摆渡车(题目和测试右转 洛谷P5017)
做法:dp+各种优化(剪枝)
这道题考场上看了一脸懵逼...第一眼看这 tm 不是个一维dp吗...结果按着这个朦胧的思路,删删改改约莫0.5h,终于过了小样例,然后一测大样例...GG了。冥思苦想了1h,最终放弃了 (感谢这白费的1.5h,迫使我T4打了个暴力,结果AC了...)
言归正传
考试完后,参考了各种题解,WA了N/A次,终于AC了这道毒瘤题,艰难的AC历程...
(〇)引子
首先来阐明一下题意:在一条数轴上有n个点,然后要求将这条数轴分为若干段(左开右闭的区间),要求:每段的两个端点之间的距离必须 >= m,求分段的最小总费用。
费用定义为:若一个点k在区间 ( j , i ] ,则这个点的费用为 i - k (可能一个位置上有多个点)
总费用定义为:所有点的费用和即为总费用
(一)如何拿分(暴力?)
讲解完题意,接下来我们要研究一个很重要的问题:如何拿分?
先看 30% 的数据:
n≤20, m≤2, 0≤ti≤100
看着 ti 的大小很容易想到用一维数组 f[i] 表示在第 i 分钟发车的最小费用。
然后,这TM不是个一维线性dp吗?
我们可以枚举一个 j ,即枚举前一次是在哪里发车的,这样我们便得到了状态转移方程:

这样一来,时间复杂度就是 ![]() ,30%的数据是可以过的。
,30%的数据是可以过的。
(二)如何拿中分(不高也不低的分)
看一下50%的数据:
n ≤ 500, m ≤ 100, 0 ≤ ti ≤ 10^4
nt^2的时间复杂完全过不了50%得数据,怎么办呢
通过观察(一)的状态转移方程,可以发现枚举一个k实际上是没必要的,可以用前缀和优化:
将等车人到达的时间用数组存起来,peo[ i ]表示在 0 到 i 分钟内等车人的数量,cost[ i ]表示在 0 到 i 分钟所有等车人到达时间的累积(即将 1 到 i 分钟内到达的等车人的到达时间累加起来)
就可以得到状态转移方程
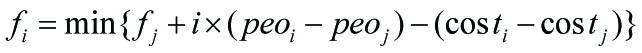
分析一下时间复杂度:因为只枚举了 i 和 j ,所以时间复杂度降低为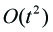
50%的数据在 “少爷机” 上是稳稳的。
程序段:
1 for(int i=1; i<t+m; i++) 2 { 3 f[i] = i*peo[i] - cost[i]; 4 for(int j=0; j<=i-m; j++) 5 f[i] = min(f[i], f[j]+(peo[i]-peo[j])*i-(cost[i]-cost[j])); 6 }
(三)如何拿高分(不是满分,考场上的高分)
自然是优化啦。问题来了,如何优化。
先看看70%的数据范围:
n≤500, m≤10, 0≤ti≤4×10^6
很明显,t^2的时间复杂的是肯定超的。而 i 是这个状态转移方程的状态,必须要枚举,只能从 j 下手,优化这个动态规划了。
j 如何优化呢?其实,仔细想一想,很容易发现,j 没有必要从 0 枚举到 i-m,换句话说,从0到 i-m 的这段区间内,有很多状态是无用的,即这些状态一定不能构成当前 f[i] 的最优解,真正有用的只有区间 ( i-m-m+1, i-m ]。如何证明呢?
先贴一幅图:
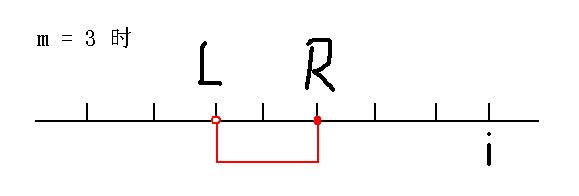
观察上图可以发现:
当 j 在 ( R, i )中时,摆渡车回来的时间一定大于 i ,不满足状态 f[i] 的定义,舍去。
当 j 在 ( ?, L ]中时,一定可以多发一次车,使摆渡车回来的时间小于等于 i,这样得到的花费一定小于等于只发一次车的情况。因此,也可以省去。
最后,我们发现,j 只能在区间 ( L, R ] 之间才能得到最小花费,即 j 只有 m-1 种情况。
于是,状态转移方程不变,j 的枚举范围改变,时间复杂度降为
70%的数据稳稳地过,甚至在 “少爷机” 上面的 score 可能 100 ( 最起码分数在70以上 )。
程序段:
1 for(int i=1; i<t+m; i++) 2 { 3 f[i] = i*peo[i] - cost[i]; 4 for(int j=max(i-m-m+1,0); j<=i-m; j++) 5 f[i] = min(f[i], f[j]+(peo[i]-peo[j])*i-(cost[i]-cost[j])); 6 }
(四)70+太低了如何拿满分
老样子,再来看一下数据范围(终极boss来了):
n≤500, m≤100, 0≤ti≤4×10^6
m的范围变回 100 了,tm的时间复杂度好方,肿么办!!!
别着急,先来分析一下数据范围:
可以发现,ti 达到了4*10^6 ,然鹅 n 却还是500,不难想象,如果将 ti 看做一条线段,上面有 4*10^6个整点,然后取其中的500个点标记,标记的点一定是非常离散的。
同样的道理,在如此之大的 ti 中,一定有很多区间是没有等车人的(无用的区间),但是仍然无用地枚举了m次,时间复杂度大大增加。
这时候,我们只需要加一个小小的剪枝,判断当前枚举的 i 点到 i-m 中是否有人,如果没有人的话,就没有必要进行多一次的循环了(因为再发多一次车对答案没有影响,毕竟没人),只需要将 f[i] 赋值为 f[i-m],然后continue即可。
经过某神犇的证明,经过这次剪枝后,实际枚举的点只有 nm 个,时间复杂度降为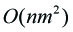 (当然还有一个常数 t 被我忽略了)
(当然还有一个常数 t 被我忽略了)
100%的数据跑得飞快……
程序段:
1 for(int i=1; i<t+m; i++) 2 { 3 if(i>=m and peo[i]-peo[i-m] == 0) {f[i] = f[i-m]; continue;} 4 f[i] = i*peo[i] - cost[i]; 5 for(int j=0; j<=i-m; j++) 6 f[i] = min(f[i], f[j]+(peo[i]-peo[j])*i-(cost[i]-cost[j])); 7 }
(五)答案在哪?
终于到最后一步了,显而易见,answer一定在最大的时间后面(废话),只需要从 t 枚举到 t+m-1 取一个最小值即可。
注意:
代码中的 t 和 (五)中的 t 含义相同,都是最后到的那个人的到达时间。
ps:终于写完了,这个思路是参考了某神犇的(@Sooke),再加上了自己的一些理解,希望能有帮助。