学习表关系的序列化和反序列表查询之前,新建项目的准备工作及环境搭建的配置。
配置:settings.py
INSTALLED_APPS = [ # ... 'rest_framework', ] DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'dg_proj', 'USER': 'root', 'PASSWORD': '123', } } # 连接mysql数据库 """ 任何__init__文件 import pymysql pymysql.install_as_MySQLdb() """ # 国际化处理 LANGUAGE_CODE = 'zh-hans' TIME_ZONE = 'Asia/Shanghai' USE_I18N = True USE_L10N = True USE_TZ = False # 静态文件的环境配置 MEDIA_URL = '/media/' MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
路由:urls.py
# 主路由url from django.conf.urls import url, include from django.contrib import admin from django.views.static import serve from django.conf import settings urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^api/', include('api.urls')), # 路由的分发 url(r'^media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}), ] # 子路由(app01) from django.conf.urls import url from . import views urlpatterns = [ ]
关键参数的设置
""" 外键处理: 反向查询名字:related_name 表关系:db_constraint + on_delete db_constraint=False => 断开表关系 on_delete=models.CASCADE 级联 on_delete=models.SET_NULL, null=True 设置为空 on_delete=models.SET_DEFAULT, default=0 设置成默认值0 on_delete=models.DO_NOTHING 不处理 注:多对多关系不需要明确on_delete """
多表设计
""" Book表:name、price、img、authors、publish、is_delete、create_time Pbulish表:name、address、is_delete、create_time Author表:name、age、is_delete、create_time AutherDetail表:mobile、author、is_delete、create_time BaseModel基表 is_delete、create_tiime 上面四个表的创建继承基表。可以继承两个字段 """
基表BaseModel:
把表相同的字段单独创建出来形成基表,让其他表直接继承即可。
class BaseMode(models.Model): is_delete = models.BoolenanField(defalut=False) create_time = models.DateTimeField(auto_now_add=True) # 设置 abstract =True 来声明基表,作为基表的Model不能在数据库中形成对应的表 class Meta: abstract = True
源码分析得出的参数:
设置 abstract =True 来声明基表,作为基表的Model不能在数据库中形成对应的表
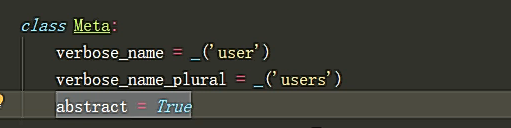
断关表多表关系
知识点(重点)
""" 1、外键位置: 一对多 - 外键放多的一方 一对一 - 从逻辑正反向考虑,如作者表与作者详情表,作者删除级联删除详情, 详情删除作者依旧存在,所以建议外键在详情表中 多对多 - 外键在关系表中 2、ORM正向方向连表查找: 正向:通过外键字段 eg: author_detial_obj.author 反向:通过related_name的值 eg:author_obj.detail 注:依赖代码见下方 3、连表操作关系: 1)作者删除,详情级联 - on_delete=models.CASCADE 2)作者删除,详情置空 - null=True, on_delete=models.SET_NULL 3)作者删除,详情重置 - default=0, on_delete=models.SET_DEFAULT 4)作者删除,详情不动 - on_delete=models.DO_NOTHING 注:拿作者与作者详情表举例 4、外键关联字段的参数 - 如何实现 断关联、目前表间操作关系、方向查询字段 i)作者详情表中的 author = models.OneToOneField( to='Author', related_name='detail', db_constraint=False, on_delete=models.CASCADE ) ii)图书表中的 publish = models.ForeignKey( to='Publish', related_name='books', db_constraint=False, on_delete=models.DO_NOTHING, ) authors = models.ManyToManyField( to='Author' related_name='books', db_constraint=False, ) 注:ManyToManyField不能设置on_delete,OneToOneField、 ForeignKey必须设置on_delete(django1.x系统默认级联, 但是django2.x必须手动明确) """
多表的设计 model.py
from django.db import models # 图书管理系统:Book、Author、AuthorDetail、Publish """ Book表: name、price、img、authors、publish、is_delete、create_time Publish表: name、address、is_delete、create_time Author表: name、age、is_delete、create_time AuthorDetail表: mobile, author、is_delete、create_time """ # 1) 基表 class BaseModel(models.Model): is_delete = models.BooleanField(default=False) create_time = models.DateTimeField(auto_now_add=True) # 作为基表的Model不能在数据库中形成对应的表,设置 abstract = True class Meta: abstract = True class Book(BaseModel): """name、price、img、authors、publish、is_delete、create_time""" name = models.CharField(max_length=64) price = models.DecimalField(max_digits=5, decimal_places=2) img = models.ImageField(upload_to='img', default='img/default.jpg') publish = models.ForeignKey( to='Publish', db_constraint=False, # 断关联 related_name='books', # 反向查询字段:publish_obj.books 就能访问所有出版的书 on_delete=models.DO_NOTHING, # 设置连表操作关系 ) authors = models.ManyToManyField( to='Author', db_constraint=False, related_name='books' ) # 序列化插拔式属性 - 完成自定义字段名完成连表查询 @property def publish_name(self): return self.publish.name
# 可插拔设计 @property def author_list(self): return self.authors.values('name', 'age', 'detail__mobile').all() class Meta: db_table = 'book' verbose_name = '书籍' verbose_name_plural = verbose_name def __str__(self): return self.name
class Publish(BaseModel): """name、address、is_delete、create_time""" name = models.CharField(max_length=64) address = models.CharField(max_length=64) class Meta: db_table = 'publish' verbose_name = '出版社' verbose_name_plural = verbose_name def __str__(self): return self.name class Author(BaseModel): """name、age、is_delete、create_time""" name = models.CharField(max_length=64) age = models.IntegerField() class Meta: db_table = 'author' verbose_name = '作者' verbose_name_plural = verbose_name def __str__(self): return self.name class AuthorDetail(BaseModel): """mobile, author、is_delete、create_time""" mobile = models.CharField(max_length=11) author = models.OneToOneField( to='Author', db_constraint=False, related_name='detail', on_delete=models.CASCADE, ) class Meta: db_table = 'author_detail' verbose_name = '作者详情' verbose_name_plural = verbose_name def __str__(self): return '%s的详情' % self.author.name
一对一的外键字段设计需要的参数:
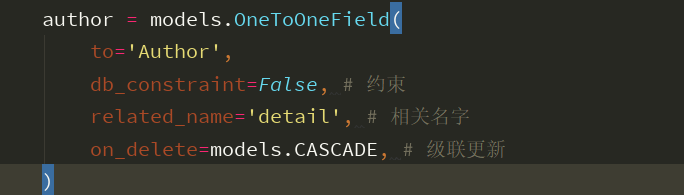
多对多和一对多的设计,所需的指定的参数:

建立好表关系之后,执行数据库迁移命名,创建表结构,创建超级用户,在admin后台做添加录入数据的操作。
序列化
序列化层:app01/serialiaers.py
from rest_framework.serializers import ModelSerializer, SerializerMethodField from rest_framework.exceptions import ValidationError from . import models # 可以单独作为Publish接口的序列化类,也可以作为Book序列化外键publish辅助的序列化组件 class PublishModelSerializer(ModelSerializer): class Meta: model = models.Publish fields = ('name', 'address') class BookModelSerializer(ModelSerializer): # 了解: 该方式设置的序列化字段,必须在fields中声明 # publish_address = SerializerMethodField() # def get_publish_address(self, obj): # return obj.publish.address # 自定义连表深度 - 子序列化方式 - 该方式不能参与反序列化,使用在序列化反序列化共存时,不能书写 publish = PublishModelSerializer() class Meta: # 序列化类关联的model类 model = models.Book # 参与序列化的字段 fields = ('name', 'price', 'img', 'author_list', 'publish') # 了解知识点 # 所有字段 # fields = '__all__' # 与fields不共存,exclude排除哪些字段 # exclude = ('id', 'is_delete', 'create_time') # 自动连表深度 # depth = 1
视图层:api/views.py
class Book(APIView): def get(self, request, *args, **kwargs): pk = kwargs.get('pk') if pk: try: book_obj = models.Book.objects.get(pk=pk, is_delete=False) book_data = serializers.BookModelSerializer(book_obj).data except: return Response({ 'status': 1, 'msg': '书籍不存在' }) else: book_query = models.Book.objects.filter(is_delete=False).all() book_data = serializers.BookModelSerializer(book_query, many=True).data return Response({ 'status': 0, 'msg': 'ok', 'results': book_data })
路由层:api/urls.py
urlpatterns = [ url(r'^books/$', views.Book.as_view()), url(r'^books/(?P<pk>.*)/$', views.Book.as_view()), ]
反序列化
序列化层:app01/serializers.py
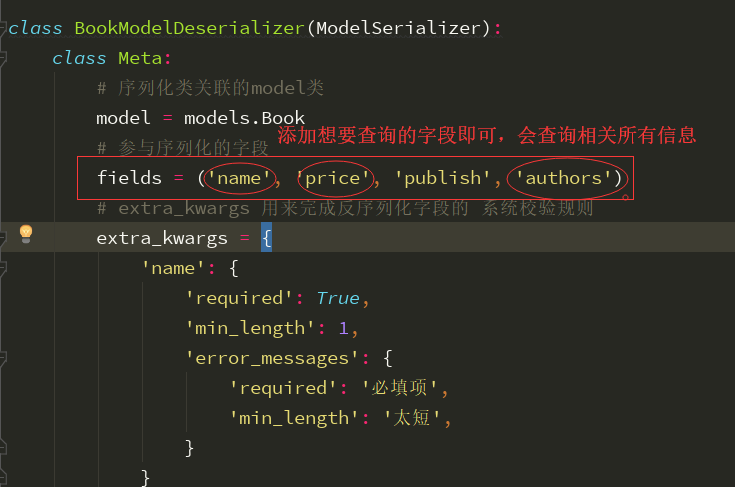
class BookModelDeserializer(ModelSerializer): class Meta: model = models.Book fields = ('name', 'price', 'publish', 'authors') # extra_kwargs 用来完成反序列化字段的 系统校验规则 extra_kwargs = { 'name': { 'required': True, 'min_length': 1, 'error_messages': { 'required': '必填项', 'min_length': '太短', } } } # 局部钩子 def validate_name(self, value): # 书名不能包含 g 字符 if 'g' in value.lower(): raise ValidationError('该g书不能出版') return value # 全局钩子 def validate(self, attrs): publish = attrs.get('publish') name = attrs.get('name') if models.Book.objects.filter(name=name, publish=publish): raise ValidationError({'book': '该书已存在'}) return attrs # ModelSerializer类已经帮我们实现了 create 与 update 方法
视图层:app01/views.py
from rest_framework.response import Response from rest_framework.views import APIView from . import models, serializers class Book(APIView): def post(self, request, *args, **kwargs): request_data = request.data book_ser = serializers.BookModelDeserializer(data=request_data) # raise_exception=True:当校验失败,马上终止当前视图方法,抛异常返回给前台 book_ser.is_valid(raise_exception=True) book_obj = book_ser.save() return Response({ 'status': 0, 'msg': 'ok', 'results': serializers.BookModelSerializer(book_obj).data })
路由层:app01/urls.py
urlpatterns = [ url(r'^books/$', views.Book.as_view()), url(r'^books/(?P<pk>.*)/$', views.Book.as_view()), ]
序列化与反序列化组合使用(重点)
(1)、fields中设置所有序列化与反序列化字段
(2)、extra_kwargs划分只序列化字段
wirte_only:只反序列化
read_only:只序列化
自定义字段默认只序列化(read_only)
(3)、设置反序列化所需的系统、局部钩子、全局钩子等校验规则
序列化层:app01/serialzers.py
class V2BookModelSerializer(ModelSerializer): class Meta: model = models.Book fields = ('name', 'price', 'img', 'author_list', 'publish_name', 'publish', 'authors') extra_kwargs = { 'name': { 'required': True, 'min_length': 1, 'error_messages': { 'required': '必填项', 'min_length': '太短', } }, 'publish': { 'write_only': True }, 'authors': { 'write_only': True }, 'img': { 'read_only': True, }, 'author_list': { 'read_only': True, }, 'publish_name': { 'read_only': True, } } def validate_name(self, value): # 书名不能包含 g 字符 if 'g' in value.lower(): raise ValidationError('该g书不能出版') return value def validate(self, attrs): publish = attrs.get('publish') name = attrs.get('name') if models.Book.objects.filter(name=name, publish=publish): raise ValidationError({'book': '该书已存在'}) return attrs
视图层:app01/views.py
class V2Book(APIView): # 单查:有pk # 群查:无pk def get(self, request, *args, **kwargs): pk = kwargs.get('pk') if pk: try: book_obj = models.Book.objects.get(pk=pk, is_delete=False) book_data = serializers.V2BookModelSerializer(book_obj).data except: return Response({ 'status': 1, 'msg': '书籍不存在' }) else: book_query = models.Book.objects.filter(is_delete=False).all() book_data = serializers.V2BookModelSerializer(book_query, many=True).data return Response({ 'status': 0, 'msg': 'ok', 'results': book_data }) # 单增:传的数据是与model对应的字典 # 群增:传的数据是 装多个 model对应字典 的列表 def post(self, request, *args, **kwargs): request_data = request.data if isinstance(request_data, dict): many = False elif isinstance(request_data, list): many = True else: return Response({ 'status': 1, 'msg': '数据有误', }) book_ser = serializers.V2BookModelSerializer(data=request_data, many=many) # 当校验失败,马上终止当前视图方法,抛异常返回给前台 book_ser.is_valid(raise_exception=True) book_result = book_ser.save() return Response({ 'status': 0, 'msg': 'ok', 'results': serializers.V2BookModelSerializer(book_result, many=many).data }) # 单删:有pk # 群删:有pks | {"pks": [1, 2, 3]} def delete(self, request, *args, **kwargs): pk = kwargs.get('pk') if pk: pks = [pk] else: pks = request.data.get('pks') if models.Book.objects.filter(pk__in=pks, is_delete=False).update(is_delete=True): return Response({ 'status': 0, 'msg': '删除成功', }) return Response({ 'status': 1, 'msg': '删除失败', })
路由层:app01/urls.py
urlpatterns = [ url(r'^v2/books/$', views.V2Book.as_view()), url(r'^v2/books/(?P<pk>.*)/$', views.V2Book.as_view()), ]
补充知识点:
自定义子序列化深度连表查询
api/serializers.py
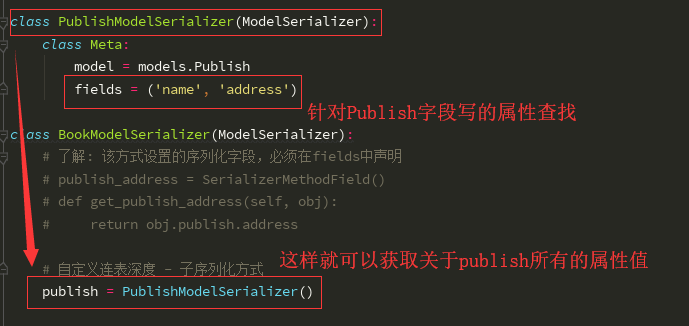
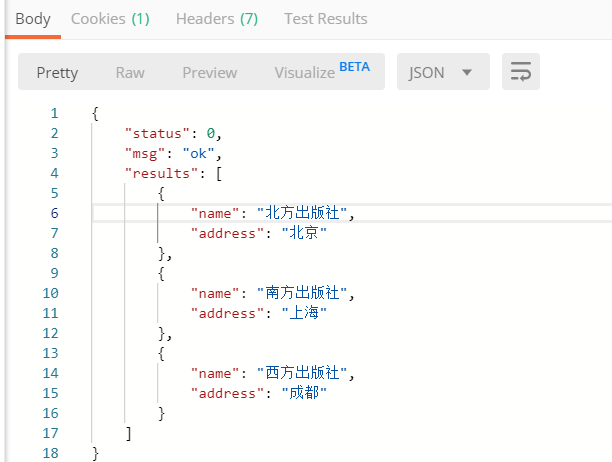
有postman GET请求urls中的publish 获取后台的数据。
可插拔序列化设计
在models.py中book字段的设计

群增就接口的实现
# 单增:传的数据是与model对应的字典 # 群增:传的数据是 装多个model对应字典 的列表
crf框架内封装置重写了create的方法来实现群增的功能

views.py,关键字:many=True
# 单增:传的数据是与model对应的字典 # 群增:传的数据是 装多个 model对应字典 的列表 def post(self, request, *args, **kwargs): request_data = request.data if isinstance(request_data, dict): many = False elif isinstance(request_data, list): many = True else: return Response({ 'status': 1, 'msg': '数据有误', }) book_ser = serializers.V2BookModelSerializer(data=request_data, many=many).data #获取的是数据对象 # 当校验失败,马上终止当前视图方法,抛异常返回给前台 book_ser.is_valid(raise_exception=True) book_result = book_ser.save() return Response({ 'status': 0, 'msg': 'ok', 'results': serializers.V2BookModelSerializer(book_result, many=many).data })
单删群删的接口实现
views.py
# 单删:有pk # 群删:有pks | {"pks": [1, 2, 3]} def delete(self, request, *args, **kwargs): pk = kwargs.get('pk') if pk: pks = [pk] else: pks = request.data.get('pks') if models.Book.objects.filter(pk__in=pks, is_delete=False).update(is_delete=True): return Response({ 'status': 0, 'msg': '删除成功', }) return Response({ 'status': 1, 'msg': '删除失败', })