1、查看集群健康状态
[root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/health?v epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 1552784149 00:55:49 ELK-chaofeng green 3 3 44 22 0 0 0 0 - 100.0%
2、查看集群节点
[root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/nodes?v ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 172.16.0.52 13 22 0 0.00 0.06 0.12 mdi - elk02 172.16.0.51 13 97 0 0.00 0.01 0.05 mdi * elk01 172.16.0.53 12 97 0 0.00 0.01 0.05 mdi - elk03
3、查看master节点状态
[root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/master?v id host ip node 8Z8Oi4ipRCmaAjKESa2-FA 172.16.0.51 172.16.0.51 elk01
4、查看ES集群安装了什么插件
[root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/plugins?v name component version
没有任何插件此时
5、查看集群索引
[root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open logstash-apacheerrorlogs kBCaAVGcQfahh730CXsFyw 5 1 111 0 264kb 132kb green open .newkibana_1 aFFVpEqeTbSxQyJ48Djwyw 1 1 9 0 113.8kb 56.9kb green open .kibana_1 nmZWm-d5TGy6ZqMgvslPEQ 1 1 3 0 24kb 12kb green open logstash-apachelogs VIzul30TTpWltpIrgrPwEA 5 1 77 0 765.9kb 382.9kb green open sys 58eN-9CRRqGt8i-B5Ar-qQ 5 1 0 0 2.5kb 1.2kb green open logstash-apachehahalogs uSmB7bPmR5WbqIscyduvIA 5 1 5767 0 9.2mb 4.6mb
6、自定义显示节点状态。
先获取帮助
[root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/nodes?help id | id,nodeId | unique node id pid | p | process id ip | i | ip address port | po | bound transport port http_address | http | bound http address version | v | es version
有非常多,想获取哪个就可以获取哪个。比如如下所示:
[root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/nodes?h=name,ip,port,jdk elk02 172.16.0.52 9300 1.8.0_201 elk01 172.16.0.51 9300 1.8.0_201 elk03 172.16.0.53 9300 1.8.0_201
7、显示当前节点的ES信息
[root@ELK-chaofeng01 ~]#curl http://172.16.0.51:9200 { "name" : "elk01", "cluster_name" : "ELK-chaofeng", "cluster_uuid" : "5VIF1_SdQdGbRekuR9q4-A", "version" : { "number" : "6.5.2", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "9434bed", "build_date" : "2018-11-29T23:58:20.891072Z", "build_snapshot" : false, "lucene_version" : "7.5.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }
看到“you knoe , foe search ” 这表示当前ES安装成功。
8、安装插件,最著名的插件是HEAD插件。
查看我之前的博客,有讲如何安装HEAD插件的:https://www.cnblogs.com/FengGeBlog/p/10471710.html
9、添加索引和内容
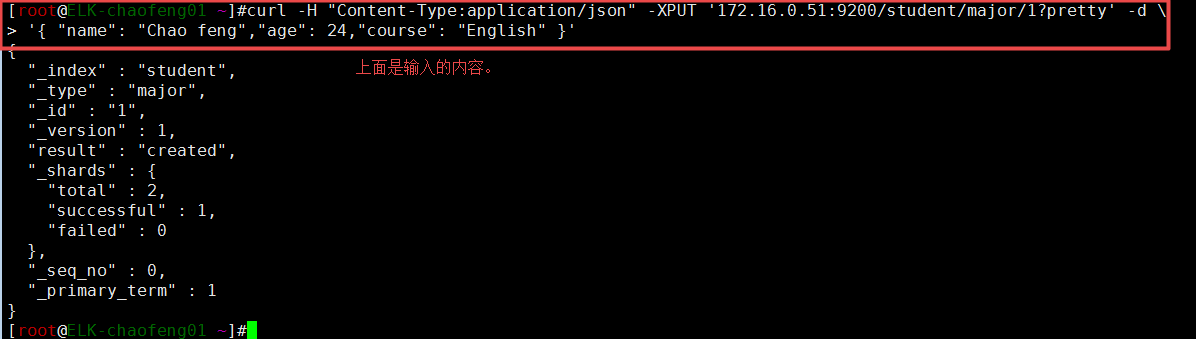
第一行的“-H Content-Type:application/json” 要带上去,这是6.x与5.x下的区别,否则不能创建索引成功。
10、查找我们刚刚创建的索引
[root@ELK-chaofeng01 ~]#curl -XGET '172.16.0.51:9200/student/_search?pretty' { "took" : 184, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 1.0, "hits" : [ { "_index" : "student", "_type" : "major", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "Chao feng", "age" : 24, "course" : "English" } } ] } }
在索引的后面添加“_search”来查看指定索引的内容,默认是列出当前所有下的所有内容
11、查找指定索引下的指定内容,比如搜索“English”
[root@ELK-chaofeng01 ~]#curl -XGET '172.16.0.51:9200/student/_search?q="English"&pretty' { "took" : 12, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 0.2876821, "hits" : [ { "_index" : "student", "_type" : "major", "_id" : "1", "_score" : 0.2876821, "_source" : { "name" : "Chao feng", "age" : 24, "course" : "English" } } ] } }
ES内部会自动进行大小写转换,默认是不区分大小写的。
11.1)HEAD插件上传

12)对某个索引的某个类型做搜索
[root@ELK-chaofeng01 ~]#curl -XGET '172.16.0.51:9200/student/major/_search?q="English"&pretty' { "took" : 19, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 0.2876821, "hits" : [ { "_index" : "student", "_type" : "major", "_id" : "1", "_score" : 0.2876821, "_source" : { "name" : "Chao feng", "age" : 24, "course" : "English" } } ] } }
13)案例:对某个索引查看统计的个数
我想统计一下es集群中的某个索引中的“notice”有多少个,我之前采集日志向ES集群发送过去了,当时的日志中的“notice”行数是:

此时我在ES集群中使用搜索技术查看
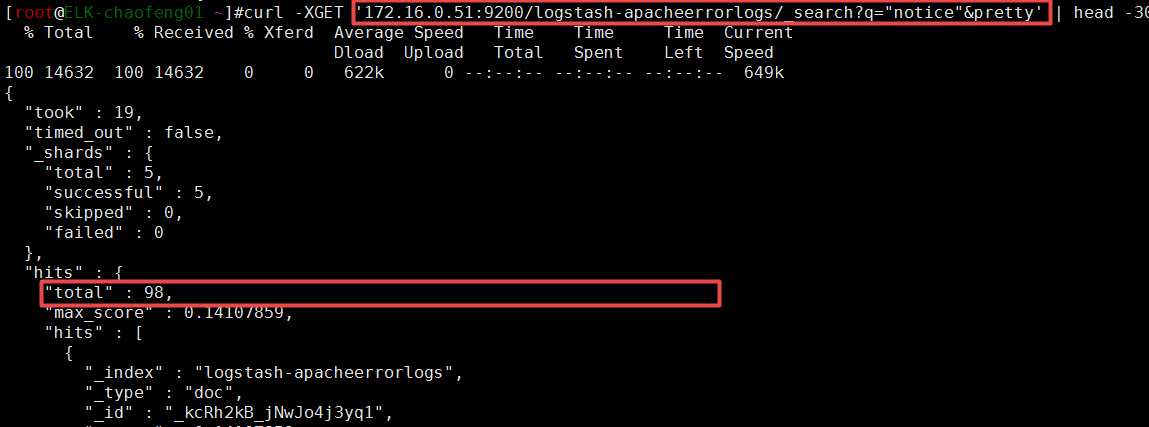
完全正确,搜索的非常好。上面的默认查找方式是“_all”。
你也可以使用这种技术来切割,“loglevel:notice”,在前面加上冒号,表示对特定的类型进行匹配
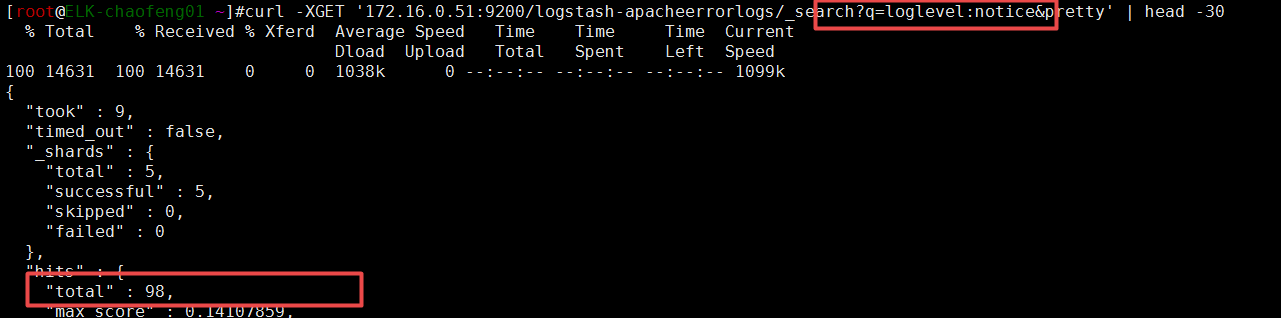
要学会使用“q=Type:WORD”的方式来查询。
14)做简单查询

15)做复杂处理,注意写的格式;复杂处理的标志就是“query_string”。

注意加引号。
分片定义:
集群(cluster): 由一个或多个节点组成, 并通过集群名称与其他集群进行区分 节点(node): 单个ElasticSearch实例. 通常一个节点运行在一个隔离的容器或虚拟机中 索引(index): 在ES中, 索引是一组文档的集合 分片(shard): 因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节. 副本(replica): ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy. 对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求, 它们的唯一区别在于只有主分片才能处理索引请求. 在上图示例中, 我们的ElasticSearch集群有两个节点, 并使用了默认的分片配置. ES自动把这5个主分片分配到2个节点上, 而它们分别对应的副本则在完全不同的节点上. 对,就这是分布式的概念. 请记住, 索引的number_of_shards参数只对当前索引有效而不是对整个集群生效.对每个索引来讲, 该参数定义了当前索引的主分片数(而不是集群中所有的主分片数).
关于副本
副本对搜索性能非常重要, 同时用户也可在任何时候添加或删除副本. 正如另篇文章所述, 额外的副本能给你带来更大的容量, 更高的呑吐能力及更强的故障恢复能力. 谨慎分配你的分片 当在ElasticSearch集群中配置好你的索引后, 你要明白在集群运行中你无法调整分片设置. 既便以后你发现需要调整分片数量, 你也只能新建创建并对数据进行重新索引(reindex)(虽然reindex会比较耗时, 但至少能保证你不会停机). 主分片的配置与硬盘分区很类似, 在对一块空的硬盘空间进行分区时, 会要求用户先进行数据备份, 然后配置新的分区, 最后把数据写到新的分区上. 2~3GB的静态数据集 分配分片时主要考虑的你的数据集的增长趋势. 我们也经常会看到一些不必要的过度分片场景. 从ES社区用户对这个热门主题(分片配置)的分享数据来看, 用户可能认为过度分配是个绝对安全的策略(这里讲的过度分配是指对特定数据集, 为每个索引分配了超出当前数据量(文档数)所需要的分片数). Elastic在早期确实鼓吹过这种做法, 然后很多用户做的更为极端--例如分配1000个分片. 事实上, Elastic目前对此持有更谨慎的态度. 稍有富余是好的, 但过度分配分片却是大错特错. 具体定义多少分片很难有定论, 取决于用户的数据量和使用方式. 100个分片, 即便很少使用也可能是好的;而2个分片, 即便使用非常频繁, 也可能是多余的. 要知道, 你分配的每个分片都是有额外的成本的: 每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源 每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降 ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差