前言
终于进入死锁系列,前面也提到过我一直对隔离级别和死锁以及如何避免死锁等问题模棱两可,所以才鼓起了重新学习SQL Server系列的勇气,本节我们来讲讲SQL Server中的死锁,看到许多文章都只简述不能这样做,这样做会导致死锁,但是未理解其基本原理,下次遇到类似情况依然会犯错,所以基于了解死锁原理并且得到治疗死锁良方,博主不惜花费多天时间来学习死锁最终总结出本文,若有叙述不当之处请在评论中指出。
死锁定义
死锁是两个或多个进程互相阻塞的情况。两个进程死锁的例子是,进程A阻塞进程B且进程B阻塞进程B。涉及多个进程死锁的例子是,进程A阻塞进程B,进程B阻塞进程C且进程C阻塞进程A。在任何一种情况下,SQL Server检测到死锁,都会通过终止其中的一个事务尽心干预。如果SQL Server不干预,涉及的进程永远陷于死锁状态。
除外另外指定,SQL Server选择终止工作最少的事务,因为它便于回滚该事务的工作。但是,SQL Server允许用户设置一个叫做DEADLOCK_PRIORITY的会话选项,可以是范围在-10~10之间的21个值中的任意值,死锁优先级最低的进程将被作为牺牲对象,而不管其做了多少工作。我们可以举一个生活中常见和死锁类似的例子,当在车道上行驶时,快到十字路口的红灯时,此时所有的小车都已经就绪等待红灯,当变绿灯时,此时有驾驶员发现走错了车道,于是开始变换车道,但是别的车道都拥堵在一块根本插不进去,驾驶员只有等待有空隙时再插进去,同时驾驶员车道上后面的小车又在等待驾驶员开到别的车道。这种情况虽然不恰当,但是在一定程度上很好的表现了死锁的情况,所以在开车时尽量别吵吵,否则谁都走不了,keep silence。

下面我们来演示常见的一种死锁情况,然后我们再来讨论如何减少系统中死锁的发生。
读写死锁
在SQL Server数据库中我们打开两个连接并确保都已连接到数据库,在会话一中我们试图去更新Production.Products表中产品2的行。
SET TRAN ISOLATION LEVEL READ COMMITTED BEGIN TRAN; UPDATE Production.Products SET unitprice += 1.00 WHERE productid = 2;
在会话2中再来打开一个事务,更新Sales.OrderDetails表中产品2的行,并使事务保持打开状态
SET TRAN ISOLATION LEVEL READ COMMITTED BEGIN TRAN UPDATE Sales.OrderDetails SET unitprice += 1.00 WHERE productid = 2;
此时上述会话一和会话二都用其会话的排他锁且都能更新成功,下面我们再来在会话一中进行查询Sale.OrderDetails表中产品2的行并提交事务。
SET TRAN ISOLATION LEVEL READ COMMITTED BEGIN TRAN; SELECT orderid, productid, unitprice FROM Sales.OrderDetails WHERE productid = 2; COMMIT TRAN;
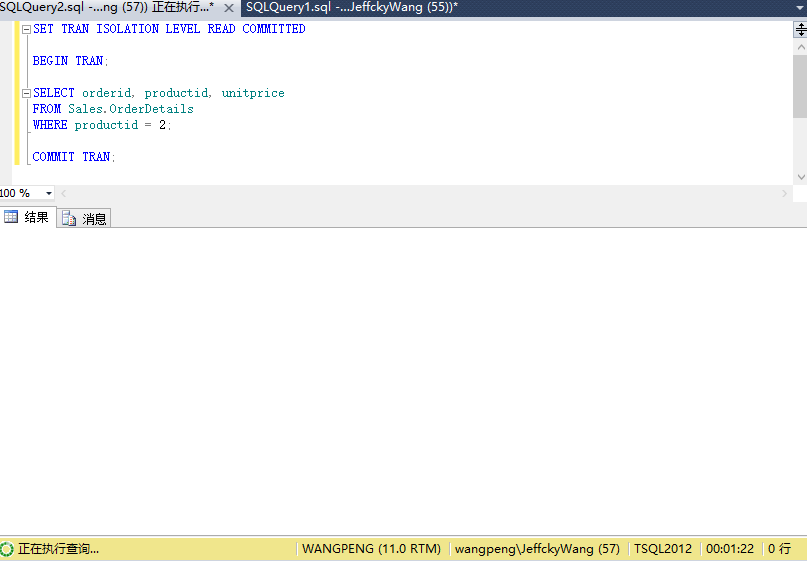
因为需要查询Sales.OrderDetails表中产品2的行,但是在之前我们更新产品2的行同时并未提交事务,因为查询的共享锁和排它锁不兼容,最终导致查询会阻塞,接下来我们在会话二中再来查询Producution.Products表中产品为2的行。
SET TRAN ISOLATION LEVEL READ COMMITTED BEGIN TRAN SELECT productid, unitprice FROM Production.Products WHERE productid = 2; COMMIT TRAN;
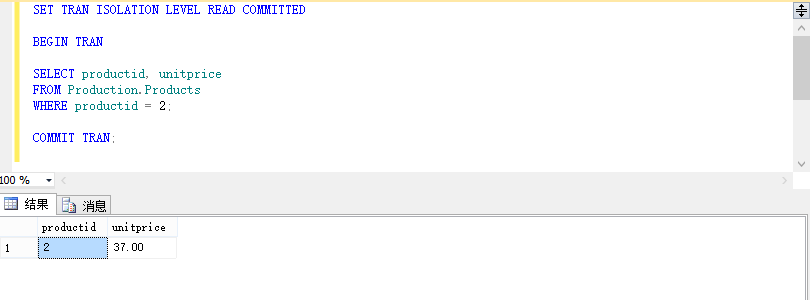
此时我们看到在会话二中能成功查询到Production.Products表中产品2的行,同时我们再来看看会话一中查询情况。
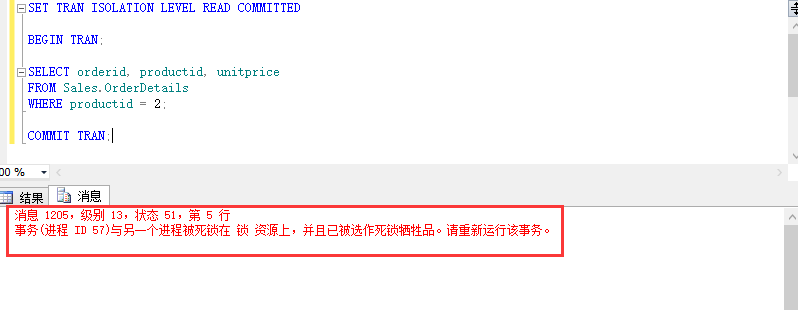
上述死锁算是最常见的死锁情况,在会话一(A进程)中去更新Production.Products表中产品2的行,在会话二(B进程)去更新Sales.OrderDetails表中产品2的行,但是接下来在会话一中去查询Sales.OrderDetails表中产品2的行,此时B进程要等待A进程中未提交的事务进行提交,所以导致A进程将阻塞B进程,接着在会话二中去查询Production.Products表中产品2的行,此时A进程要等待B进程中未提交的事务进行提交,所以导致B进程阻塞A进程,最终结果将是死锁。所以到了这里我们能够很清楚地知道在两个或多个事务中注意事务之间不能交叉进行。要是面试时忘记了肿么办,告诉你一个简单的方法,当军训或者上体育课正步走时只有1、2、1,没有1、2、2就行。
写写死锁
想必大家大部分只知道上述情况的死锁,上述情况是什么情况,我们抽象一下则是不同表之间导致的死锁,下面我们来看看同一表中如何产生死锁,这种情况大家更加需要注意了。我们首先创建死锁测试表并对表中列Id,Name创建唯一聚集索引,如下:
USE tempdb GO CREATE TABLE DeadlocksExample (Id INT, Name CHAR(20), Company CHAR(50)); GO CREATE UNIQUE CLUSTERED INDEX deadlock_idx ON DeadlocksExample (Id, Name) GO
接下来在会话一中插入一条测试数据开启事务但是并未提交,如下:
BEGIN TRAN INSERT INTO dbo.DeadlocksExample VALUES (1, 'Jeffcky', 'KS')
接下来再来打开一个会话二插入一条数据开启事务但是并未提交,如下:
BEGIN TRAN INSERT INTO DeadlocksExample VALUES (10, 'KS', 'Jeffcky')
再来在会话一中插入一条数据。
INSERT INTO DeadlocksExample VALUES (10, 'KS', 'Jeffcky')
此时此次插入将会阻塞,如下:
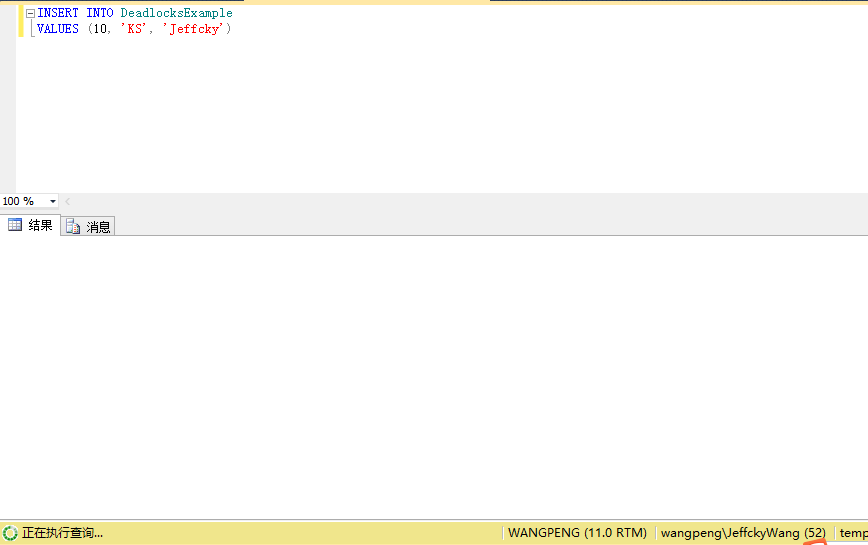
最后再来在会话二中插入一条数据
INSERT INTO DeadlocksExample VALUES (1, 'Jeffcky', 'KS')
此时此次插入能进行但是会显示死锁信息,如下:

想必大多数情况下看到的是通过不同表更新行产生的死锁,在这里我们演示了在相同表通过插入行也会导致死锁,死锁真是无处不在。上述发生死锁的主要原因在于第二次在会话一中去插入相同数据行时此时由于我们创建了Id和Name的唯一聚集索引所以SQL Server内部会尝试去读取行导致插入阻塞,在会话一中去插入行同理,最终造成彼此等待而死锁。为了更深入死锁知识,我们来看看如何从底层来探测死锁,上述发生死锁后,我们通过运行如下语句来查询死锁图:
SELECT XEvent.query('(event/data/value/deadlock)[1]') AS DeadlockGraph FROM ( SELECT XEvent.query('.') AS XEvent FROM ( SELECT CAST(target_data AS XML) AS TargetData FROM sys.dm_xe_session_targets st JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address WHERE s.name = 'system_health' AND st.target_name = 'ring_buffer' ) AS Data CROSS APPLY TargetData.nodes ('RingBufferTarget/event[@name="xml_deadlock_report"]') AS XEventData ( XEvent ) ) AS src;
此时你将发现会出现如下xml的数据:

我们点看死锁图来分析分析:
<deadlock>
<victim-list>
<victimProcess id="process17602d868" />
</victim-list>
<process-list>
<process id="process17602d868" taskpriority="0" logused="300" waitresource="KEY: 2:2089670228247904256 (4e0d37de3c51)" waittime="4222" ownerId="49122" transactionname="user_transaction" lasttranstarted="2017-03-04T21:56:15.447" XDES="0x16db8c3a8" lockMode="X" schedulerid="4" kpid="8296" status="suspended" spid="59" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2017-03-04T21:56:47.080" lastbatchcompleted="2017-03-04T21:56:15.450" lastattention="1900-01-01T00:00:00.450" clientapp="Microsoft SQL Server Management Studio - 查询" hostname="WANGPENG" hostpid="1640" loginname="wangpengJeffckyWang" isolationlevel="read committed (2)" xactid="49122" currentdb="2" lockTimeout="4294967295" clientoption1="671090784" clientoption2="390200">
<executionStack>
<frame procname="adhoc" line="1" stmtstart="84" sqlhandle="0x02000000ea13d9115e8a4d429bc3d549e9053a3a784358020000000000000000000000000000000000000000">
INSERT INTO [DeadlocksExample] values(@1,@2,@3) </frame>
<frame procname="adhoc" line="1" sqlhandle="0x020000009882c20809f279b6638fea1ef34b7986efb6b60a0000000000000000000000000000000000000000">
INSERT INTO DeadlocksExample
VALUES (1, 'Jeffcky', 'KS') </frame>
</executionStack>
<inputbuf>
INSERT INTO DeadlocksExample
VALUES (1, 'Jeffcky', 'KS') </inputbuf>
</process>
<process id="process17602dc38" taskpriority="0" logused="300" waitresource="KEY: 2:2089670228247904256 (381c351990d5)" waittime="20467" ownerId="49022" transactionname="user_transaction" lasttranstarted="2017-03-04T21:56:06.070" XDES="0x16db8d6a8" lockMode="X" schedulerid="4" kpid="2684" status="suspended" spid="54" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2017-03-04T21:56:30.837" lastbatchcompleted="2017-03-04T21:56:06.070" lastattention="1900-01-01T00:00:00.070" clientapp="Microsoft SQL Server Management Studio - 查询" hostname="WANGPENG" hostpid="1640" loginname="wangpengJeffckyWang" isolationlevel="read committed (2)" xactid="49022" currentdb="2" lockTimeout="4294967295" clientoption1="671090784" clientoption2="390200">
<executionStack>
<frame procname="adhoc" line="1" stmtstart="84" sqlhandle="0x02000000ea13d9115e8a4d429bc3d549e9053a3a784358020000000000000000000000000000000000000000">
INSERT INTO [DeadlocksExample] values(@1,@2,@3) </frame>
<frame procname="adhoc" line="1" sqlhandle="0x02000000579d610429b0df7caee58044a9e5b493ea0d8e450000000000000000000000000000000000000000">
INSERT INTO DeadlocksExample
VALUES (10, 'KS', 'Jeffcky') </frame>
</executionStack>
<inputbuf>
INSERT INTO DeadlocksExample
VALUES (10, 'KS', 'Jeffcky') </inputbuf>
</process>
</process-list>
<resource-list>
<keylock hobtid="2089670228247904256" dbid="2" objectname="tempdb.dbo.DeadlocksExample" indexname="1" id="lock172b46e80" mode="X" associatedObjectId="2089670228247904256">
<owner-list>
<owner id="process17602dc38" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process17602d868" mode="X" requestType="wait" />
</waiter-list>
</keylock>
<keylock hobtid="2089670228247904256" dbid="2" objectname="tempdb.dbo.DeadlocksExample" indexname="1" id="lock172b48b00" mode="X" associatedObjectId="2089670228247904256">
<owner-list>
<owner id="process17602d868" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process17602dc38" mode="X" requestType="wait" />
</waiter-list>
</keylock>
</resource-list>
</deadlock>
东西貌似比较多哈,别着急我也是菜鸟,我们慢慢看,我们将其折叠,重点是分为如下两块:

死锁最重要的两个节点则是如上process和resource,我们再来一块一块分析,首先看process-list

如上我们能够很清晰的看到关于死锁的所有细节,我们查询的SQL语句、隔离级别以及事务开始和结束的时间等更多详细介绍,我们再来看看resource-list

而resource-list则列举出了关于锁的所有资源,如上列举出了每个进程获取到的锁以及请求的锁。我们从上看出通过 objectname 来标识数据库关于死锁的表,我们可以通过 associatedObjectId 关联对象Id来得到表明和索引,运行如下查询:
SELECT OBJECT_NAME(p.object_id) AS TableName , i.name AS IndexName FROM sys.partitions AS p INNER JOIN sys.indexes AS i ON p.object_id = i.object_id AND p.index_id = i.index_id WHERE partition_id = 2089670228247904256

上述resource-list节点下有两个重要的子节点:owner-list和waiter-list,owner-list从字面意思理解则是拥有锁的进程,同理waiter-list则是请求锁并且等待这个拥有锁的进程释放的进程。我们能够看到上述涉及到的都是排它锁。resource-list中的过程大概如下:
(1)进程dc38获取在表 DeadlocksExample 上键中的排它锁。
(2)进程d868获取在表 DeadlocksExample 上键中的排它锁。
(3)进程d868请求在表 DeadlocksExample 上键中的排它锁。
(4)进程dc38请求在表 DeadlocksExample 上键中的排它锁。
所以为何一般不推荐使用联合主键,若使用联合主键则该情况如上述所述,此时两个列默认创建则是唯一聚集索引,当有并发情况产生时会就有可能导致在同一表中插入相同的值此时将导致死锁情况发生,想必大部分使用联合主键的情景应该是在关联表中,将两个Id标识为联合主键,此时我们应该重新设置一个主键无论是INT或者GUID也好都比联合主键要强很多。
实战拓展
上述我们大概了解了下死锁图以及相关节点解释,接下来我们来演示几种常见的死锁并逐步分析。我们来看看。
避免逻辑死锁
我们创建如下测试表并默认插入数据:
CREATE TABLE Table1 ( Column1 INT, Column2 INT ) GO INSERT INTO Table1 VALUES (1, 1), (2, 2),(3, 3),(4, 4) GO CREATE TABLE Table2 ( Column1 INT, Column2 INT ) GO INSERT INTO Table2 VALUES (1, 1), (2, 2),(3, 3),(4, 4) GO
此时我们进行数据更新对Column2,如下:
UPDATE Table1 SET Column1 = 3 WHERE Column2 = 1

此时由于我们对列Column2没有创建索引,所以会造成SQL Server引擎会进行全表扫描去堆栈中找到我们需要更新的数据,同时呢SQL Server会对该行更新的数据获取一个排它锁,当我们进行如下查询时
SELECT Column1 FROM Table1 WHERE Column2 = 4
此时将获取共享锁,即使上述更新和此查询语句在不同的会话中都不会造成阻塞,虽然排它锁和共享锁不兼容,因为上述更新数据的内部事务已经提交,所以排它锁已经释放。下面我们来看看死锁情况,我们打开两个会话并确保会话处于连接状态。
在会话一中我们对表一上的Column1列进行更新通过筛选条件Column2同时开启事务并未提交,如下:
BEGIN TRANSACTION UPDATE Table1 SET Column1 = 3 WHERE Column2 = 1
会话二同理
BEGIN TRANSACTION UPDATE Table2 SET Column1 = 5 WHERE Column2 = 2
同时去更新两个会话中的数据。接下来再在会话一中更新表二中的数据行,如下:
BEGIN TRANSACTION SELECT Column1 FROM Table2 WHERE Column2 = 3 ROLLBACK TRANSACTION
在读写死锁中我们已经演示此时查询会造成堵塞,就不再贴图片了。
同理在会话一中更新表一中的数据行。
BEGIN TRANSACTION SELECT Column1 FROM Table1 WHERE Column2 = 4 ROLLBACK TRANSACTION GO
此时运行会话二中的语句,将得到如下死锁信息,当然二者必然有一个死锁牺牲品,至于是哪个会话,那就看SQL Server内部处理机制。

上述关于表一和表二死锁的情况,大概如下图所示
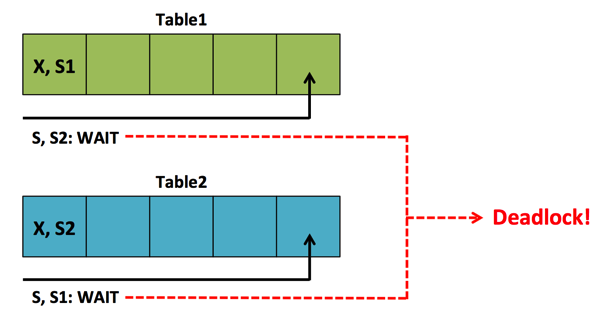
上述由于没有建立索引导致全表扫描所以对于每行记录都会获取一个共享锁,但是呢,更新数据进程又为提交事务最终会导致死锁,其实我们可以通过建立索引来找到匹配的行同时会绕过在叶子节点上被锁定的行,那么应该创建什么索引呢,对筛选条件创建过滤索引?显然是不行的,因为查询出的列还是到基表中去全表扫描,所以我们常见覆盖索引,如下:
CREATE NONCLUSTERED INDEX idx_Column2 ON Table1(Column2) INCLUDE(column1)
CREATE NONCLUSTERED INDEX idx_Column2 ON Table2(Column2) INCLUDE(column1)
当我们再次重新进行如上动作时,你会发现在会话一中进行查询时此时将不会导致阻塞,直接能查询出数据,如下:

所以通过上述表述我们知道好的索引设计能够减少逻辑冲突上的死锁。
避免范围扫描和SERIALIZABLE死锁
比如我们要进行如下查询。
SELECT CustomerIDFROM Customers WHERE CustomerName = @p1
一旦有并发则有可能造成幻影读取即刚开始数据为空行,但是第二次读取时则存在数据,所以此时我们设置更高的隔离级别,如下:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
通过设置该隔离级别即使刚开始数据为空行,它能保证再次读取时返回的数据一定为空行,通过锁住 WHERE CustomerName = @p1 并且它会锁住值等于@p1的所有记录,我们经常有这样的需求,当数据存在时则更新,不存在时则插入,如果你没有想到并发情况的发生,估计到时投诉将落在你身上,所以为了解决两次读取一致的情况我们设置最高隔离级别,如下:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; BEGIN TRANSACTION IF EXISTS ( SELECT 1 FROM [dbo].[Customers] WITH ( ROWLOCK ) WHERE CustomerName = @p1 ) UPDATE dbo.Customers SET LatestOrderStatus = NULL , OrderLimit = 0 WHERE CustomerName = @p1; ELSE INSERT INTO dbo.Customers ( CustomerName , RegionID , OrderLimit , LatestOrderStatus ) VALUES ( @p1 , 0 , 0 , NULL ); COMMIT TRANSACTION
上述假设我们对CustomerName建立了唯一索引并加了行锁来锁住单行数据,看起来so good,实际上有没有问题呢。如果当CustomerName = 'Jeffcky'在该行上面的CustomerName = 'Jeffcky1',在其下方的CustomerName = 'Jeffcky2',此时通过设置最高隔离级别将锁住这三行来阻止任何数据的插入,我们可以将其叫做范围共享锁,如果在不同会话中在该范围内插入不同行,此时极有可能造成死锁,你以为设置最高隔离级别就万事大吉了吗。那么该如何解决这个麻烦呢,我们可以通过Merge来避免该死锁,因为Merge操作为单原子操作,我们不在需要最高隔离级别,但是貌似有潜在的bug发生未验证过,同时该Merge我也未用过。
这个问题是在博问中看到dudu老大提出插入重复数据而想到(博问地址:https://q.cnblogs.com/q/90745/),dudu老大所给语句为如下SQL语句:
IF NOT EXISTS(SELECT 1 FROM [Relations] WHERE [UserId]=@UserId AND [RelativeUserId]=@RelativeUserId AND IsActive=1) BEGIN BEGIN TRANSACTION INSERT INTO [Relations]([UserId], [RelativeUserId]) VALUES (@UserId,@RelativeUserId) UPDATE [Users] SET FollowingCount=FollowingCount+1 WHERE UserID=@UserId UPDATE [Users] SET FollowerCount=FollowerCount+1 WHERE UserID=@RelativeUserId COMMIT TRANSACTION END
当时我所给出的答案为如下:
INERT INTO.....SELECT ...FROM WHERE NOT EXSITS(SELECT 1 FROM...)
对应上述情况我们将上述隔离级别去掉利用两个语句来操作,如下:
UPDATE dbo.Customers SET LatestOrderStatus = NULL , OrderLimit = 0 WHERE CustomerName = @p1; INSERT INTO dbo.Customers ( CustomerName , RegionID , OrderLimit , LatestOrderStatus ) SELECT @p1~ , 0 , 0 , NULL WHERE NOT EXISTS ( SELECT 1 FROM dbo.Customers AS c WHERE CustomerName = @p1 )
此时没有事务,上述虽然看起来很好不会引起死锁但是对于插入操作会导致阻塞。我看到上述dudu老大提出的问题有如下答案:
BEGIN TRANSACTION IF NOT EXISTS(SELECT 1 FROM [Relations] WITH(XLOCK,ROWLOCK) WHERE [UserId]=@UserId AND [RelativeUserId]=@RelativeUserId AND IsActive=1) BEGIN INSERT INTO [Relations]([UserId], [RelativeUserId]) VALUES (@UserId,@RelativeUserId) UPDATE [Users] SET FollowingCount=FollowingCount+1 WHERE UserID=@UserId UPDATE [Users] SET FollowerCount=FollowerCount+1 WHERE UserID=@RelativeUserId END COMMIT TRANSACTION
经查资料显示对于XLOCK,SQL Server优化引擎极有可能忽略XLOCK提示,而导致无法解决问题,具体未经过验证。在这里我觉得应该使用UPDLOCK更新锁。通过UPDLOCK与其他更新锁不兼容,通过UPDLOCK来序列化整个过程,当运行第二个进程时,由于第一个进程占用锁导致阻塞,所以直到第一个进程完成整个过程第二个进程都将处于阻塞状态,所以对于dudu老大提出的问题是否最终改造成如下操作呢。
BEGIN TRANSACTION
IF NOT EXISTS(SELECT 1 FROM [Relations] WITH (ROWLOCK, UPDLOCK) WHERE [UserId]=@UserId AND [RelativeUserId]=@RelativeUserId AND IsActive=1)
UPDATE [Users] SET FollowingCount=FollowingCount+1 WHERE UserID=@UserId;
UPDATE [Users] SET FollowerCount=FollowerCount+1 WHERE UserID=@RelativeUserId;
ELSE
INSERT INTO [Relations]
( [UserId],
[RelativeUserId]
)
VALUES ( @UserId,
@RelativeUserId
);
COMMIT TRANSACTION
总结
本节我们比较详细讲解了SQL Server中的死锁以及避免死锁的简单介绍,对于如何避免死锁我们可以从以下来看。
(1)锁保持的时间越长,增加了死锁的可能性,尽量缩短事务的时间即尽量使事务简短。
(2)事务不要交叉进行,按照顺序执行。
(3)对于有些逻辑可能不可避免需要交叉进行事务,此时我们可能通过良好的索引设计来规避死锁发生。
(4)我们也可以通过try..catch,捕获事务出错并retry。
(5)最后则是通过设置隔离级别来减少死锁频率发生。
好了本文到此结束,内容貌似有点冗长,没办法,太多需要学习,对于SQL Server基础系列可能还剩下最后一节内容,那就是各种锁的探讨,我们下节再会,see u。