
哈姆雷特英文
https://python123.io/resources/pye/hamlet.txt
三国演义中文
https://python123.io/resources/pye/threekingdoms.txt

哈姆雷特英文词频分析
def getText(): txt=open("hamlet.txt","r").read()#打开文本,输入具体的文本路径 txt=txt.lower()#将文本中所有的英文字符变成小写 for ch in '!"#$%&()*+,-./;:<=>?@[\]^‘_{|}~': txt=txt.replace(ch," ") return txt #去掉特殊符号 hamletTxt=getText()#调用函数对文本进行处理 words=hamletTxt.split()#进行列表 counts={}#字典 for word in words: counts[word]=counts.get(word,0)+1#获取到的词在字典中寻找如果有的话在原来的基础上+1,如果没有就收录到字典中 items=list(counts.items())#变成列表类型 items.sort(key=lambda x:x[1],reverse=True)#对列表排序 for i in range(10):#将出现次数前10的单词输出并输出出现次数 word,count=items[i] print("{0:<10}{1:>5}".format(word,count))
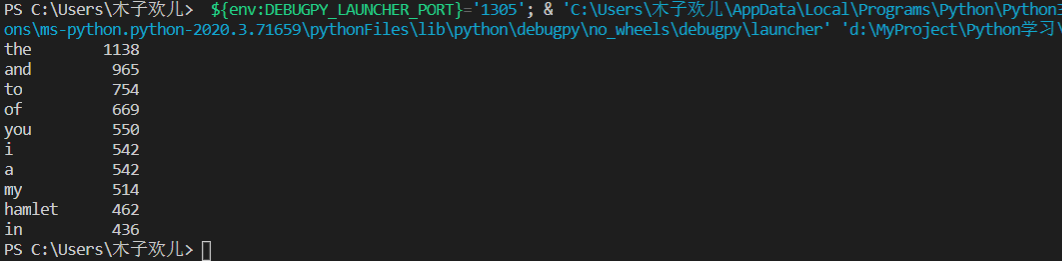
三国演义人物出场次数
import jieba#引入jieba分词库 txt = open("threekingdoms.txt", "r", encoding="utf-8").read()#打开文本 words = jieba.lcut(txt)#进行分词处理并形成列表 counts = {}#构造字典,逐一遍历words中的中文单词进行处理,并用字典计数 for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items())#转换列表类型并排序 items.sort(key=lambda x:x[1], reverse=True) for i in range(15):#输出前15位单词 word, count = items[i] print("{0:<10}{1:<5}".format(word, count))
结果:
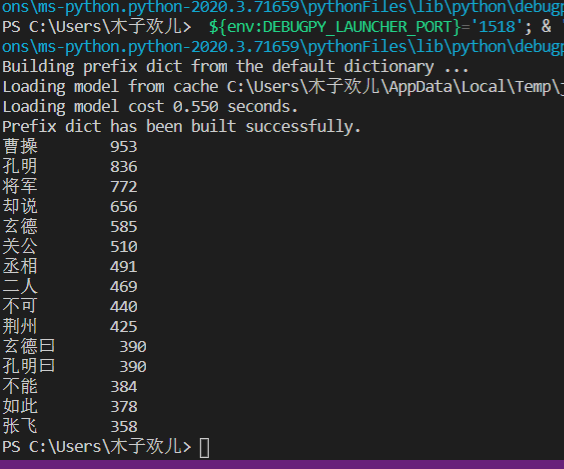
上面有不是人物的词,需要改造
import jieba txt = open("threekingdoms.txt", "r", encoding="utf-8").read() excludes = {"将军", "却说", "荆州", "二人", "不可", "不能", "如此", "主公", "军士", "商议", "如何", "左右", "军马", "引兵", "次日", "大喜", "天下", "东吴", "于是", "今日", "不敢", "魏兵", "陛下", "一人", "都督", "人马", "不知"}#排除不是人名的词汇,加到这个排除词库中 words = jieba.lcut(txt) counts = {} for word in words:#进行人名关联,防止重复 if len(word) == 1: continue elif word == "诸葛亮" or word == "孔明曰": rword = "孔明" elif word == "关公" or word == "云长": rword = "关羽" elif word == "玄德" or word == "玄德曰": rword = "刘备" elif word == "孟德" or word == "丞相": rword = "曹操" else: rword = word counts[rword] = counts.get(rword, 0) + 1 for word in excludes: del counts[word] items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(10): word, count = items[i] print("{0:<10}{1:<5}".format(word, count))
结果

不断优化。。。。

