); //创建文件对象f1,f1所指的文件是在当前目录下创建的FileTest1.txt
2)File (String parent , String child)
例:File f2=new File(“D:dir1","FileTest2.txt") ;// 注意:D:dir1目录事先必须存在,否则异常
3)File (File parent , String child)
例:File f4=new File("dir3");
File f5=new File(f4,"FileTest5.txt"); //在如果 dir3目录不存在使用f4.mkdir()先创建
一个对应于某磁盘文件或目录的File对象一经创建, 就可以通过调用它的方法来获得文件或目录的属性。
1)public boolean exists( ) 判断文件或目录是否存在
2)public boolean isFile( ) 判断是文件还是目录
3)public boolean isDirectory( ) 判断是文件还是目录
4)public String getName( ) 返回文件名或目录名
5)public String getPath( ) 返回文件或目录的路径。
6)public long length( ) 获取文件的长度
7)public String[ ] list ( ) 将目录中所有文件名保存在字符串数组中返回。 File类中还定义了一些对文件或目录 进行管理、操作的方法,常用的方法有:
1) public boolean renameTo( File newFile ); 重命名文件
2) public void delete( ); 删除文件
3) public boolean mkdir( ); 创建目录
1. public class FileDemo1 {
2. public static void main(String[] args) {
3. File file = new File("D:" + File.separator + "test.txt");
4. if (file.exists()) {
5. file.delete();
6. } else {
7. try {
8. file.createNewFile();
9. } catch (IOException e) {
10. // TODO Auto-generated catch block
11. e.printStackTrace();
12. }
13. }
14. }
15. }
集合类(List,Set,Map……)
概述
· List , Set, Map都是接口,前两个继承至Collection接口,Map为独立接口
· Set下有HashSet,LinkedHashSet,TreeSet
· List下有ArrayList,Vector,LinkedList
· Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
· Collection接口下还有个Queue接口,有PriorityQueue类
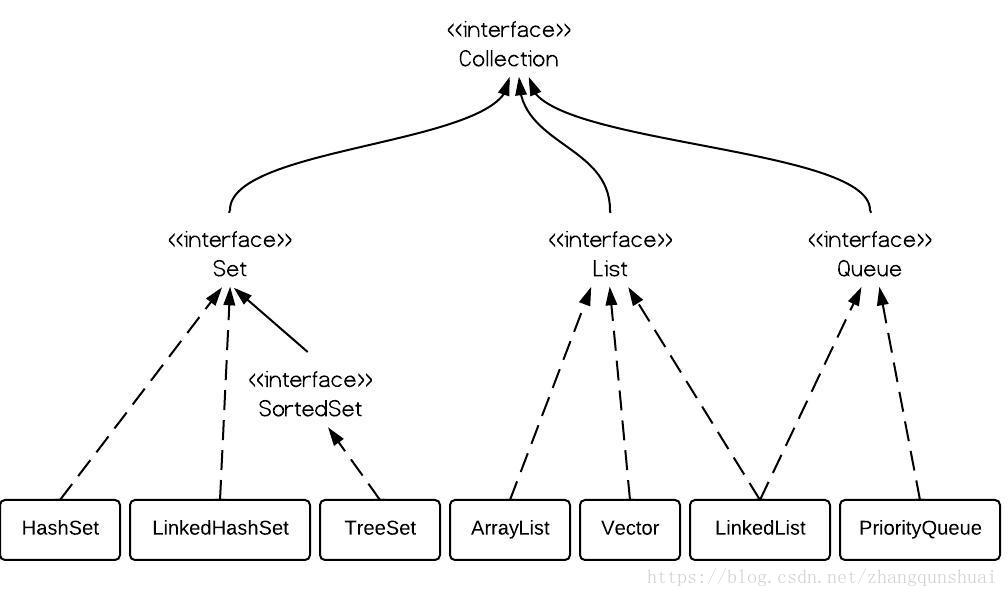
SortedSet是个接口,它里面的(只有TreeSet这一个实现可用)中的元素一定是有序的。
— List 有序,可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
—Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
- 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
—Map
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
TreeMap
是有序的,HashMap和HashTable是无序的。
Hashtable
方法是同步的,HashMap的方法不是同步的。这是两者最主要的区别。
这就意味着:
HashTable是线程安全的,HashMap不是线程安全的。
HashMap效率较高,Hashtable效率较低。
如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap。 查看Hashtable的源代码就可以发现,除构造函数外,Hashtable的所有 public 方法声明中都有 synchronized关键字,而HashMap的源码中则没有。
Hashtable不允许null值,HashMap允许null值(key和value都允许)
父类不同:Hashtable的父类是Dictionary,HashMap的父类是AbstractMap
重点问题
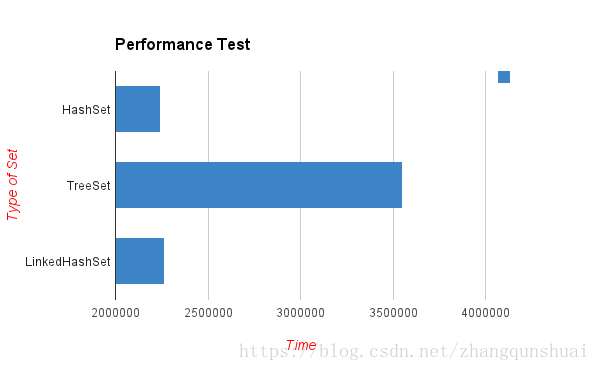
1.区分TreeSet · LinkedHashSet · HashSet
· TreeSet的主要功能用于排序
· LinkedHashSet的主要功能用于保证FIFO即有序的集合(先进先出)
· HashSet只是通用的存储数据的集合
· HashSet插入数据最快,其次LinkHashSet,最慢的是TreeSet因为内部实现排序