内存是当今世界上被广泛浪费的硬件资源之一。由于编程效率低下,惊人量的内存浪费被浪费了。这种模式在多个企业应用程序中重复出现。为了证明这种情况,我们进行了一项小型研究。我们分析了著名的spring boot pet诊所应用程序,以查看浪费了多少内存。该应用程序是由spring社区设计的,旨在显示spring应用程序框架如何用于构建简单但功能强大的面向数据库的应用程序。
源码地址:https://github.com/spring-projects/spring-petclinic
环境准备
- Spring Boot 2.1.4
- Java SDK 1.8
- Tomcat 8.5.20
- MySQL 5.7.26
压力测试
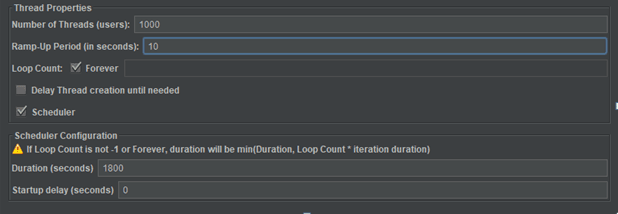
我们使用了流行的开源负载测试工具Apache JMeter进行压力测试。我们使用以下设置执行了30分钟的负载测试:
- 线程数(用户)– 1000(连接到目标的用户数)
- 加速周期(以秒为单位)–所有请求开始的时间范围。根据我们的配置,每0.01秒,将启动1个新线程,即100个线程/秒。
- 循环计数–这1000个线程背靠背执行测试迭代。
- 持续时间(秒)–加速后,1000个线程连续运行1800秒。
我们在负载测试中采用了以下方案:
- 将新的宠物主人添加到系统。
- 查看有关宠物主人的信息。
- 向系统添加新宠物。
- 查看有关宠物的信息。
- 将有关访问的信息添加到宠物的访问历史中。
- 更新有关宠物的信息。
- 更新有关宠物主人的信息。
- 通过搜索其姓名查看所有者信息。
- 查看所有所有者的信息。
如何测量内存浪费?
业界有数百种工具可以显示所使用的内存量。但是我们很少遇到能够测量由于编程效率低下而浪费的内存量的工具。HeapHero是一个简单的工具,可以分析堆转储并告诉您由于编程效率低而浪费了多少内存。
测试运行时,我们从Spring Boot Pet Clinic应用程序捕获了堆转储。具体方式参考文章:如何获取JVM堆转储文件
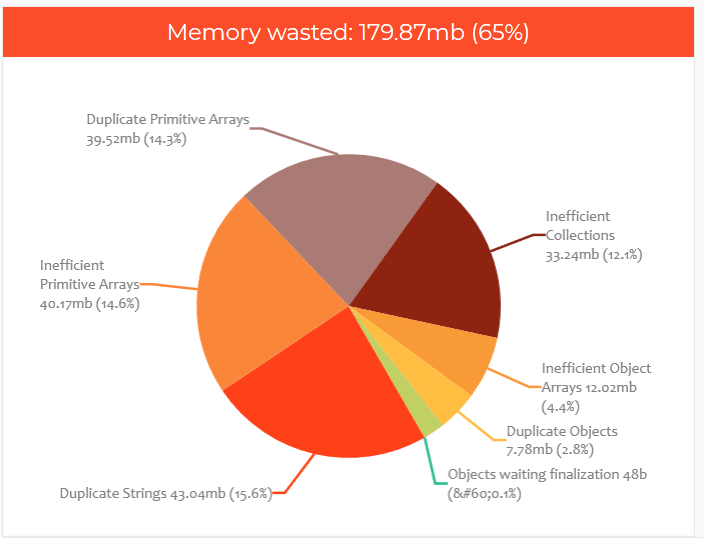
我们将捕获的堆转储上传到HeapHero工具中。工具生成了这个漂亮的报告,显示由于效率低下的编程浪费了65%的内存。是的,这是一个简单的原始应用程序,应该在其中实现所有最佳实践,在一个广为人知的框架上也浪费了65%的内存。
分析内存浪费
从报告中,您可以注意到以下内容:
- 字符串重复导致浪费了15.6%的内存
- 由于原始数组效率低下,浪费了14.6%的内存
- 由于重复的原始数组浪费了14.3%的内存
- 由于收集效率低下,浪费了12.1%的内存
字符串重复
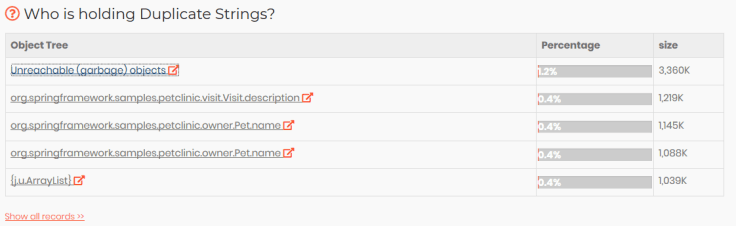
在此Spring启动应用程序(和大多数企业应用程序)中浪费内存的主要原因是字符串重复。该报告显示了由于重复字符串而浪费了多少内存,它们是什么字符串,谁在创建它们以及如何对其进行优化。

您会注意到由于重复的字符串浪费了15.6%的内存。请注意
- 'Goldi'字符串已被创建207,481次。
- “Visit”字符串已创建132,308次。“访问”是我们在测试脚本中提到的描述。
- “Banglore”字符串已创建75,374次。“ Banglore”是我们在测试脚本中指定的城市名称。
- '123123123'已被创建37,687次。
- “ Mahesh”字符串已创建37,687次。
显然,“Goldi”是通过测试脚本在屏幕上输入的宠物的名称。“访问”是通过测试脚本在屏幕上输入的描述。同样,是值。但是有一个问题,为什么要创建相同的字符串对象那么几千次。
我们都知道字符串是不可变的(即一旦创建,就无法修改)。鉴于为什么要创建成千上万个重复的字符串?
HeapHero工具还报告创建这些重复字符串的代码路径。
收款效率低下
在弹簧靴宠物诊所应用中造成内存浪费的另一个主要原因是收集效率低下。以下是HeapHero报告的摘录:

您会注意到,内存中99%的LinkedHashSet中没有任何元素。如果没有元素,为什么还要创建LinkedHashSet?当您创建一个新的LinkedHashSet对象时,将在内存中保留16个元素的空间。现在为这16个元素保留的所有空间都被浪费了。如果对LinedHashset进行延迟初始化,则不会出现此问题。
不良做法:
private LinkedHashSet<String, String>myHashSet = new LinkedHashSet();
public void addData(String key, String value) {
myHashSet.put(key, value);
}
最佳实践:
private LinkedHashSet<String, String>myHashSet;
public void addData(String key, String value) {
If (myHashSet == null) {
myHashSet = new LinkedHashSet();
}
myHashSet.put(key, value);
}
同样,另一个观察结果是:68%的ArrayList中仅包含1个元素。创建ArrayList对象时,将在内存中保留10个元素的空间。这意味着在88%的ArrayList中9个元素的空间被浪费了。如果可以使用容量初始化ArrayList,则可以避免此问题。
不良做法:使用默认值初始化集合。
new ArrayList();
最佳实践:使用容量初始化集合
new ArrayList(1);
内存不便宜
一个人可以反驳说,内存是如此便宜,那么为什么我要担心它呢?公平的问题。但是在云计算时代,我朋友的记忆并不便宜。有4种主要的计算资源:中央处理器、内存、网络、存储。
您的应用程序可能在AWS EC2实例上运行的数十万个应用程序服务器上运行。在上述4种计算资源中,哪个资源在EC2实例中已饱和?
对于大多数应用程序,它是内存。CPU始终为30 – 60%。总是有大量的存储空间。很难饱和网络(除非您的应用程序正在流式传输大量视频内容)。因此,对于大多数应用程序来说,首先是内存饱和。即使CPU,存储和网络未充分利用,仅由于内存变得饱和,您最终还是会配置越来越多的EC2实例。这将使您的计算成本增加几倍。
另一方面,由于编程效率低下,现代应用程序无一例外地浪费了30%-90%的内存。即使在没有太多业务逻辑的Spring Boot宠物诊所之上,也浪费了65%的内存。实际的企业应用程序将浪费相似的数量,甚至更多。因此,如果您可以编写内存有效的代码,那么它将降低您的计算成本。由于内存是第一个达到饱和的资源,因此,如果可以减少内存消耗,则可以在较少数量的服务器实例上运行应用程序。您也许可以减少30 – 40%的服务器。这意味着您的管理层可以减少30%-40%的数据中心(或云托管提供商)成本,再加上维护和支持成本。它可以节省数百万/数十亿元的成本。
结论
除了减少计算成本,编写内存效率高的代码后,您的客户体验也将变得更好。如果您可以减少为服务新的传入请求而创建的对象数量,则响应时间将大大缩短。由于创建的对象较少,因此在创建和垃圾回收对象上将花费较少的CPU周期。减少响应时间将提供更好的客户体验。
- 郑重声明:公众号“FunTester”首发,欢迎关注交流,禁止第三方转载。更多原创文章:FunTester十八张原创专辑,合作请联系
Fhaohaizi@163.com。