一、字典
字典同样是一个序列,不过字典的元素是由 key(键,可理解为关键字或名称)与 values (值)组成。就好像我们查字典,一个拼音对应着与之关联的一个或多个汉字,拼音就 key,而对应的 汉字就是 values。其中每一个元素都是“key:values”的形式,并且每个元素间 以逗号分隔。
说明:这种能够通过名称引用值的数据类型称做映射(Mapping),字典是 Python 中唯 一内建的映射类型。映射的概念好像比较难懂,以我个人的理解,映射就是名称集合与值集合的对应关系。名称集合中每个名称都是唯一的(即 Key 不可重复),并有唯一的值 (Key 与 Value 相对应);值集合中,值可以是唯一的也可以是重复的,但每个值也只能 有唯一的名称。
定义:{key1:value1,key2:value2}
特性:
-
key-value结构
-
key必须可hash、且必须为不可变数据类型、必须唯一
-
可存放任意多个值、可修改、可以不唯一
-
无序
字典的创建可以直接按格式创建,也可以使用 dict()方法进行创建。
-
dict(**kwarg):参数**kwarg 为可变关键字参数。
-
dict(mapping, **kwarg):参数 mapping 为映射函数。
-
dict(iterable, **kwarg):参数 iterable 为可迭代对象。
d = {} # 创建空字典
d = dict() # 创建空字典
d = {'name':['路飞','索隆','山治'],'age':'22','sex':'男'} # 创建字典
d = dict(name='路飞',age =22) # 通过可变参数创建字典
d = dict([('name','路飞'), ('age','22')]) # 通过可迭代对象(列表)创建字典
另外,还有一种字典的创建方式,通过 fromkeys(seq,value)方法进行创建,参数 seq 为包 含 key 的序列,参数 value 为 key 的默认值。
k = ['路飞','索隆'] # key 的列表 d1 = dict.fromkeys(k) # 仍 key 的列表创建字典 d2 = dict.fromkeys(k,'草帽') # 仍 key 的列表创建字典,并赋予默认值 print(d1) # 显示输出结果为:{'路飞': None, '索隆': None} print(d2) # 显示输出结果为:{'路飞': '草帽', '索隆': '草帽'}
查询:
首先,查询字典中的元素。我们可以使用 items()方法,通过 items()方法可以获取到字典中所有元素的迭代器
d = dict(name='路飞',age =22) # 通过可变参数创建字典 print(d.items()) # 显示输出结果为:dict_items([('name', '路飞'), ('age', 22)])
然后,查询字典中元素的键。 我们可以使用 keys()方法,通过 keys()方法可以获取到字典中所有元素键的迭代器。
d = dict(name='路飞',age =22) # 通过可变参数创建字典 print(d.keys()) # 显示输出结果为:dict_keys(['name', 'age'])
最后,查询字典中元素的值。查询元素值有多种方法:
第一种,通过键可以获取相对应的值:字典[键]
d = dict(name='路飞',age =22) # 通过可变参数创建字典 print(d['name']) # 显示输出结果为:路飞 print(d['age']) # 显示输出结果为:22
第二种,通过 get(k,default)方法查询,参数 k 为查询的键,参数 default 为未查询到结果 时的默认值。
d = dict(name='路飞',age =22) # 通过可变参数创建字典 print(d.get('name','海贼王')) # 显示输出结果为:路飞 print(d.get('sex','人妖')) # 显示输出结果为:人妖
第三种、通过 values()方法可以获取到字典中所有元素值的迭代器。
d = dict(name='路飞',age =22) # 通过可变参数创建字典 print(d.values()) # 显示输出结果为:dict_values(['路飞', 22])
添加元素:
添加单个元素:
首先,可以通过“字典[键]=值”的方式进行添加,如果字典中不存在相同的键则自动添加, 否则修改已存在的键所对应的值。
d = {"name":"路飞","age":20}
d["sex"] = "男" # 添新元素到字典
d["船员"] = "索隆", "山治" # 添加值为元组的新元素到字典
print(d) # 输出结果为:{'name': '路飞', 'age': 20, 'sex': '男', '船员': ('索隆', '山治')}
另外,还可以通过 setdefault(k,default)方法进行添加,参数 k 为指定的键,参数 default 为默认值。当字典中存在指定的键时,能够返回该键所对应的值;如果不存在指定的键时, 则会返回参数 default 中设置的值,同时,在字典中会添加新元素,新元素的键即为参数 k,值即为参数 default。
d = {"name":"路飞","age":20}
print(d.setdefault('name', '索隆')) # 字典中存在相应的键,则返回该键对应的值,显示输 出结果为:路飞
print(d.setdefault('sex', '男')) # 字典中不存在相应的键,则返回 default 参数的值,显 示输出结果为:男
print(d) # 当字典中不存在相应的键时,添加新元素,显示输出结果为:{'name': '路飞', 'age': 20, 'sex': '男'}
添加多个元素:通过 update(m,kwargs)方法进行添加,参数 m(mapping)为映射函数, kwargs 为可变参数。
d = {"name":"路飞","age":20}
d.update(sex="男",money=15) # 通过可变参数添加多个元素
print(d) #{'name': '路飞', 'age': 20, 'sex': '男', 'money': 15}
d = {"name":"路飞","age":20}
d.update((("sex","男"),("money",15))) # 通过元组添加多个元素
print(d) #{'name': '路飞', 'age': 20, 'sex': '男', 'money': 15}
d = {"name":"路飞","age":20}
d.update([("sex","男"),("money",15)]) # 通过列表添加多个元素
print(d) #{'name': '路飞', 'age': 20, 'sex': '男', 'money': 15}
d = {"name":"路飞","age":20}
d.update({"sex":"男","money":15}) # 通过列表添加多个元素
print(d) #{'name': '路飞', 'age': 20, 'sex': '男', 'money': 15}
d1 = {"name":"路飞","age":20}
d2 = {"sex":"男","money":15}
d1.update(d2) # 合并字典元素
print(d) #{'name': '路飞', 'age': 20, 'sex': '男', 'money': 15}
修改元素:
修改某个键对应的元素:字典[键]=新值
d = {"name":"路飞","age":20}
d["name"] = "索隆"
print(d) #{'name': '索隆', 'age': 20}
删除元素:
使用 del 指令可以通过键删除某个元素:del 字典[键]
d = {"name":"路飞","age":20}
del d["age"]
print(d) #{'name': '路飞'}
可以使用clear()删除字典中的所有项或元素
d = {"name":"路飞","age":20}
d.clear()
print(d) # {}
取出元素与元素值 :
使用 popitem()方法在字典中取出元素。
d = {"name":"路飞","age":20}
print(d.popitem()) #('age', 20)
print(d) #{'name': '路飞'}
以使用 pop(k,default)方法在字典中取出指定元素的值,参数 k 为指定元素 的键,参数 default 为未取到结果时的默认值。
d = {"name":"路飞","age":20}
print(d.pop("age")) #20
print(d.pop("sex","男")) #男
print(d) #{'name': '路飞'}
设置默认值:
d = {"name":"路飞","age":20}
print(d.setdefault('name', '索隆')) # 字典中存在相应的键,则返回该键对应的值,显示输 出结果为:路飞
print(d.setdefault('sex', '男')) # 字典中不存在相应的键,则返回 default 参数的值,显 示输出结果为:男
print(d) # 当字典中不存在相应的键时,添加新元素,显示输出结果为:{'name': '路飞', 'age': 20, 'sex': '男'}
其他:
字典也支持使用以下方法:
clear():清空字典
copy():复制字典:
len():获取字典元素数量
max():获取字典中最大的键
min():获取字典中最小的键
同时,字典也支持通过 in 和 not in 进行成员关系的判断
二、集合
集合通过 set(iterable)方法创建,参数 iterable 为可迭代对象。
s1 = set("好好学习天天向上") # 将字符串分解为单个字符,作为集合的元素创建集吅 s2 = set(('好好', '学习', '天天', '想上')) # 将元组分解为单个元素,作为集吅元素创建集合 s3 = set(['好好', '学习', '天天', '想上']) # 将列表分解为单个元素,作为集吅元素创建集合 print(s1) #{'好', '上', '学', '天', '习', '向'} print(s2) #{'想上', '好好', '天天', '学习'} print(s3) #{'想上', '好好', '天天', '学习'}
特性:
-
集合可以通过可迭代对象(字符串、元组、列表等)进行创建;
-
集合中的元素不可重复;
-
集合中的元素无序排列。
添加:
集合添加元素的方法有两种。
添加单个元素:使用 add(element)函数,参数 element 为集合允许添加的元素(例如数字、 字符串、元组等)。
添加多个元素:使用 update(iterable)函数,参数 iterable 为可迭代对象。
s1 = {1,2,3}
s2 = {'123'}
s3 = {'abc'}
s1.add(4)
s2.update(['4','5','6']) # 添加列表到集合,列表元素会被分解为单个元素后添加到集合
s3.update('de') # 添加字符串到集合,字符串会被分解为单个元素后添加到集合
print(s1) #{1, 2, 3, 4}
print(s2) #{'5', '4', '123', '6'}
print(s3) #{'abc', 'e', 'd'}
删除:
集合删除元素的方法有两种。
第一种:使用 remove(element)方法删除指定元素,参数 element 为需要删除的元素。
第二种:使用 discard(element)方法删除指定元素,参数 element 为需要删除的元素。
当集合中不存在这两个方法参数中填入的元素时,remove()方法会抛出异常,而 discard() 方法则没有仸何影响。
s1 = {1,2,3}
s2 = {'123'}
s3 = {'abc'}
s1.remove(1)
s1.discard(4)
print(s1) #{2, 3}
s1.remove(4)
print(s1) # Traceback (most recent call last):
File "E:/python/test/test1.py", line 367, in <module>
s1.remove(4)
KeyError: 4
取出元素:
使用pop(),由于集合是无序的,pop返回的结果不能确定,切当集合为空时调用pop会抛出异常。
s1 = {1,2,3}
print(s1) #{1, 2, 3}
print(s1.pop()) # 1
print(s1) #{2, 3}
清空:
s1 = {1,2,3}
s1.clear()
print(s1) # set()
交集/并集/补集/差集:
首先我们来看张图,理解交集、并集、补集、差集的概念。
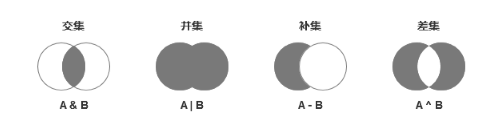
假设有集吅 A{1,2,3}和 B{3,4,5}。
交集:A 和 B 中相同部分的内容,{3}。
并集:A 和 B 去重后的全部内容,{1,2,3,4,5}。
补集:A 去除与 B 相交部分后的内容,{1,2}。
差集:A 和 B 不相交部分的全部内容,{1,2,4,5}。
创建集合
s1 = set('python') s2 = set('pycharm')
交集操作:获取两个集合中共有的元素
print(s1 & s2) #{'y', 'p', 'h'} print(s1.intersection(s2)) #{'y', 'p', 'h'}
并集操作:获取两个集合去除重复元素后的全部元素
print(s1 | s2) #{'p', 'a', 'o', 't', 'c', 'm', 'n', 'r', 'h', 'y'} print(s1.union(s2)) #{'p', 'a', 'o', 't', 'c', 'm', 'n', 'r', 'h', 'y'}
补集操作:获取当前集合去除与另一集合交集元素后的全部元素
print(s1 - s2) #{'o', 't', 'n'} print(s1.difference(s2)) #{'o', 't', 'n'} print(s2 - s1) #{'a', 'c', 'm', 'r'} print(s2.difference(s1)) #{'a', 'c', 'm', 'r'}
差集操作:获取两个集合去除交集元素后的全部元素
print(s1 ^ s2) #{'c', 'n', 'a', 't', 'r', 'm', 'o'} print(s1.symmetric_difference(s2)) #{'c', 'n', 'a', 't', 'r', 'm', 'o'}
difference_update(set)函数,能够将当前集合和指定集合进行补集运算,并将当前集合内容更新为运算结果
s1 = set('1234') s2 = set('456') s1.difference(s2) # 该操作对 s1 内容无影响 print(s1) # s1 无变化,显示输出结果为:{'3', '4', '2', '1'} s1.difference_update(s2) # 更新集合 s1 的内容为 s1-s2 后的结果 print(s1) #{'3', '1', '2'}
intersection_update(set) 函数,能够将当前集合和指定集合进行交集运算,并将当前集合内容更新为运算结果
s1 = set('1234') s2 = set('456') s1.intersection(s2) # 该操作对 s1 内容无影响 print(s1) # s1 无变化,显示输出结果为:{'2', '1', '4', '3'} s1.intersection_update(s2) # 更新集合 s1 的内容为 s1 & s2 后的结果 print(s1) #{'4'}
symmetric_difference_update(set) 函数,能够将当前集合和指定集合进行差集运算,并将当前集合内容更新为运算结果
s1 = set('1234') s2 = set('456') s1.symmetric_difference(s2) # 该操作对 s1 内容无影响 print(s1) # s1 无变化,显示输出结果为:{'2', '1', '4', '3'} s1.symmetric_difference_update(s2) # 更新集合 s1 的内容为 s1 ^ s2 后的结果 print(s1) #{'2', '5', '3', '1', '6'}
另外,我们还可以使用“not in”,判断操作符前方的值是否未被后方的序列包含(非成员关系)。
在集合中,我们同样可以使用这两个操作符。
另外,我们还可以通过以下方法,判断一个集合是否另外一个集合的子集或超集以及没有 交集。
isdisjoint(set):可以判断集合是否与指定集合不存在交集,参数 set 为集合;如果成立返回结果为 True,否则为 False。
issubset(set):可以判断集合是否指定集合的子集,参数 set 为集合;如果成立返回结果为 True,否则为 False。
issuperset(set):可以判断集合是否指定集合的超集,参数 set 为集合;如果成立返回结果为 True,否则为 False。
s1 = set('好好学习') s2 = set('天天想上') s3 = set('好好学习天天想上') print('好' in s1) # True print('好' not in s2) # True print(s1.isdisjoint(s2)) # True print(s1.issubset(s3)) # True print(s3.issuperset(s1)) #True
复制集合
a = set('红酥手黄藤酒') # 创建集合存入变量 a b = a # 创建变量 b 引用变量 a 的集合 c = a.copy() # 创建变量 c 复制变量 a 的值 print(a) #{'手', '酒', '红', '黄', '酥', '藤'} print(b) #{'手', '酒', '红', '黄', '酥', '藤'} print(c) #{'手', '藤', '酥', '酒', '红', '黄'} a.remove('红') # 删除变量 a 中集合的一个元素 print(a) #变量 a 发生改变,{'手', '黄', '酒', '酥', '藤'} print(b) # 变量 b 因为引用变量 a,同样发生改变,{'酥', '藤', '手', '黄', '酒'} print(c) #变量 c 没有改变,{'酥', '藤', '酒', '手', '黄', '红'}
代码中,b = a 实际上是将 b 指向了 a 的内容,所以当 a 的内容发生变化时,b 同步发生了变化。
而 c = a.copy()则是将 a 的内容真正进行了复制,不再受 a 的变化影响。
其他
集合也支持 len()方法进行元素数量的获取,也支持 max()方法和 min 方法获取集合中的最大元素与最小元素