转自
https://www.cnblogs.com/xiaozengzeng/p/12078845.html
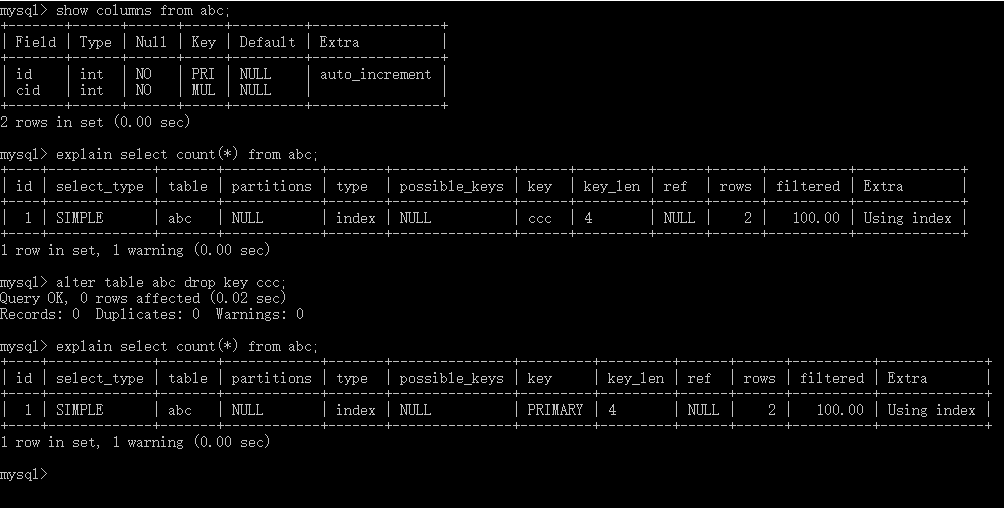
结论就是对于COUNT(1)和COUNT(*)执行优化器的优化是完全一样的,并没有COUNT(1)会比COUNT(*)快这个说法
- 目前基于磁盘的数据库或者搜索引擎(比如Lucene)的性能瓶颈主要都是在IO阶段,相比于CPU和RAM,IO操作实在太慢了,所以这类系统的优化方向也都都是类似的——尽一切可能减少IO的次数(所以很多用ES的程序在性能优化到极限的时候选择直接上SSD)。这里统计行数的操作,查询优化器的优化方向就是选择能够让IO次数最少的索引,也就是基于占用空间最小的字段所建的索引(每次IO读取的数据量是固定的,索引占用的空间越小所需的IO次数也就越少)。而Innodb的主键索引是聚簇索引(包含了KEY,除了KEY之外的其他字段值,事务ID和MVCC回滚指针)所以主键索引一定会比二级索引(包含KEY和对应的主键ID)大,也就是说在有二级索引的情况下,一般COUNT()都不会通过主键索引来统计行数,在有多个二级索引的情况下选择占用空间最小的。
- 如果说有张Innodb的表只有主键索引,而且记录还比较大(比如30K),则统计行的操作会非常慢,因为IO次数会很多(这里就不做实验截图了,有兴趣可以自己试一下)。
- 一个优化方案就是预先建一个小字段并建二级索引专门用来统计行数,极端情况下这种优化速度提高上千倍也是正常的。
我的实验:证明mysql在没有二级索引下只会用主键索引