链表是一种用于存储数据集合的数据结构。链表有以下几个属性:
- 相邻元素之间通过指针进行连接
- 最后一个元素的后继指针值为NULL
- 在程序执行的过程中,链表的长度可以增加或缩小
- 链表的空间能够按需分配(直到系统内存耗尽)
- 没有内存空间的浪费(但是链表中的指针需要一些额外的内存开销)

一、链表的分类
链表大致可以分为这么几类:
- 单向链表
- 双向链表
- 存储较为高效的双向链表
- 循环链表
- 松散链表
二、LRU缓存淘汰算法
在具体介绍链表之前,有必要先介绍一下关于LRU缓存技术:
缓存是一种提高数据读取性能的技术,在硬件设计,软件开发中都有着非常广泛的应用,比如常见的CPU缓存、数据库缓存、浏览器缓存等等。
缓存的大小是有限的,当缓存被用满的时,此时就需要对缓存做相应的清理,但是,具体哪些数据应该被清理出去?哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:
- 先进先出策略FIFO(First In ,First Out)
- 最少使用策略LFU(Least Frequently Used)
- 最近最少使用策略LRU(Least Recently Used)
那么接下来就有一个问题:如何使用链表来实现LRU缓存淘汰策略呢?
三、链表的底层存储结构
相比于数组来说,链表是一种稍微复杂一点的数据结构,下面是链表和数组的内存分部对比图:
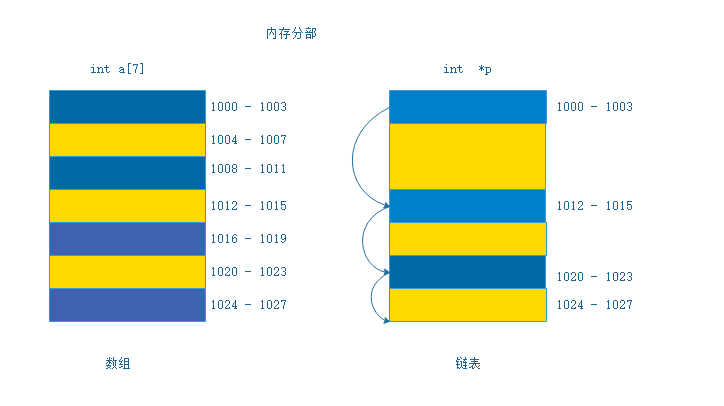
从图中可以看出
- 对于数组来说,它需要一块连续的内存存储空间来存储,对内存的要求比较高,也就是说,如果我申请100M大小的数组的话,当内存中没有连续的、足够大的存储空间的时候,即便内存中剩余总可用空间大于100M,此时仍然会申请失败
- 对于链表来说,它恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以,如果我们申请的是100M大小的链表,当内存中剩余可用空间大于100M的时候,无论是否连续,申请都不会有问题。
四、链表的一些基本概念:
- 结点:链表是通过指针将自足零散的内存块串联在一起,所以,将每个内存块就是链表的一个"结点"
- 后继指针:每个链表的结点除了存储数据之外,还需要记录链路上下一个节点的地址,将记录下一个结点地址的指针叫做后继指针。
- 头结点:整个链路中第一个结点称之为“头结点”
- 尾节点:整个链路中最后一个结点称之为“尾节点”
- 空地址NULL:当一个指针指向的不是下一个结点,而是空地址NULL,表示这是链路上的最后一个结点。
五、链表、数组的优缺点对比
关于数组,其实在数组这一节,做了详细的讨论,这里不做多的赘述。
链表与数组的优缺点对比:

链表、数组与动态数组的时间复杂度对比:

单向链表
链表通常是指单向链表,她包含了多个结点,每个结点有一个指向后继元素的指针,表中最后一个结点next指针为NULL,表示该链表结束。
申明一个链表
public class ListNode { private int data; private ListNode next; public ListNode(int data) { this.data = data; } public void setData(int data) { this.data = data; } public int getData() { return data; } public void setNext(ListNode next) { this.next = next; } public ListNode getNext() { return this.next; } }
链表的主要操作(时间复杂度均为O(1)):
- 遍历链表
- 插入一个元素:插入一个元素到链表中
- 删除一个元素:移除并返回链表中指定位置的元素
链表的辅助操作:
- 删除链表:移除链表中的所有元素(清空链表)
- 计数:返回链表中元素的个数
- 查找:寻找从链表表尾开始的第n个节点(node)
链表的遍历
假设表头指针指向链表中的第一个结点。遍历链表需要完成以下几个步骤:
- 沿指针遍历
- 遍历时显示节点的内容
- 当next指针的值为NULL时,结束遍历
通过遍历链表来对链表元素进行计数:
/** * 统计链表节点的个数 */ public int ListLength(ListNode headNode) { int length = 0; ListNode currentNode = headNode; while (currentNode != null) { length++; currentNode = currentNode.getNext(); } return length; }
此时间复杂度为O(n),用于扫描长度为n的链表。
空间复杂度为O(1),仅用于创建临时变量
单向链表的插入
单向链表的插入可以分为以下3种情况
- 在链表的头前插入一个新结点(链表的开始出)
- 在链表的尾后插入一个新结点(链表的结尾出)
- 在链表的中间插入一个新结点(随机位置)
在单向链表的开头插入结点
若需要在表头节点前插入一个新结点,只需要修改一个next指针,可通过如下两步完成:
- 更新新节点next指针,是其指向当前结点的表头节点。

- 更新表头指针的值,使其指向新结点。
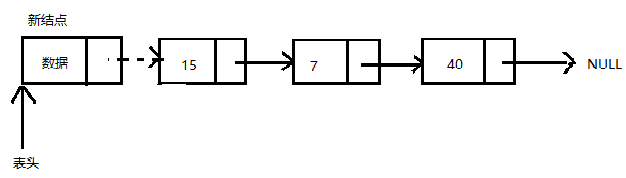
在单向量表的结尾插入结点
如果需要在表尾部插入新结点,则需要修改两个next指针
- 新结点的next指针指向NULL
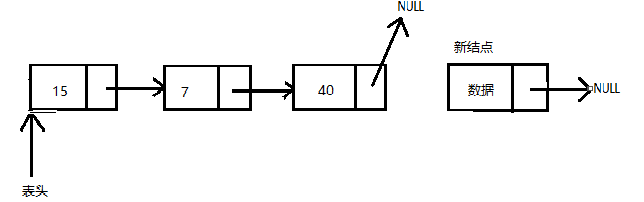
- 最后一个结点的指针指向新结点
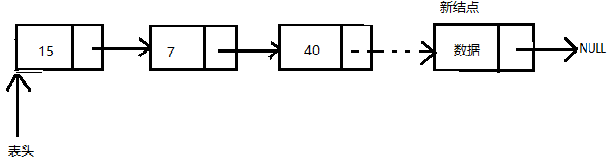
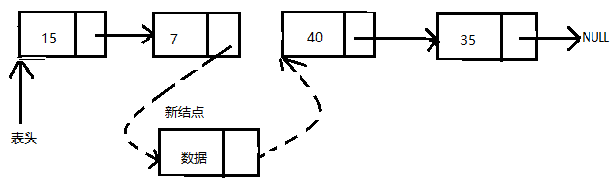
在单向链表的中间插入结点
假设给定插入新结点的位置,在这种情况下,需要修改两个next指针:
- 如果位置3增加一个元素,则需要将指针定位于链表的位置2,。即需要从表头开始经过两个结点,然后插入新结点。假设第二个结点为位置结点,新结点的next指针指向位置结点(我们要在此处增加新结点)的下一个结点

- 位置结点的next指针指向新结点
代码实现:
/** * 单向链表List节点进行插入操作 */ public ListNode InsertInLinkedList(ListNode headNode, ListNode nodeToInsert, int position) { //如果链表为空,则插入的节点即为头结点 if (headNode == null) { return nodeToInsert; } //获取该链表的节点数 int size = ListLength(headNode); if (position < 1 || position > size + 1) { System.out.println("Position of node to insert is invalid.The valid input are 1 to " + (size + 1)); return headNode; } //否则,插入元素要么是在头插入,要么是在尾节点,或是中间 if (position == 1) { nodeToInsert.setNext(headNode); return nodeToInsert; } else { //在链表的中间或尾部插入 ListNode previousNode = headNode; int count = 1; while (count < position - 1) { previousNode = previousNode.getNext(); count++; } ListNode currentNode = previousNode.getNext(); nodeToInsert.setNext(currentNode); previousNode.setNext(nodeToInsert); } return headNode; }
时间复杂度为O(n)。在最坏情况下,可能需要在链表尾部插入结点。
空间复杂度为O(1),仅用于创建一个临时变量。
单向链表的删除
单向链表的删除操作,也分为三种情况:
- 删除链表的表头(第一个)结点
- 删除链表的表尾(最后一个)节点
- 删除链表的中间的节点
删除单向链表表头结点
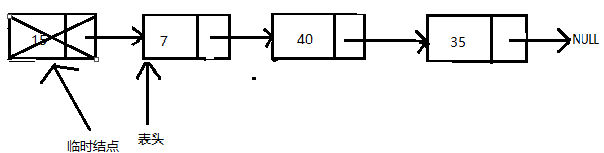
删除链表的第一个结点,可以通过两步实现:
- 创建一个临时结点,它指向表头指针所指的结点。
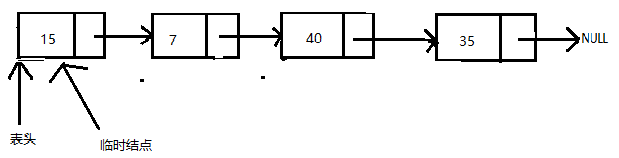
- 修改表头指针的值,使其指向下一个结点,并移除临时结点。
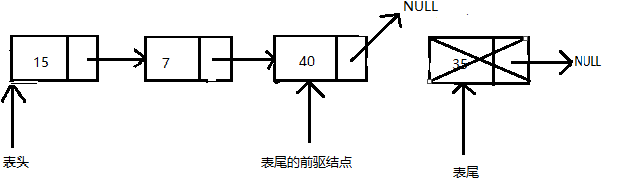
删除单向链表的最后一个结点
这种情况下,操作比删除第一个结点要麻烦一点,因为算法需要找到表尾节点的前驱节点。这需要三步来实现:
- 遍历链表,在遍历时还要保存前驱(前一次经过)结点的地址。当遍历到链表的表尾时,将有两个指针,分别是表尾结点的指针tail(表尾)即指向表尾结点的钱去结点的指针

- 将表尾的前驱节点的next指针更新为NULL
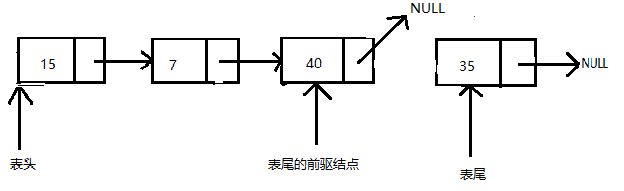
- 移除表尾节点。
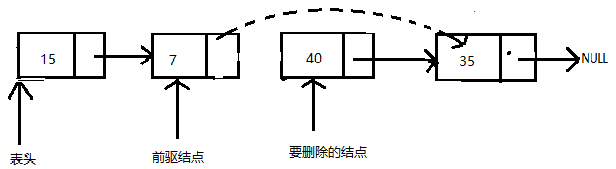
删除单向链表中间一个结点
在这种情况下,删除的结点总是位于两个结点之间,因此不需要更新表头和表尾的指针。该删除操作通过两步实现:
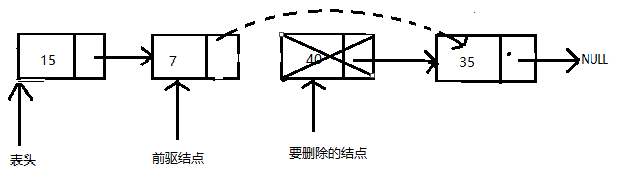
- 在遍历时保存前驱(前一次经过的)结点的地址。一旦找到被删除的结点,将前驱结点next指针的值更新为被删除结点的next指针的值
- 移除需要删除的当前结点
代码实现:
/** * 单向链表List的删除操作 */ public ListNode deleteNodeFromeLinkedList(ListNode headNode, int position) { int size = ListLength(headNode); if (position > size || position < 1) { System.out.println("Postition of node to delete is invalid.The valid inputs are 1 to " + size); return headNode; } if (position == 1) { ListNode currentNode = headNode.getNext(); headNode = null; return currentNode; } else { ListNode preivousNode = headNode; int count = 1; while (count < position) { preivousNode = preivousNode.getNext(); count++; } ListNode currentNode = preivousNode.getNext(); preivousNode.setNext(currentNode.getNext()); currentNode = null; } return headNode; }
时间复杂度为O(n)。在最差情况下,可能需要删除链表的表尾节点。
空间复杂度为O(1),仅用于创建一个临时变量
删除单向链表
该操作通过将当前结点存储在临时变量中,然后释放当前结点(空间)的方式来完成。当时放完当前结点(空间)后,移动到下一个结点并将其存储在临时变量中,然后不断重复该过程直至释放所有结点。
代码实现:
/** * 删除单向链表 */ public void deleteLinkedList(ListNode headNode) { ListNode auxilaryNode,iterator = headNode; while (iterator != null){ auxilaryNode = iterator.getNext(); iterator = null; iterator = auxilaryNode; } }
时间复杂度为O(n),用扫描大小为n的整个建链表
空间复杂度为O(1),用于创建临时变量