一、Hibernate简介(网上搜的,理解性地看看)
1.概念:Hibernate是持久层(数据访问层)的框架,对JDBC进行了封装,是对数据库访问提出的面向对象的解决方案。
2.作用:使用Hibernate可以直接访问对象,Hibernate自动将访问转换成SQL执行,从而实现简介访问数据库的目的,简化了数据访问层的代码开发。
3.JDBC、MyBatis对比:
a)JDBC需要编写大量SQL语句,以及对大量参数赋值。需要手动将ResultSet结果集转换成实体对象;SQL中包含特有函数,无法移植。而Hibernate可以自动生成SQL和参数赋值,自动将ResultSet结果集转换成实体对象,采用一致的方法对数据库操作,移植性好。
b)MyBatis与Hibernate都对JDBC进行了封装,采用ORM思想解决了Entity和数据库的映射问题。MyBatis采用SQL与Entity映射,对JDBC封装程度比较轻,需要自己写SQL,更具有灵活性;而Hibernate采用数据库与Entity映射,对JDBC封装程度比较重,自动生成SQL,对于基本的操作,开发效率高。
4.原理:Hibernate框架是ORM思想的一种实现,解决了对象和数据库映射问题。我们可以通过Hibernate提供的一系列API,允许我们直接访问实体对象,然后其根据ORM映射关系,转换成SQL并且执行,从而达到访问数据库的目的。
ORM:Object Relation Mapping,即对象关系映射,指Java对象和关系数据库之间的映射。
ORM思想:将对象与数据库数据进行相互转换的思想,不同的框架实现ORM的手段不同,但更多的是采用配置+反射的方式来实现ORM。
5.框架体系结构
a)主配置文件,通常为“hibernate.cfg.xml”,用于配置数据库连接参数,框架参数,已经映射关系文件。
b)实体类,与数据库对应的Java类型,用于封装数据库记录的对象类型。
c)映射关系文件,通常为“实体类.hbm.xml”,并放置在与实体类相同的路径下。该文件是指定实体类和数据库的对应关系,以及类中属性和表中字段之间的对应关系。
d)底层API,对映射关系文件的解析,根据解析出来的内容,动态生成SQL语句,自动将属性和字段映射。
二、Hibernate使用
1.常用API
Configuration:负责加载主配置文件信息,同时加载映射关系文件信息
/**
到src下找到名称为hibernate.cfg.xml的配置文件,创建对象,把配置文件放到对象中(加载核心配置文件)
*/
Configuration cfg = new Configuration().configure();
//加载指定的核心配置文件
Configuration cfg = new Configuration().configure("com/konrad/hibernate.cfg.xml");
//加载指定的映射配置文件
cfg.addResource("com/konrad/entity/User.hbm.xml");

SessionFactory:负责创建Session对象,根据核心配置文件的配置,在数据库创建对应的表,一个项目只应有一个此对象
private static final SessionFactory sessionFactory;
static{
try{
//配置文件的方式
sessionFactory = new Configuration().configure("hibernate.cfg.xml")
.buildSessionFactory();
/* 注解的方式
sessionFactory = new AnnotationConfiguration().configure().buildSessionFactory();
*/
}catch (Throwable ex){
ex.printStackTrace();
throw new ExceptionInInitializerError(ex);
}
}
Session:数据库连接会话,负责执行增删改操作
Transaction:负责事务控制
Query:负责执行特殊查询
2.使用步骤
a)导入Hibernate包,以及数据库驱动包。(开发需要的包不知道的自行百度,也可以通过Maven构建)
b)引入Hibernate主配置文件hibernate.cfg.xml
- <session-factory>标签要写在<hibernate-configuration>标签内部
c)创建实体类
d)创建映射关系文件(也可以通过注解的方式进行映射,这样就不需要xml映射文件)
- <class>标签中的name属性写的是类的全路径
- <id>和<property>标签中的name属性写的是实体类中的属性名称
- <id>和<property>标签中,column可以省略,若省略就是以name属性值生成表的字段名
- <property>标签中还有一个type属性,用于生成表的字段的类型,但是使用比较少
e)使用Hibernate API执行增删改查等操作
f)额外说明:注解方式的应用
- 如果实体类属性名与表字段名称不同时,要么都注解在属性前,要么都注解在get方法前。
- 如果实体类属性名和表字段名称统一,可以部分注解在属性前,部分注解在get方法前。
- 若都不注解,则默认表字段名和属性名一致
- 若实体类中某个属性不需要存进数据库表,使用@Transient进行注解即可
- 表名称可以在实体类前进行注解
- 所有注解都在javax.persistence包下
3.映射类型
a)Java类型:映射关系文件中,配置属性和字段关系时,可以在type属性上指定Java类型,用于做Java属性和数据库字段的转换。指定时需要完整的类型名,如java.lang.String。
b)自定义类型:当某些特殊类型,Java预置类型无法支持,需要自定义一个类来实现,这个类要求实现接口UserType。比如boolean类型,数据库中一般存char(1),存y/n或者t/f,Java预置类型无法支持boolean类型的配置,需要自定义。
c)Hibernate也提供了一些类型来支持这些映射,提供了7中映射类型,书写时全是小写。

三、Hibernate的主键生成方式
1.sequence:采用序列生成主键,适用于Oracle数据库。
<generator class="sequence">
<param name="sequence">序列名</param>
</generator>
2.identity:采用数据库自增长机制生成主键,适用于Oracle之外的其他数据库。
<generator class="identity"> </generator>
3.native:根据当前配置的数据库方言,自动选择sequence或者identity。
<generator class="native">
<param name="sequence">序列名</param>
</generator>
4.increment:不是采用数据库自身的机制来生成主键,而是Hibernate提供的一种生成主键的方式,它会获取当前表中主键的最大值,然后加1作为新的主键。PS:这种方式在并发量高时存在问题,可能会产生重复的主键,因此不推荐。
<generator class="increment"> </generator>
5.assigned:Hibernate不负责生成主键,需要程序员自己处理主键的生成。
<generator class="assigned"> </generator>
6.uuid/hilo:采用uuid或hilo算法生成一个主键值,这个主键值是一个不规则的长数字。PS:这个方式生成的主键可以保证不重复,但是没有规律,因此不能按主键排序。
<generator class="uuid"> </generator>
四、一些使用的代码实例
1.核心配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 配置数据库信息 必须的 -->
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/test</property>
<property name="connection.username">root</property>
<property name="connection.password"></property>
<property name="javax.persistence.validation.mode">none</property>
<!-- 支持mysql方言 -->
<property name="dialect">org.hibernate.dialect.SQLServerDialect</property>
<property name="current_session_context_class">thread</property>
<!-- 配置是否在控制台显示sql语句 -->
<property name="show_sql">true</property>
<!-- 配置是否按照格式显示sql语句 -->
<property name="format_sql">true</property>
<!-- 配置生成策略
update:如果没有表创建之,有表就更新表
-->
<property name="hbm2ddl.auto">update</property>
<!-- 引入映射配置文件 必须的 -->
<mapping resource="com/maven/test/hibernate/entity/PersonEntity.hbm.xml"/>
<!-- 若使用注解的方式,需要如下配置 -->
<!-- <mapping class="com.maven.test.hibernate.entity.PersonEntity">-->
</session-factory>
</hibernate-configuration>
2.关系映射XML文件dtd约束:
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
3.HibernateUtil类:提供获取Session和关闭Session的方法。Hibernate中我们使用ThreadLocal管理Session。
package com.maven.test.hibernate.util;
import org.apache.log4j.Logger;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateUtil {
public static final ThreadLocal<Session> SESSIONMAP = new ThreadLocal<Session>();
private static final SessionFactory sessionFactory;
private static final Logger LOGGER = Logger.getLogger(HibernateUtil.class);
static{
try{
LOGGER.debug("HibernateUtil.static - loading config");
sessionFactory = new Configuration().configure("hibernate.cfg.xml")
.buildSessionFactory();
LOGGER.debug("HibernateUtil.static - end");
}catch (Throwable ex){
ex.printStackTrace();
LOGGER.error("HibernateUtil error: ExceptionInInitializerError");
throw new ExceptionInInitializerError(ex);
}
}
private HibernateUtil(){}
public static Session getSession() throws HibernateException{
Session session = SESSIONMAP.get();
if(session == null){
session = sessionFactory.openSession();
SESSIONMAP.set(session);
}
return session;
}
public static void closeSession() throws HibernateException{
Session session = SESSIONMAP.get();
SESSIONMAP.set(null);
if(session != null)
session.close();
}
}
4.添加操作
PersonEntity person = new PersonEntity();
person.setId(100);
person.setName("Konrad");
Session session = HibernateUtil.getSession();
Transaction tx = session.beginTransaction();
session.save(person);
tx.commit();
HibernateUtil.closeSession();
5.删除操作
Session session = HibernateUtil.getSession(); session.beginTransaction(); PersonEntity person = session.get(PersonEntity,class, 1); session.delete(person); session.getTransaction().commit(); HibernateUtil.closeSession();
6.查询操作
Session session = HibernateUtil.getSession();
session.beginTransaction();
//单行查询,根据主键查询
PersonEntity p = session.get(PersonEntity.class, 1)
//多行查询
@SuppressWarnings("unchecked")
List<PersonEntity> personList = session.createQuery("select p from PersonEntity p").list();
for(PersonEntity person : personList){
System.out.println(person);
}
session.getTransaction().commit();
HibernateUtil.closeSession();
7.修改操作
Session session = HibernateUtil.getSession();
session.beginTransaction();
PersonEntity person = session.get(PersonEntity.class, 1);
person.setName("haha");
session.update(person);
session.getTransaction().commit();
HibernateUtil.closeSession();
五、Hibernate进阶
1.一级缓存
a)Hibernate创建每个Session对象时,都会给该Session对象分配一块独立的缓存区,用于存放该Session查询出来的对象,这个分配给Session的缓存区称之为一级缓存,也叫Session级缓存。Session的save、update、delete操作会触发缓存更新。
b)使用一级缓存的原因是,Session取数据时,会优先向缓存区取数据,如果存在数据则直接返回,不存在才会去数据库查询,从而降低了数据库访问次数,提升代码性能。
c)一级缓存是默认开启的,使用Hibernate API查询时会自动使用。
d)session.evict(obj) - 将obj从一级缓存中移除
session.clear() - 清除一级缓存中所有的obj
session.close() - 关闭session,释放缓存空间
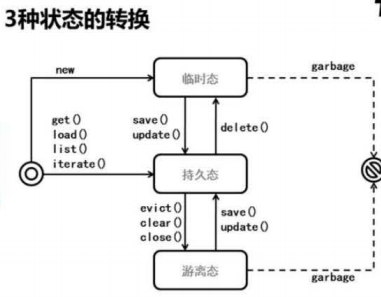
2.Hibernate中,实体对象的3中状态:临时态、持久态、游离态
a)临时态:临时态的对象可以被垃圾回收,未进行持久化,未与session关联
- 通过new创建的对象为临时态
- 通过delete方法操作的对象将转变为临时态
b)持久态:持久态对象垃圾回收器不能回收,进行了持久化,与session关联。实际上持久态对象存在于session缓存中,由session负责管理;持久态对象的数据可以自动更新到数据库中,在调用session.flush()时执行,而提交事务时会使用session.flush(),因此提交事务也会触发同步
- 通过get、load、list、iterate方法查询到的对象为持久态
- 通过save、update方法操作的对象转变为持久态
c)游离态:游离态的对象可以被垃圾回收,进行过持久化,但已与session解除了关联
- 通过session的evict、clear、close方法操作的对象会转变为游离态
3.延迟加载
a)使用某些Hibernate方法查询数据时,Hibernate返回的只是一个空对象(除id外属性都为null),并没有真正查询数据库。而在使用这个对象时才会触发查询数据库,并将查询到的数据注入到这个空对象中,这种将查询时机制推迟到对象访问时的机制称之为延迟加载。
b)延迟加载可以提升内存资源的使用率,降低对数据库的访问次数。
c)session.load()、query.iterate()、关联映射中对关联属性的加载,以上属于采用延迟加载的方法。
d)采用具有延迟加载机制的操作,需要避免session提前关闭。
4.关联映射
a)关联映射即使用Hibernate操作一张表时,它可以通过配置关系自动地帮助我们操作另一张表
b)关联查询出关系表的数据、关联新增/修改关系表的数据、关联删除关系表的数据
c)类型:一对多关联、多对一关联、多对多关联、一对一关联、继承关联
一对多关联实现步骤:
- 在“一”方实体类添加集合属性,以及get、set方法
- 在“一”方hbm文件中配置关联关系
<!--
set指定属性类型为Set集合
name指定属性名
-->
<set name="courses">
<!-- column指定了关联字段名-->
<key column="stu_id"/>
<!-- one-to-many指定了关联关系,class指定了另一方类型-->
<one-to-many class="com.konrad.entity.Course" />
</set>
多对一关联实现步骤:
- 在“多”方实体类添加属性,以及get、set方法
- 在“多”方hbm文件中配置关联关系
<!-- many-to-one指定了关联关系, name指定了属性名, column指定了关系字段, class指定了另一方类型--> <many-to-one name="student" column="stu_id" class="com.konrad.entity.Student" />
多对多关联实现步骤:
- 在双方方实体类添加集合属性,以及get、set方法
- 在双方hbm文件中配置关联关系
Student映射配置文件
<!-- 配置学生对应的教师集合 name属性:配置教师实体类中的Set集合属性的名称 table属性:表示中间表的名称 --> <set name="teachers" table="t_stu_tea"> <!-- column属性:配置当前映射文件在中间表中外键名称 --> <key column="sid"></key> <!-- class属性:配置另一个张表的实体类全路径名称 colunm属性:配置一张表在中间表中的外键名称 --> <many-to-many class="cn.konrad.entity.Teacher" column="tid"></many-to-many> </set>
Teacher映射配置文件
<!--
配置教师对应的学生集合
name属性:配置学生实体类中的Set集合属性的名称
table属性:中间表的名称
-->
<set name="students" table="t_stu_tea">
<!-- column属性:配置当前映射文件在中间表中外键名称 -->
<key column="tid"></key>
<!--
class属性:配置另一个张表的实体类全路径名称
colunm属性:配置一张表在中间表中的外键名称
-->
<many-to-many class="cn.konrad.entity.Student" column="sid"></many-to-many>
</set>
一对一关联实现步骤:
- 在双方方实体类添加属性,以及get、set方法
- 在双方hbm文件中配置关联关系
Wife映射关系文件
<!-- property-ref属性:指定使用被关联实体主键以外的字段作为关联字段 --> <one-to-one name="husband" class="cn.konrad.entity.Husband" property-ref="wife"></one-to-one>
Husband映射配置文件
<id name="hid" column="hid">
<!-- 2.1配置主键的策略
foreign属性:表示主键参照外键生成
-->
<generator class="foreign">
<!-- param标签配置当前实体类中引用的对方实体对象的引用名 -->
<param name="property">wife</param>
</generator>
</id>
<!-- 3.配置实体类与表的其他属性
name属性:实体类的属性名称
column属性:表中的列名
Contrained=true表示生产外键
-->
<property name="hname" column="hname"></property>
<one-to-one name="wife" class="cn.konrad.entity.Wife" constrained="true"></one-to-one>
5.关联操作
a)默认情况下,关联属性时采用延迟加载机制加载的,可以通过映射关系文件中关联属性配置标签中的lazy属性进行修改,true/false。
b)通过一个连接查询一次性取出2张表的数据,避免2次查询。在关联属性标签上通过fetch属性进行设置,称之为抓取策略。“join”表示查询时使用连接查询,一起把对方数据抓取过来;“select”表示查询时不使用连接查询,是默认情况。当fetch为“join”时,关联属性的延迟加载失效。
6.级联操作:通过关联映射,在对一方进行增删改时,连带增删改关联的另一方数据
a)实现级联添加/修改,需要在映射关系文件中的关联属性标签中,通过cascade属性进行设置,cascade="save-update"
b)实现级联删除,cascade="delete"
c)若想级联添加、修改、删除一起支持,cascade="all"
d)控制反转,在一对多关联中,使用级联新增、删除时,当前操作的“一”方会试图维护关联字段,然而关联字段是在“多”方对象中,它会自动维护这个字段,因此“一”方没必要做这样的处理。在关联属性标签上通过inverse属性(true/false)交出控制权,默认是false,不控制反转。
7.Hibernate查询
a)HQL按条件查询:条件中写的是属性名,在执行查询前调用query对象为条件参数赋值
String hql = "from Course where name=?";
Session session = HibernateUtil.getSession();
Query query = session.createQuery(hql);
query.setString("math");
List<Course> courses = query.list();
b)HQL查询部分字段:可以只查询表中的一部分字段,需要在from之前追加select语句,指定要查询列对应的属性名
String hql = "select id,name" + " from Course";
注意:查询部分字段时,query.list()方法返回的集合中封装的不是实体对象,而是一个Object[],数组中的值与select语句后面的属性按顺序对应。
c)分页查询:通过API统一实现
int from = (page - 1) * pageSize; query.setFirstResult(from); query.setMaxResults(pageSize);
注意:查询的起点是本页第一行,按照JDBC计算,公式为(page -1) * pageSize +1;Hibernate中行数的起点是0,不同于JDBC是从1开始,所以要在上面公式的基础上-1,即(page -1) * pageSize
d)查询总页数:根据以下hql查询总行数,再计算总页数
String hql = "select count(*) from Student";
e)多表联合查询:可以使用HQL进行多表联合查询,不过HQL中写的是关联的对象的属性名;有3中关联查询的方式:
对象方式关联
String hql = "select s.id, s.name, c.name from Student s, Course c " +
"where s.course.id = c.id";
join方式关联(不能直接join对象,需要join关联属性)
String hql = "select s.id, s.name, c.name from Student s inner join s.courses c";
select子句关联
f)直接使用SQL查询
String sql = "select * from t_course where c_name=?"; Session session = HibernateUtil.getSession(); SQLQuery query = session.createSQLQuery(sql); query.setString(0,"math"); List<Object[]> list = query.list(); //返回集合封装的是Object[] //若想返回集合中封装实体对象 query.addEntity(Course.class); List<Course> list = query.list();
g)使用Criteria查询
Criteria c = session.createCriteria(Course.class);
c.add(Restriction.eq("name", "math")).add(Restrictions.or(Restrictions.eq(), Restrications.eq()));
List<Course> list = c.list();

8.二级缓存
a)二级缓存类似于一级缓存,可以缓存对象,但它是SessionFactory级别的缓存,有SessionFactory负责管理。因此二级缓存的数据是Session间共享的,不同的Session对象都可以共享二级缓存中的数据。
b)二级缓存适用于:对象数据频繁共享,数据变化频率低
c)二级缓存使用步骤:
导入ehcache.jar
在src下添加缓存配置文件ehcache.xml
<ehcache>
<!--缓存到硬盘时的缓存路径,java.io.tmpdir表示系统默认缓存路径-->
<diskStore path="java.io.tmpdir"/>
<!--默认缓存配置
maxElementsInMemory:二级缓存可容纳最大对象数
eternal:是否保持二级缓存中对象不变
timeToIdleSeconds:允许对象空闲的时间,即对象最后一次访问起,超过该时间即失效
timeToLiveSeconds:允许对象存活的时间,即对象创建起,超过该时间即失效
overflowToDisk:内存不足,是否允许使用硬盘缓存,写入路径参考diskStore
-->
<defaultCache>
maxElementsInMemory = "300"
eternal = "false"
timeToIdleSeconds = "120"
timeToLiveSeconds = "300"
overflowToDisk = "true" />
<!--自定义配置-->
<cache name="myCache">
maxElementsInMemory = "2000"
eternal = "false"
timeToIdleSeconds = "200"
timeToLiveSeconds = "300"
overflowToDisk = "true" />
</ehcache>
在hibernate.cfg.xml中开启二级缓存,指定采用的二级缓存驱动类
<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.provider_class"> org.hibernate.cache.EhCacheProvider </property>
在要缓存的对象对应的映射关系文件中,开启当前对象的二级缓存支持,并指定缓存策略
<!--开启二级缓存,并指定缓存策略 可以用region属性指定自定义的缓存设置--> <cache usage="read-only" />
d)缓存策略:
-只读型(read-only):缓存不会更新,适用于不会发生改变的数据,效率最高,事务隔离级别最低
-读写型(read-write):缓存会在数据变化时更新,适用于变化的数据
-不严格读写型(nonstrict-read-write):缓存不定期更新,适用于变化频率低的数据
-事务型(transactional):缓存会在数据变化时更新,并且支持事务。效率最低,事务隔离界别最高。
<!-- 配置事务的隔离级别
1 -- Read uncommitted isolation
2 -- Read committed isolation
3 -- Repeatable read isolation
4 -- Serializable isolation
-->
<property name="hibernate.connection.isolation">2</property>
9.查询缓存
a)查询缓存依赖于二级缓存,可以理解为特殊的二级缓存,也是SessionFactory级别的,也是由SessionFactory负责维护
b)查询缓存可以缓存任何查询到的结果
c)查询缓存是以hql为key,缓存该hql查询到的整个结果。如果执行2次同样的hql,第二次执行可以从查询缓存中取到第一次查询缓存的内容
d)使用查询缓存步骤:
开启二级缓存
在hibernate.cfg.xml中,开启查询缓存
<!--开启查询缓存--> <property name="hibernate.cache.use_query_cache">true</property>
在查询代码执行前,指定开启查询缓存
query.setCacheable(true); //开启查询缓存
整理到此为止,有不足的欢迎指正讨论。。。☺