一、基本定义
定义:函数是指将一组语句的集合通过一个名字(函数名)封装起来,要执行这个函数,只需要调用其函数名即可。
特性:
-
减少重复代码
-
使程序变得可扩展
-
使程序变得易维护
语法定义:
def person(): # 函数名
print("风清扬")
person() # 调用函数
带参数的函数:
a,b = 2,3
c= a ** b
print(c)
# 改为函数:
def calc(x,y):
val = x**y
return val # 返回函数执行的结果
c = calc(2,3) # 结果赋值给变量c
print(c)
定义函数时的一些关键内容:
1、要使用 def 这个关键字进行定义。
2、函数的名称建议使用小写单词组成,单词间以下划线分隔(下划线命名法),这样比 较方便理解函数名称的含义。
3、参数是一个自定义的变量名称,通常也是使用小写的单词,用于提示输入的参数内容。
4、定义参数名称与参数以“:”结尾。
5、在定义函数名称与参数的下方,向右缩进编写运算代码的语句块。
6、通过函数名称并写入相应的参数即可调用函数,以实现相应的运算。
二、函数参数
形参变量
只有在被调用才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效,函数调用结束返回主调用函数后则不能再使用该形参变量
实参
可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,他们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等方法使参数获得确定值
def calc(x,y): # x,y为形参
val = x**y
return val
c = calc(2,3) # 2,3为实参
print(c)
默认参数
默认参数可以不传,不传的时候用的就是默认值,如果传会覆盖默认值。
def person(name,sex='女'): # sex为默认参数
print(name,sex)
person('黄蓉') # 黄蓉 女
person('郭靖',sex='男') # 郭靖 男
person('小龙女') # 小龙女 女
person('杨过',sex='男') # 杨过 男
关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可(指定了参数名的参数就叫关键参数),但记住一个要求就是,关键参数必须放在位置参数(以位置顺序确定对应关系的参数)之后
def person(name,book,age=22,sex='女'):
print(name,book,age,sex)
# 调用可以这样
person('黄蓉','射雕',)
person('郭靖',age=23,book='射雕',sex='男')
# 不可以这样
person('小龙女',sex='女','神雕')
person('杨过','神雕',book='神雕',sex='男')
非固定参数
若函数定义时不确定用户想传入多少参数,就可以使用非固定参数
def person(name,age,*args):
print(name,age,args)
person('黄药师',66) # 输出结果:“黄药师 66 ()” 后面这个()就是args,只是因为没传值,所以为空
person('欧阳锋',66,'西毒','蛤蟆功') # 输出结果 : “ 欧阳锋 66 ('西毒','蛤蟆功')”
还有一个**kwargs
def person(name,age,*args,**kwargs):
print(name,age,args,kwargs)
person('黄药师',66) # 输出结果:“黄药师 66 () {}” 后面这个{}就是kwargs,只是因为没传值,所以为空
person('欧阳锋',66,'西毒','蛤蟆功',son='欧阳锋',region='白驼山') # 输出结果 : “ 欧阳锋 66 ('西毒', '蛤蟆功') {'son': '欧阳锋', 'region': '白驼山'}”
三、返回值
函数外部的代码要想获取函数的执行结果,就可以在函数里用return语句把结果返回
def person(name,wife,skill,book):
charater = "姓名:{},妻子:{},武功:{},出自《{}》".format(name,wife,skill,book)
return charater
new_person = person("杨过","小龙女","黯然销魂掌","神雕侠侣")
print(new_person) # 姓名:杨过,妻子:小龙女,武功:黯然销魂掌,出自《神雕侠侣》
注意:函数在执行过程中只要遇到return语句,就会停止执行并返回结果,也可以理解为return语句代表着函数的结束;如果未在函数中指定return,那么这个函数的返回值为None
四、全局与局部变量
name = "杨过"
def person(name):
print("一见{}误终身".format(name)) # 一见杨过误终身
name = "郭襄"
print("里面的name:",name) # 里面的name: 郭襄
person(name)
print("外面的name:",name) # 外面的name: 杨过
book_name = "侠客行"
def book():
book_name = "连城诀"
print(book_name) # 连城诀
book()
-
在函数中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量
-
全局变量作用域是整个程序,局部变量的作用域是定义该变量的函数
-
当全局变量与局部变量同名时,在定义局部变量的函数内,局部变量起作用;在其他地方全局变量起作用。
作用域
作用域(scope),程序设计概念,通常来说,一段程序代码中所用到的名字并不总是有效的/有用的,而限定这个名字的可用性的代码范围就是这个名字的作用域
name = '小昭'
def person():
global name
name = "赵敏"
print("函数内部的name:",name) # 函数内部的name: 赵敏
person()
print("外部的name",name) # 外部的name 赵敏
global name的作用就是要在函数里声明全局变量name,意味着最上面的name="小昭"即使不写,程序最后面的print也可以打印name
五、嵌套函数
name = "东邪"
def person():
name = "西毒"
def person2():
name = "南帝"
print("第三层name:",name)
person2() # 调用内层函数
print("第二层name:",name)
person()
print("最外层name:",name)
#输出结果:
# 第三层name: 南帝
# 第二层name: 西毒
# 最外层name: 东邪
六、匿名函数
匿名函数就是不需要显示的指定函数名
def calc(x,y):
return x**y
print(calc(2,3))
# 换成匿名函数
calc = lambda x,y:x**y
print(calc(2,3))
匿名函数主要和其他函数搭配使用:
res = map(lambda x:x**2,[1,3,5,7])
for i in res:
print(i)
# 输出结果:
# 1
# 9
# 25
# 49
七、高阶函数
变量可以指向函数,函数的参数能接受变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数
def add(x,y,f):
return f(x) + f(y)
res = add(3,-3,abs)
print(res) # 6
只需满足以下任意一个条件,即使高阶函数
-
接受一个或多个函数作为输入
-
return返回另外一个函数
八、递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身,这个函数就是递归函数
def factorial(n): if n==1: return 1 else: return n * factorial(n-1) print(factorial(5)) # 输出结果120
把计算过程中,参数变量的值通过 print 语句显示出来看一下:
def factorial(n):
print(n)
if n==1:
return 1
else:
return n * factorial(n-1)
factorial(5)
输出结果:
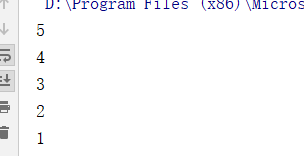
这意味着 print 语句被执行了 5 次,同时也意味着函数被调用了 5 次。继续通过 print 语句把每次通过 return 语句计算的结果也显示出来
def factorial(n):
if n==1:
print(1)
return 1
else:
current = n * factorial(n-1)
print(current)
return current
factorial(5)
输出结果:

这个结果意味着,每次调用函数都会进行一次计算,并且将计算结果通过 return 语句返回。
示意图:

上方 5 个色块,是代码调用了 5 此函数。 每次调用函数都会创建新的命名空间,可以理解为程序执行了 5 个同名的函数。 既然执行了 5 个函数,就有参数传入和返回结果的过程。
调用函数时,参数传入的过程:
-
函数首次调用时,参数 n 的值为 5;
-
首次调用函数的 return 语句中,进行了第二次调用函数,并设置参数为 n-1;所以, 在第二次调用的函数中,参数 n 的值变成了 4;
-
以此类推,直至终止调用函数自身为止。
接下来,再来看返回函数执行结果的过程:
-
程序调用 5 次函数的同时,进行了参数的传入,第 5 次调用时,参数 n 的值是 1,;此 时,参数数值满足 n == 1 的条件,不再继续调用函数自身,通过 return 语句返回值, 也就是 1;
-
当 1 这个值被返回,程序回到了倒数第 2 次函数调用的 return 语句,此时语句中对函 数的最后一次调用变成了具体的值(1),和变量 n 相乘之后,作为返回值,再次返 回给倒数第 3 次函数调用的 return 语句中;
-
以此类推,直至返回到首次调用的函数为止。
递归特性:
-
必须有一个明确你的结束条件
-
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
-
递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
递归实际应用:二分查找
data = [1,3,6,8,9,11,15,19,20,22,26,30,33,38]
def binary_search(datalist, find_num):
print(datalist)
if len(datalist) > 1:
mid = int(len(datalist)/2)
if datalist[mid] == find_num:
return "找到数字%s" % datalist[mid]
elif datalist[mid] > find_num: # 找的数在mid的左边
print("找到数在mid[%s]左边" % datalist[mid])
return binary_search(datalist[:mid],find_num)
else: # 找的数在mid的右边
print("找到数在mid[%s]右边" % datalist[mid])
return binary_search(datalist[mid+1:], find_num)
else:
if datalist[0] == find_num:
return "找到数字%s" % datalist[0]
else:
return "要找的数字%s不在列表中"% find_num
print(binary_search(data, 3))
九、名称空间
名称空间又称name space,顾名思义就是存放名字的地方,存什么名字呢?举例说明,若变量x=1,1存放于内存中,那名字x存放在哪呢?名称空间正是存放名字x与1绑定关系的地方。
名称空间共3种,分别如下:
-
locals: 是函数内的名称空间,包括局部变量和形参
-
globals:全局变量,函数定义所在模块的名字空间
-
builtins:内置模块的名字空间
不同变量的作用域不同就是由这个变量所在的命名空间决定的。
作用域范围:
-
全局范围:全局存活,全局有效
-
局部范围:临时存活,局部有效
查看作用域方法globals(), locals()
作用域查找顺序
level = "L0"
n = 11
def func():
level = "L1"
n = 22
print("func:", locals())
def outer():
n = 33
level = "L2"
print("outer:", locals())
def inner():
level = 'L3'
print("inner:", locals(), n)
inner()
outer()
func()
输出结果:

LEGB代表名字查找顺序:locals -> enclosing function -> globals -> __builtins__
-
locals: 是函数内的名称空间,包括局部变量和形参
-
enclosing:外部嵌套函数的名字空间
-
globals:全局变量,函数定义所在模块的名字空间
-
builtins:内置模块的名字空间