Blending Models(融合模型)
Blending:指的是当已有丰富多样的 (g_t) 时,进行聚合(Aggregate)。(aggregate after getting diverse (g_t))。
常用的三种 Blending 模型如下:

uniform : 是认为不同的 (g_t) 之间可能可以相互修正,从而提高稳定性(stability)。而 non-uniform/conditional 则在原来的 (g_t) 的基础之上又进行了一层学习,所以能力更强,当然也要注意其带来的模型复杂度(complexity)。
Aggregation-Learning Models(聚合学习模型)
Aggregation-Learning:指的是在聚合的过程中同时获得丰富多样的 (g_t)(aggregate as well as getting diverse (g_t))
常见的 Learning 聚合模型如下:
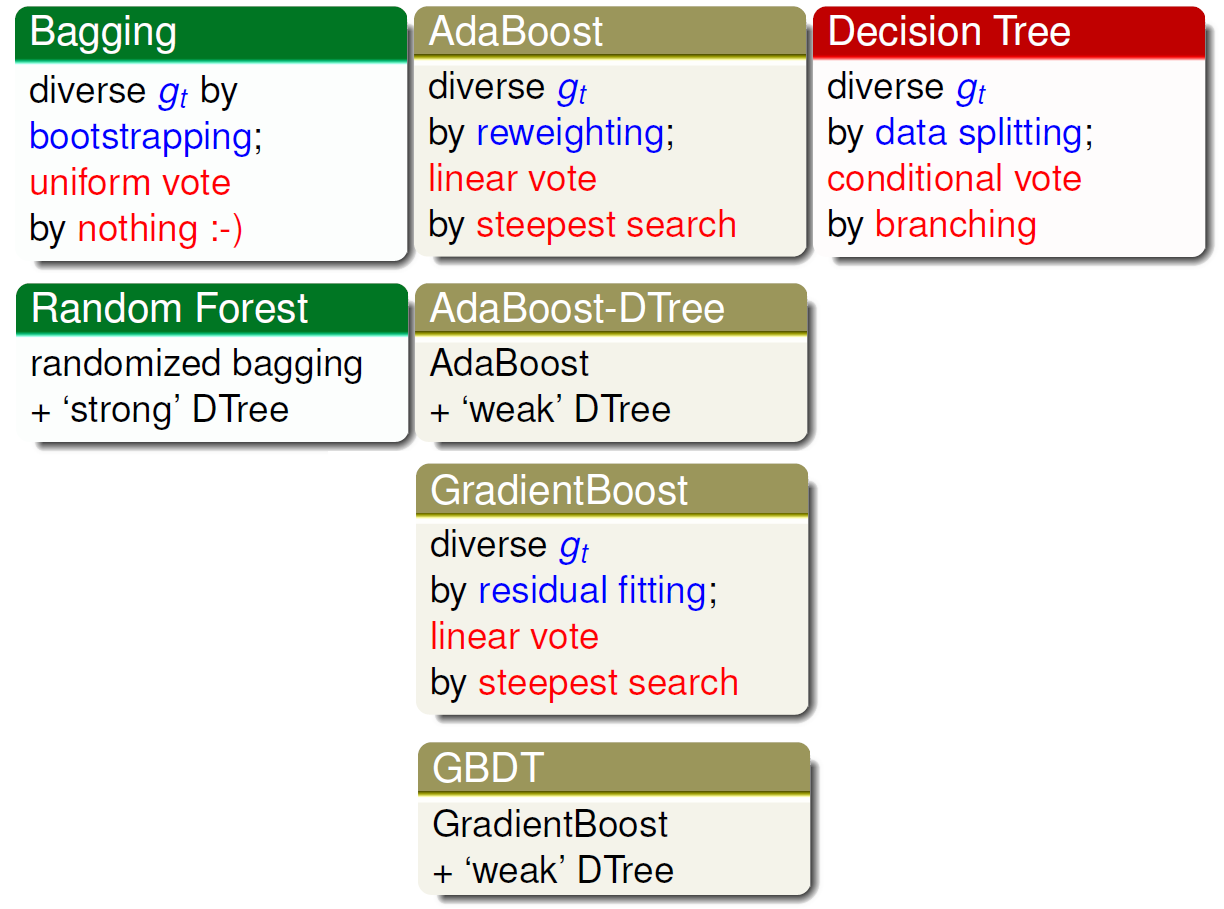
其中第一行和第三行均属于单纯的 Aggregation-Learning Models,而第二行和第四行均属于 Aggregation-Aggregation Models,什么意思呢,在Aggregation 的基础上和 Decision Tree 结合,即在训练 Learning Aggregation Models 时使用聚合模型(Decision Tree)作为基模型。
Specialty of Aggregation Models(聚合模型的特殊性)
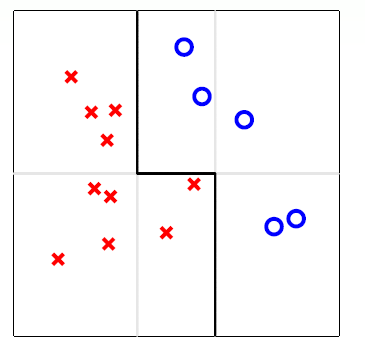
如上图所示,在一些情况下,聚合是为了解决欠拟合问题,类似于特征转换(feature transform)。
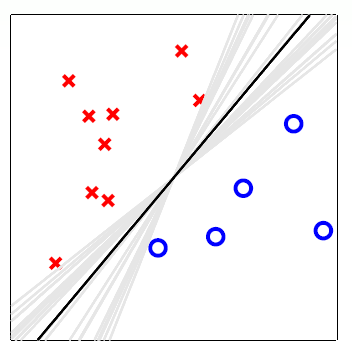
如上图所示,在一些情况下,聚合是为了解决过拟合问题,类似于正则化(regularization)。
虽然聚合的目标都不一样,但是合理的聚合(proper aggregation)可以得到更好的性能(better performance),在一些文献中将聚合称为集成(ensemble)。