我们一直使用 print 方法打印爬虫获取的数据,接下来你将把这些数据保存到特定格式文件中。
CSV 格式
Python 提供了标准库 csv 来读写 csv 数据。
新建一个 Python 文件,输入以下代码,并运行。
import csv
file = open('movies.csv', 'w', newline='')
csvwriter = csv.writer(file)
# 写入标题行
csvwriter.writerow(['名称', '年份'])
# 写入数据
csvwriter.writerow(['A', '1992'])
csvwriter.writerow(['B', '1998'])
csvwriter.writerow(['C', '2010'])
file.close
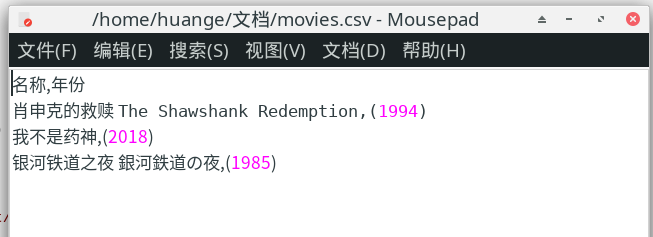
使用记事本打开 movies.csv 文件,将运行结果复制到下面的文本框中:
CSV 数据可以使用微软 Office Excel 软件打开。非常多的爬虫数据集都使用 CSV 作为存储格式。
将爬虫数据写入 CSV 文件
至此,你已经基本掌握了编写一个简单爬虫的技能,是不是很简单呢?
from requests_html import HTMLSession
import csv
session = HTMLSession()
file = open('movies.csv', 'w', newline='')
csvwriter = csv.writer(file)
csvwriter.writerow(['名称', '年份'])
links = ['https://movie.douban.com/subject/1292052/', 'https://movie.douban.com/subject/26752088/', 'https://movie.douban.com/subject/1962665/']
for link in links:
r = session.get(link)
title = r.html.find('#content > h1 > span:nth-child(1)', first=True)
year = r.html.find('#content > h1 > span.year', first=True)
csvwriter.writerow(title.text, year.text)
file.close()
上面代码有一处错误,你发现了吗?
运行结果: