一、SVM的简介
SVM(Support Vector Machine,中文名:支持向量机),是一种非常常用的机器学习分类算法,也是在传统机器学习(在以神经网络为主的深度学习出现以前)中一种非常牛X的分类算法。关于它的发展历史,直接引用Wikipedia中的,毕竟本文主要介绍它的推导过程,而不是历史发展。
The original SVM algorithm was invented by Vladimir N. Vapnik and Alexey Ya. Chervonenkis in 1963. In 1992, Bernhard E. Boser, Isabelle M. Guyon and Vladimir N. Vapnik suggested a way to create nonlinear classifiers by applying the kernel trick to maximum-margin hyperplanes. The current standard
接下来,就让我们回到过去,扮演它的发明者。(不要想太多,这个非常简单,只需基础的线性代数基础)
二、一个最简单的分类问题
有如下几条直线,哪条是黑白两种点的最佳分割线?
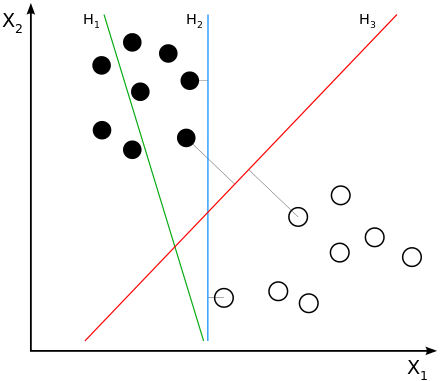
如果你看到了上面的那张图,你肯定会毫不犹豫的说是H3,因为H1明显没有满足要求,H2虽然分开了,但是给人的感觉没有那么好!如果现在在图中给你一个未知颜色的点,让你判断它是黑还是白,该如何判断?如果是我,我就会说如果这个未知点在H3左边的它就是黑色,如果他在H3的右边,他就是白色。
如果到这儿你都完全理解,那么距离明白SVM就已经非常接近了。使用计算机程序寻找H3的过程,我们管它叫做训练;使用H3对未知点进行分类的过程,我们管它叫做预测。
接下来,我们就需要知道计算机是如何找到H3这条线,和如何使用H3做出决策?(计算机不是人类,所以它不能靠感觉,而要编写计算机程序,则必须有一个严谨的算法过程。)
三、SVM推导
首先,我们将上面寻找H3的问题转换一下,

如上图,找到最佳的分割线,也就是让两条虚线之间的距离最大。
首先我们假设这条分割线的法向量为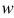 ,我们知道在直角坐标系中,任意一点都可以表示为一向量
,我们知道在直角坐标系中,任意一点都可以表示为一向量 ,w · u则表示该向量在
,w · u则表示该向量在 上投影的长度,对于任意一个正样本(设黑为+,白为-) 有w · u ≥ C,设b = C,则将其整理一下即可写为w · u - b ≥ 0, 如果已知w和b,使用此公式,我们便可对未知点进行预测(或者叫分类)。
上投影的长度,对于任意一个正样本(设黑为+,白为-) 有w · u ≥ C,设b = C,则将其整理一下即可写为w · u - b ≥ 0, 如果已知w和b,使用此公式,我们便可对未知点进行预测(或者叫分类)。
由上述,我们知道了决策过程,接下来,我们需要推导出训练过程,即怎样得到w和b?
首先对于训练集,在训练集中对于任意一点xi 我们知道它的标签yi(如果为正例yi = 1,如果为负例yi = -1),然后对于正负例我们假设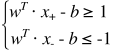 (假设当点刚好在边缘时等号成立), 不等式两边同乘以yi就可以得到
(假设当点刚好在边缘时等号成立), 不等式两边同乘以yi就可以得到 。
。
两条虚线之间的宽度求法如下:
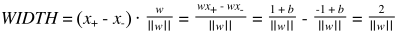
即我们要做工作的是:

即我们需要在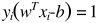 的约束下(只需关注边界上的点),求
的约束下(只需关注边界上的点),求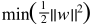 。(这个问题,相信对于学过大学高等数学的人来说是非常简单的)
。(这个问题,相信对于学过大学高等数学的人来说是非常简单的)
使用拉格朗日乘数可以很容易的进行求解,
设 则:
则:
 ,
, 
将w回带到L中,
化简得,
注意上式的末尾,要使L取极值(画出决策边界),结果只与训练集中已知点向量的点积有关,与其它量无关。
如果再将  带入到决策函数中,则
带入到决策函数中,则
if 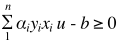
result = +
else
result = -
综上所述,可以发现,要求得最大间隔与对一个未知点的分类预测只与已知虚线点的点积有关。
四、核函数
在上述中,最后的决策函数为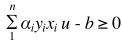 ,但这个决策函数对线性不可分的数据便无能为力了,比如:
,但这个决策函数对线性不可分的数据便无能为力了,比如:
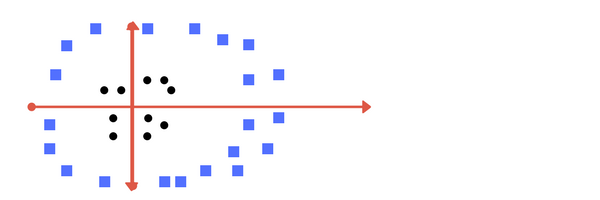
上图,不能简单的使用一条直线将其分开,但是,如果我们换个角度,
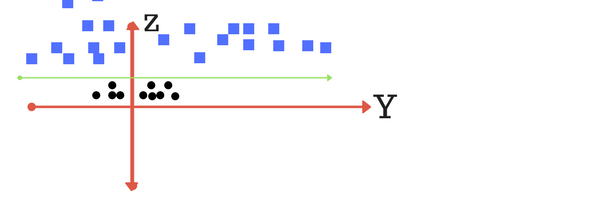
对其多加一个维度Z,很容易便可将其用一条直线将其分开,如果我们再回到最开始的维度下,则其如下图所示,

这也就告诉我们,在我们当前维度下线性不可分的数据,如果换个角度,则其就会线性可分。
又由于决策函数为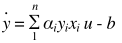 , 向量
, 向量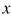 和
和 在二维z坐标系中,
在二维z坐标系中,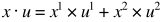 (这里的
(这里的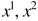 指的是向量
指的是向量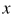 在第一和第二维度上的值),假设
在第一和第二维度上的值),假设 为
为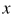 和
和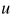 在某个维度的点积,则其决策函数就可写为
在某个维度的点积,则其决策函数就可写为
 ,而
,而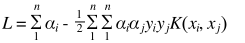 . (称K为核函数)
. (称K为核函数)
通过上述两式就可画出最佳分割超平面,和对未知数据做出决策。
常见的核函数有(摘自Wikipedia):
- Polynomial (homogeneous):
- Polynomial (inhomogeneous):
- Gaussian radial basis function:
, for
. Sometimes parametrized using
- Hyperbolic tangent:
, for some (not every)
and




注:大部分的机器学习任务使用这些核函数都可以得到解决。