题记:
这是工作以来困扰我最久的问题。python 进程内存占用问题。
经过长时间断断续续的研究,终于有了一些结果。
项目(IM服务器)中是以C做底层驱动python代码,主要是用C完成 网络交互部分。随着用户量和用户数据的增加,服务器进程内存出现持续上升(基本不会下降),导致需要经常重启服务器,这也是比较危险的信号。
因此便开始了python内存研究之路。
1、业务代码问题
开始是怀疑业务代码问题,可能出现了内存泄漏,有一些对象没有释放。
于是便检查一些全局变量,和检查有没有循环引用导致对象没有释放。
a、全局变量问题:
发现有一些全局变量(缓存数据)没有做定时清理,于是便加上一些定时清理机制,和缩短一些定时清理的时间。
结果:确实清理了不少对象,但是对整体内存占用情况并没有改善多少。
b、循环引用问题:
使用python的gc模块可发现,并没有循环引用的对象,具体可参考 gc.garbage,gc.collect,gc.disable 等方法。
参考:
http://www.cnblogs.com/Xjng/p/5128269.html
https://www.cnblogs.com/xybaby/p/7491656.html#_label_9
结论:内存上涨和业务代码关系不大
2、python内存管理问题
python 有自己一套缓存池机制,可能是缓存池持续占用没有释放导致,于是便开始研究python缓存池机制。
python中一些皆为对象,所有对象都继承自 type(PyType_Type),但内建类型具体的内存管理不太一样。
a、int对象:
int对象一旦申请了内存空间,就不会再释放,销毁的int对象的内存会由一个 free_list 数组管理,等待下次复用。
因此int 对象占用进程的内存空间,总为int对象最多的时候,等到进程结束后才会把内存返回给操作系统。(python3.x则会调用free)
python启动时会先创建int小整数对象做缓存池用([-5, 256])。
b、string对象:
字符串对象释放后则会调用free。
对于长度为0的字符串会直接返回 nullstring对象,长度唯一的对象则用 characters 数组管理,长度大于1的对象则使用interned机制(interned 字典维护)。
c、其他变长对象(list、dict、tuple等):
list有一个大小有80的free_list缓存池,用完后申请释放直接用malloc和free;
dict和list一样有一个大小为80的free_list缓存池,机制也一样;
tuple有长度为[0, 19]的缓存池,长度为0的缓存池只有一个,其余19个缓冲池最多能有2000个,存放长度小于20的元组,长度超过20或对应长度缓冲池满了则直接用malloc和free;
接下来分析Python的缓存池机制:
python内存池主要由 block、pool、arena组成,其中block在代码中没有实体代码,不过block都是8字节对齐;
block由pool管理,所有512字节以下的内存申请会根据申请字节的大小分配不一样的block,一个pool通常为4K(系统页大小),一个pool管理着一堆固定大小的内存块(block);
* Request in bytes Size of allocated block Size class idx
* ----------------------------------------------------------------
* 1-8 8 0
* 9-16 16 1
* 17-24 24 2
* 25-32 32 3
* 33-40 40 4
* 41-48 48 5
* 49-56 56 6
* 57-64 64 7
* 65-72 72 8
* ... ... ...
* 497-504 504 62
* 505-512 512 63
*
* 0, SMALL_REQUEST_THRESHOLD + 1 and up: routed to the underlying
* allocator.
*/
pool有arena管理,一个arena为256KB,但pyhton申请小内存是不会直接使用arena的,会使用use_pools:
pool = usedpools[size + size];
if pool可用:
pool 没满, 取一个block返回
pool 满了, 从下一个pool取一个block返回
否则:
获取arena, 从里面初始化一个pool, 拿到第一个block, 返回
参考
python 中大部分对象都小于512B,故python主要还是使用内存池;
再看下python的垃圾回收机制:
python使用的是gc垃圾回收机制,主要由引用计数(主要), 标记清除, 分代收集(辅助)。
引用计数:每次申请或释放内存时都增减引用计数,一旦没有对象指向该引用时就释放掉;
标记清除:主要解决循环引用问题;
分代收集:划分三代,每代的回收检测时间不一样;
到这一步,卡了比交久,修改了python源码,打印了pool和arena的情况(重编译python后可提现),
arena的大小只占了服务器进程占用内存大小的一小部分,后面发现是python版本比较旧,使用pool的阈值是256B,但是在64位系统上python的dict(程序里比较多的对象)的大小为300+B,就不会使用内存池。
故把python升级到2.7.14(阈值已被修改为512),arena的相对大小比较合理,占了近半进程内存。
这里分析是否合理的方法,就是打印python进程中各对象的数量以及大小,一个方法是利用gc,因为大部分内存申请会经过gc,使用gc.get_objects可以获取gc管理的所有对象,然后再按类型区分,可获取不同类型的对象的数量以及大小;另一种方法是直接使用第三方工具guppy,也可打印这些信息。(不过这两种方法实现不一样,得到的结果会有一点区别,guppy的分类会更准确)
得到不同对象的数量以及大小后,可以对比arena的情况,看看是否合理了。
结论:python内存管理暂时没发现问题,可能是由其他问题引起。
接下来很长一段时间都在纠结:进程剩下的内存哪去了?
3、malloc内存管理问题
回想一下进程内存分配,包括哪些部分:
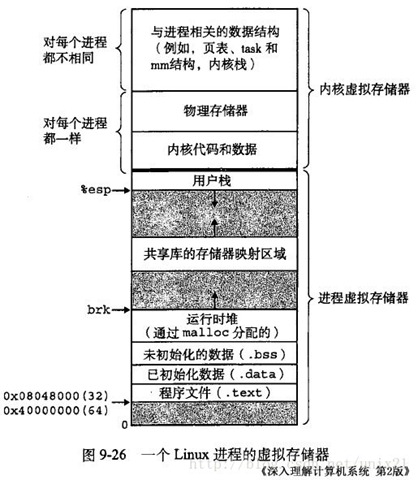
查看 /proc/$PID/status (smaps、maps) 可以看到上图中对应的 进程的信息,可发现堆分配(和映射区域)是占了绝大部分的内存的。
python的内存申请主要使用的malloc,malloc的实现主要是 brk和mmap,
brk实现是malloc方法的内存池实现,默认小于128KB的内存都经常brk,大于的则由mmap直接想系统申请和释放。
使用brk的缓存池主要是考虑cpu性能,如果所有内存申请都由mmap管理(直接向系统申请),则会触发大量的系统调用,导致cpu占用过高。
brk的缓存池就是为了解决这个问题,小内存(小于128KB)的申请和释放在缓存池进行,减少系统调用减低cpu消耗。
使用C函数 mallinfo、malloc_stats、malloc_info等函数可以打印出brk、mmap内存分配、占比的情况。
本来阈值128KB是固定的,后来变成动态改变,变为随峰值的增加而增加,所以大部分对象使用brk申请了。虽然brk方法申请的内存也可以复用和内存紧缩,但是内存紧缩要等到高地址的内存释放后才能进行,这很容易导致内存不释放。
于是便使用 mallopt 调整M_MMAP_THREASHOLD 和 M_MMAP_MAX,让使用brk的阈值固定在128KB,调整后再本地进行测试。可以观察到mmap内存占比增加了,系统调用次数增加,在申请和释放大量Python对象后进程内存占用少了20%-30%。
系统调用次数查询:
可通过以下命令查看缺页中断信息
ps -o majflt,minflt -C <program_name>
ps -o majflt,minflt -p <pid>
其中:: majflt 代表 major fault ,指大错误;minflt 代表 minor fault ,指小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
其中 majflt 与 minflt 的不同是::majflt 表示需要读写磁盘,可能是内存对应页面在磁盘中需要load 到物理内存中,也可能是此时物理内存不足,需要淘汰部分物理页面至磁盘中。
参考:
结论:malloc中的brk使用阈值动态调整,虽然降低了cpu负载,但是却间接增加了内存碎片(brk使用缓存),在库定后内存使用下降了20%-30%。
4、是否还存在其他问题
4.1、理解进程的内存占用情况后,python缓存好像优点占用过高,可以回头再仔细分析;
4.2、据说使用jemalloc或tcmalloc会有提升,准备试用;
更新至2018-4-16
5、jemalloc
今天测试了jemalloc,现在总结一下:
5.1、安装使用:
a、下载:https://github.com/jemalloc/jemalloc/releases jemalloc-5.0.1.tar.bz2
b、安装:
./configure –prefix=/usr/local/jemalloc
make -j8
make install
c、编译时使用:
gcc -g -c -o 1.o 1.c
gcc -g -o 1.out 1.o -L/usr/local/jemalloc/lib -ljemallocd、运行时可能会报错,找不到库:
此时需要把libjemalloc.so.2 放到可寻找到的路径中就行
我的做法是:
先查看依赖库是否找到位置:ldd xxx (xxx是可运行文件)把libjemalloc.so.2放到 /lib 下:ln -s /usr/local/jemalloc/lib/libjemalloc.so.2 /lib/libjemalloc.so.2 (我这里使用软链接)
在用ldd xxx可以看到依赖库可发现了

5.2、使用效果:
同样条件测试,内存占用变化不大(这里主要关注的是内存使用率不是cpu使用率);
参考:
https://blog.csdn.net/xiaofei_hah0000/article/details/52214592
结论:测试使用jemalloc,暂无明显变化。
更新至2018-4-17
安装tcmalloc,使用静态库编译可执行文件,对比原来的方法、jemalloc方法(使用动态库,5.0.1版本)和tcmalloc方法(使用静态库,2.7版本):
开了三个进程,里面定时加载、清除数据(3000个用户私有数据,加载后内存增加300M),在运行4~5个小时后,tcmalloc 比原来 的方法内存占用少10%~15%,jemalloc方法比tcmalloc方法内存占用少5%~10%;使用jemalloc和tcmalloc都能优化内存碎片的问题,而jemalloc方法的效果会更好些。(tcmalloc、jemalloc源码直接使用,未改源码、未调参数情况)
更新至2018-5-29
在正式服务器环境中连续运行一个月,tcmalloc占用内存比原来的ptmalloc 少了 25%,效果显著!
更新至2018-6-11