一.G1 GC术语Overview
1.1 并发
并发的意思是Java应用执行和垃圾收集活动可以同时进行
1.2 并行
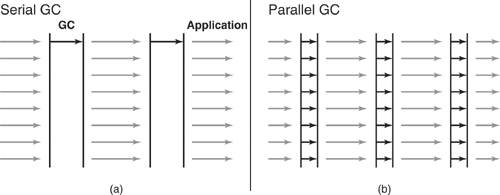
并行的意思是垃圾收集运算是多线程执行的,比如CMS垃圾收集器的年轻代就是并行的,并行与串行的区别如下图,左边为串行,右边为串行:
1.3 STW
STW(stop the world)意思是在一个垃圾回收事件中,所有Java应用线程会被暂停。只有暂停,应用才不会产生新的垃圾,有益于垃圾收集器更好的标记垃圾对象。(这就像是你在家扫狗毛,肯定要把狗先关笼子,停止它的活动)
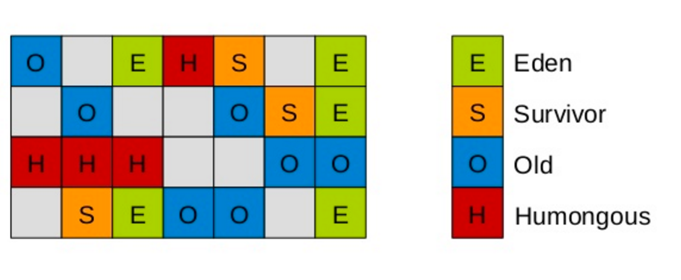
1.4 Region
请先忘记这个图,学习G1过程中不会对每个代进行设置了

G1垃圾收集器利用分而治之的思想将堆进行分区,划分为一个个的区域。每次收集的时候,只收集其中几个区域,以此来控制垃圾回收产生的STW
G1和其他GC算法最大的区别是弱化分代概念,引入分区思想!!!
如果要另外选择分区的尺寸,可以通过命令行选项:-XX:G1HeapRegionSize=n中进行设置
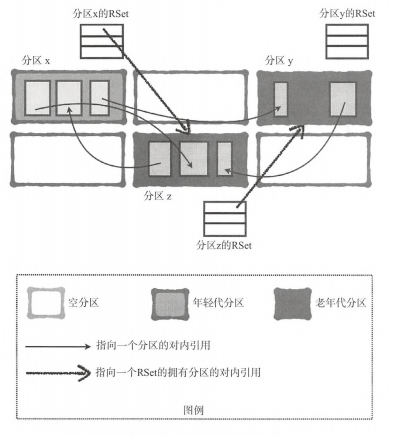
1.5 RSet
G1垃圾收集器里每一个RSet对应的是一个Region内部对象引用情况,说白了就是存在Region中存活对象的指针。在标记存活对象的时候,G1使用RSet概念,将每个分区指向分区内的引用记录在该分区,避免对整个堆扫描,并行独立处理垃圾集合
- 老年代对年轻代的引用,维护老年代分区指向年轻代分区的指针
- 老年代对老年代的引用。在这里,老年代中不同分区的指针将被维护在老年代拥有分区的RSet中
如下图,我们可以看到3各分区,x(年轻代分区)、y和z(老年代分区)。x有一个来自z的对内引用。这个引用记录在x的RSet中,分区z有2个对内引用,一个来自x一个来自y,因为年轻代分区作为一个整体回收的,所以只需记录来自y的对内引用,不用记录x的对内引用
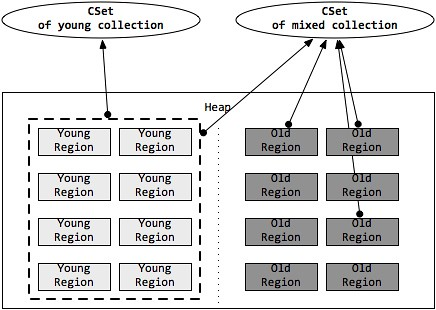
1.6 CSet
Collection Set,简称CSet。在垃圾收集过程中收集的Region集合可以称为收集集合(CSet),也就是在垃圾收集暂停过程中被回收的目标。GC时在CSet中的所有存活数据都会被转移,分区释放回空闲分区队列
见下图,左边的年轻代收集CSet代表年轻代的一部分分区,右边的混合收集CSet代表年轻代的一部分区和老年代的多个分区:
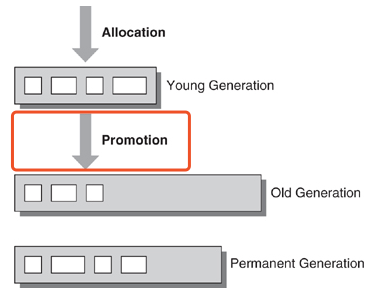
1.7 PLAB
Promotion Local Allocation Buffers,对象晋升到survivor分区或者老年代分区的过程是在GC线程的晋升本地分配缓冲区(PLAB)进行的,每个线程有独立的PLAB。作用是避免多线程竞争相同数据。和下面介绍的TLAB思想是一致的
1.8 TLAB
Thread Local Allocation Buffers,线程本地分配缓存。JVM使用了TLAB这种线程专属的区间来避免多线程冲突(无锁方式),提高对象分配效率。TLAB本身占用了Eden空间,即JVM会为每一个线程都分配一块TLAB空间

1.9 IHOP
InitiatingHeapOccupancyPercent,简称IHOP。缺省情况是Java堆内存的45%。当老年代的空间超过45%,G1会启动一次混合周期收集
这也是G1和CMS之间较大的区别,G1的百分比是相对于整个Java堆而言的,CMS(CMSInitiatingOccupancyFraction)仅仅是针对老年代空间的占比。
为什么G1如此设计???
因为G1没有固定物理上分割一块内存作为老年代,而是用了Region的思想,这些Region可能是eden,survivor、老年代或者巨型分区,所以获取针对老年代本身的占用百分比没有意义
2.10 巨型分区
巨型对象会以连续分区的形式来存放,这种就叫巨型分区。巨型对象无法利用年轻代里的TLAB和PLAB。在JDK 8u40之前,它只能在并发收集周期的清除阶段回收,但是在JDK 8u40之后,巨型分区可以在年轻代收集中和full GC被回收
二.G1的设计
2.1 为什么会有G1?
为什么会有G1呢?因为并发、并行和CMS垃圾收集器都有2个共同的问题:
- 老年代收集器大部分操作都必须扫描整个老年代空间(标记,清除和压缩)。这就导致了GC随着Java堆空间而线性增加或减少
- 年轻代和老年代是独立的连续内存块,所以要先决定年轻代和年老代放在虚拟地址空间的位置
2.2 Region的设计
上面说到,G1垃圾收集器利用分而治之的思想将堆进行分区,划分为一个个的区域。G1垃圾收集器将堆拆成一系列的分区,这样的话,大部分的垃圾收集操作就只在一个分区内执行,而不是整个堆或者整个代

2.3 设计目标
G1的设计目标就是把必要的调整限定在以下2个:
- 设置最大的Java堆空间
- 设置指定GC暂停时间
G1会通过调整Java堆尺寸大小来满足设定的暂停时间目标,暂停时间目标越短,年轻代空间越小,老年代空间相对越大
2.4 使用场景
G1 GC切分堆内存为多个区间(Region),从而避免很多GC操作在整个Java堆或者整个年轻代进行。G1 GC只关注你有没有存货对象,都会被回收并放入可用的Region队列。G1 GC是基于Region的GC,适用于大内存机器。即使内存很大,Region扫描,性能还是很高的
如果现在采用的收集器没有问题,就不要选择G1,如果追求低停顿,那么G1已经是一个可尝试的选择,如果追求吞吐量,就不要选G1了
四.G1的垃圾回收
G1的垃圾收集周期主要有4种类型:年轻代收集周期、多级并发标记周期、混合收集周期和full GC(转移失败的安全保护机制)
这一节我会以应用启动的时间顺序来讲,这样比较易懂一点,也可以参照G1垃圾收集活动时序图:

4.1 年轻代收集
应用刚启动,慢慢流量进来,开始生成对象。G1会选一个分区并指定他为eden分区,当这块分区用满了之后,G1会选一个新的分区作为eden分区,这个操作会一直进行下去直到达到eden分区上限,也就是说eden分区已经被占满,那么会触发一次年轻代收集
年轻代收集首先做的就是迁移存活对象,它使用单eden,双survivor进行复制算法,它将存活的对象从eden分区转移到survivor分区,survivor分区内的某些对象达到了任期阈值之后,会晋升到老年代分区中。原有的年轻代分区会被整个回收掉
同时,年轻代收集还负责维护对象年龄,存活对象经历过年轻代收集总次数等信息。G1将晋升对象的尺寸总和和它们的年龄信息维护到年龄表中,结合年龄表、survivor占比(--XX:TargetSurvivorRatio 缺省50%)、最大任期阈值(--XX:MaxTenuringThreshold 缺省为15)来计算出一个合适的任期阈值
调优:我们可以通过--XX:MaxGCPauseMillis,调优年轻代收集,缩小暂停时间
4.2 并发标记周期
随着时间推移,越来越多的对象晋升到老年代中,当老年代占比(相对于Java总堆而言)达到IHOP参数(上图的IHOP Trigger)之后,那么G1首先会触发并发标记周期(上图的Concurrent Marking Cycle),当完成后才会开始下一小节的混合垃圾收集周期
G1的并发标记循环分5个阶段:
第一阶段:初始标记(上图Young Collection with Initial Mark),收集所有GC根(对象的起源指针,根引用),STW,在年轻代完成
第二阶段:根区间扫描,标记所有幸存者区间的对象引用
第三阶段:并发标记(上图Concurrent Marking),标记存活对象
第四阶段:重新标记(上图Remark),是最后一个标记阶段,STW,很短,完成所有标记工作
第五阶段:清除(上图Clean),回收没有存活对象的Region并加入可用Region队列
调优:我们可以通过--XX:InitiatingHeapOccupancyPercent,配置适合应用的IHOP值(过大会可能转移失败,过小可能过早引起并发标记周期)
我们也可以通过--XX:ConcGCThreads,增加并发线程数
4.3 混合收集周期
当达到IHOP参数并完成上一小节的并发标记周期之后,混合收集周期就启动了,一个周期里的单次STW的混合收集和年轻代收集是类似的,唯一区别就是在混合收集过程中会包含一部分老年分区,所以也叫混合收集
看上图的Mixed Collection Cycle,中间有好几段Mixed Collection,说明混合收集周期包含多次收集次数。那么什么影响收集次数呢?是固定的?还是?有两个参数比较重要:
-XX:G1MixedGCCountTarget:缺省值为8,意思是能启动混合收集的数目设定一个物理限制。G1根据将回收的老年分区除以该参数值得到每次混合收集的老年代CSet最小数量
-XX:G1HeapWastePercent:缺省值为5%,每次混合收集暂停,G1算出废物百分比,根据堆废物百分比,当收集达到参数时,不再启动新的混合收集
调优:当暂停时间和运行时间呈现指数级增长,可以通过-XX:G1HeapWastePercent,调高该参数会有所帮助,但这也导致更多碎片化
4.4 full GC
有2个条件同时满足则会触发full GC
1.拷贝存活对象晋升(promotion)失败,无法找到可用的空闲分区,GC日志记录为to-space exhausted。或者分配巨型对象无法在老年代找到连续足够的分区
2.当发生第一个条件后,G1会尝试增加堆使用量,如果扩展失败,那么会触发安全措施机制同时发生full GC
full GC中,单个线程会对整个堆的所有代中所有分区做标记、清除以及压缩动作!!非常非常昂贵的操作!