正则表达式
正则表达式本身和python没有什么关系,是一种匹配字符串内容的一种规则
但是要讲re模块就必须了解正则表达式
字符组
首先,字符组是用中括号表示,中括号中是一个位置上可以出现的字符的范围
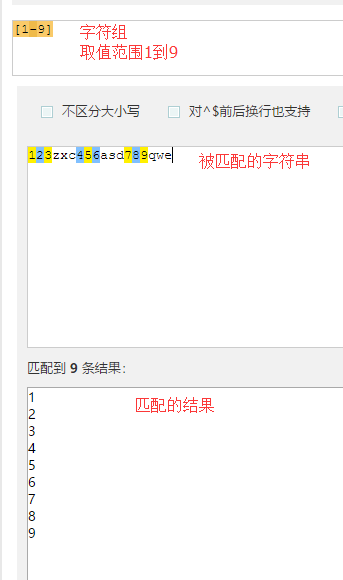
这个就是简单的字符组匹配,匹配字符串中1到9的数字然后返回,
返回的值是一个一个分开的,因为这个字符组检索的是一个单位上的要匹配的范围的元素
你要感兴趣,也可以自己去试试,这个就是在线测试工具http://tool.chinaz.com/regex/
当然,正则表达式还有很多匹配方式
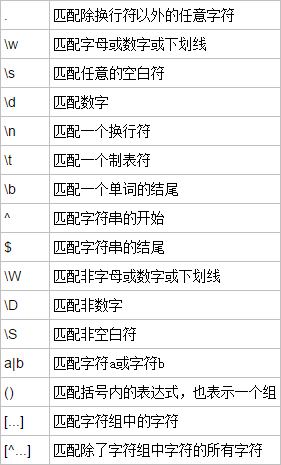
这些和字符组一样使用,只要适当的组合,就能做到很多功能
当然 除了这些还有一些量词,帮助我们更好的匹配字符串
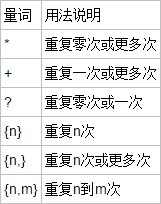
还有贪婪匹配,说的是正则在没有设定匹配多少的时候,都尽可能匹配更多的内容
re模块
说了这些正则,只是了解一下,最关键的还是讲re模块
首先说的是re模块下的常用方法
findall
ret = re.findall('阳', '阳光 太阳 阴阳') print(ret)
['阳', '阳', '阳']
返回所有满足条件的结果,放在一个列表里,不论是汉字还是英文
这个看起来是不是方便有简单,还把返回的结果放在一个列表里,但是它却有一个缺点,不过这个稍后在说
search
ret = re.search('阳', '阳光 太阳 阴阳') print(ret)
<_sre.SRE_Match object; span=(0, 1), match='阳'>
它返回的确实一个对象,所以想看到它返回的什么必须调用group()
ret = re.search('阳', '阳光 太阳 阴阳') print(ret.group())
阳
search的特点是,从前向后,找到一个就返回,并且返回的是一个变量,必须调用group()才能看见
match
ret = re.match('阳', '太阳 阳光 阴阳') print(ret.group())
这个就报错了
ret = re.match('阳', '阳光 太阳 阴阳') print(ret.group())
而这个就没问题了,原因是match和search一样,但是它是只在字符串的开头寻找,
如果没有就报错