分类树(决策树)是一种十分常用的分类方法。核心任务是把数据分类到可能的对应类别。
他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。
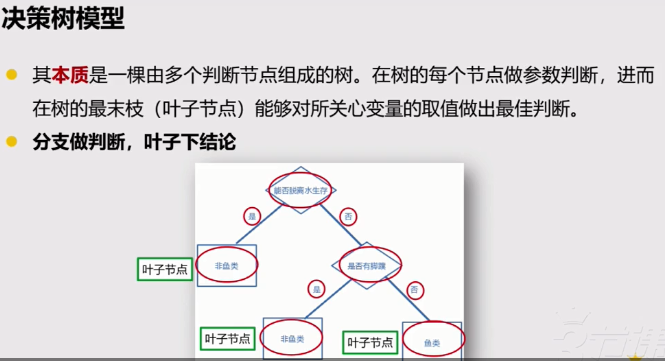

决策树的理解
熵的概念对理解决策树很重要
决策树做判断不是百分之百正确,它只是基于不确定性做最优判断。
熵就是用来描述不确定性的。
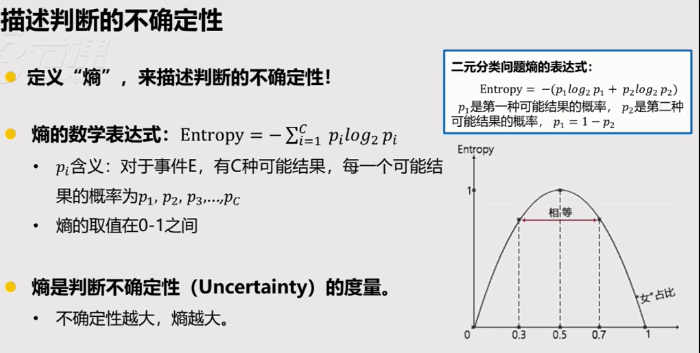
案例:找出共享单车用户中的推荐者
解析:求出哪一类人群更可能成为共享单车的推荐者。换句话说是推荐者与其他变量之间不寻常的关系。
步骤1
测量节点对应的人群的熵
对于是否推荐这样两分的结果,推荐者比例趋近于0或者1时,熵都为0,推荐者比例趋近于50%时,熵趋近1。
分析师需要根据用户特征,区分出推荐者。通过决策树可以尽可能降低节点人群熵的值(通过决策树不断的分叉)。
步骤2
节点的分叉
不同的分叉方式会得到不同的增益值,计算机会选择最大的增益值,即最优的分叉方式。
详情见后文信息增益相关内容。
步骤3
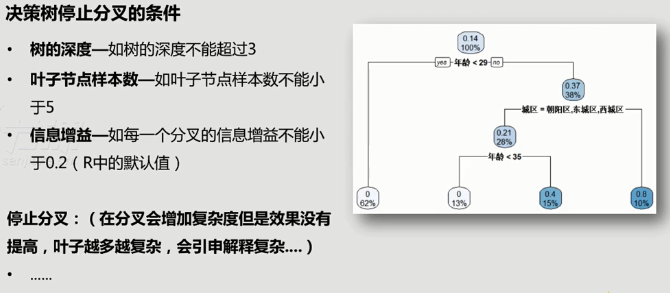
在特定情况下停止分叉。
注意:分支节点太多会把情况搞复杂,反而不利于决策,需要在适当时候停止分叉。
信息增益(IG)的概念
表示经过决策树一次决策后,整个分类数据信息熵下降的大小。

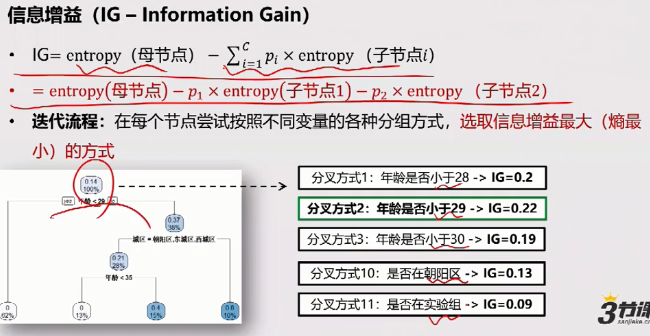
上面求得的IG是母节点的熵减去子节点熵的加权和,得到的结果,是经过一次分叉后所降低的熵的值。
不同的分叉方式会得到不同的增益值,计算机会选择最大的增益值,即最优的分叉方式。
R语言实现
> bike.data <- read.csv(Shared Bike Sample Data - ML.csv)
> library(rpart)
> library(rpart.plot)
> library(rpart.plot)
> bike.data$推荐者 <- bike.data$分数>=9
> rtree_fit <- rpart(推荐者 ~城区+年龄+组别,data=bike.data)
> rpart.plot(rtree_fit)

决策树小结
本质是一种映射关系,将对象的一组属性和对象的值映射到一起,决策树可以和概率完美结合。
优点是:适合处理多类变量,对异常值不敏感,准确度高。
缺点是:
作为一种典型的监督学习算法,在训练时需要大规模数据和计算空间。为了得到最好的决策变量排列顺序,决策树需要反复计算变量的熵信息增益,很耗时间。
决策树是一种贪心算法,每一次决策都谋求最优,追求局部最优的结果是决策树达不到全局最优(与遗传算法比,这是难以回避的缺点)。
决策树剪枝叶技术帮助决策树使用最少的节点完成分类任务,但错误剪枝会使得决策树结果准确性大幅降低,同时剪枝过程也需要大量计算。
决策树不擅长处理连续型变量。当树中连续变量过多时候,决策树犯错误的可能就会增大