1.概述
数据增强,可以帮助扩展数据集,对图像的增强,就是对图像的简单形变,用来应对因拍照角度不同引起的图片变形。
TensorFlow2给出了数据增强函数
2.数据增强(增大数据量)


数据增强在小数据量上可以增加模型的泛化性,在实际应用模型是能体现出效果
tf.keras.layers.Flatten()拉直层
拉直层可以变化张量的尺寸,把输入特征拉直为一维数组,是不含计算参数的层
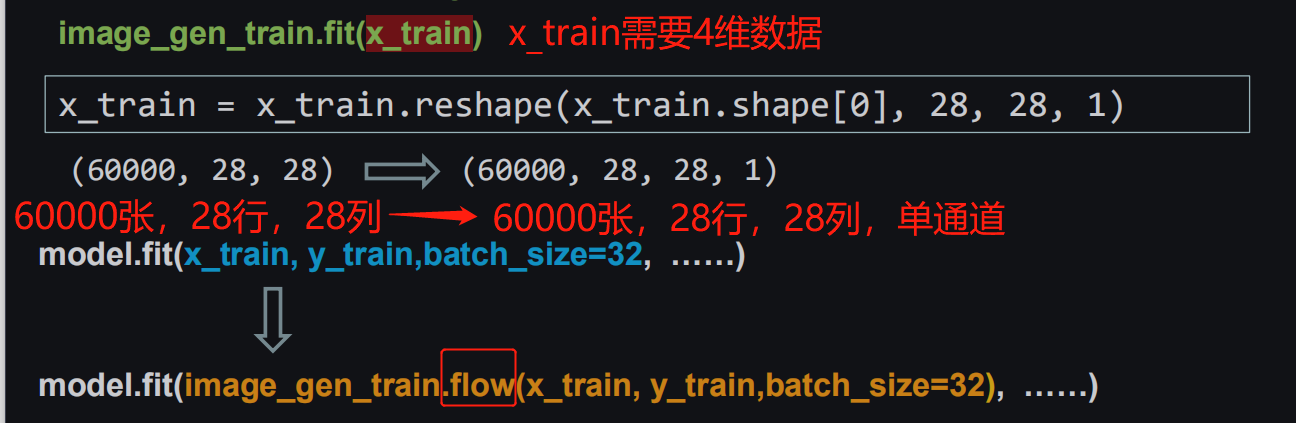
注: 1、 model.fit(x_train,y_train,batch_size=32,……)变为model.fit(image_gen_train.flow(x_train, y_train,batch_size=32), ……);
2、数据增强函数的输入要求是 4 维,通过 reshape 调整; 3、如果报错:缺少scipy 库, pip install scipy 即可。
代码:
没有经过数据增强操作
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
加了数据增强
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) # 给数据增加一个维度,从(60000, 28, 28)reshape为(60000, 28, 28, 1)
image_gen_train = ImageDataGenerator(
rescale=1. / 1., # 如为图像,分母为255时,可归至0~1
rotation_range=45, # 随机45度旋转
width_shift_range=.15, # 宽度偏移
height_shift_range=.15, # 高度偏移
horizontal_flip=False, # 水平翻转
zoom_range=0.5 # 将图像随机缩放阈量50%
)
image_gen_train.fit(x_train)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(image_gen_train.flow(x_train, y_train, batch_size=32), epochs=5, validation_data=(x_test, y_test),
validation_freq=1)
model.summary()