1.Lucene基础
(1) 简介
Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供完整的查询引擎和索引引擎;部分文本分析引擎。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能。
(2) 应用场景
对于数据量大,数据结构不固定的数据可采用全文检索方式搜索,比如百度,Google等搜索引擎,论坛搜索,电商网站站内搜索等。
2. Lucene实现全文检索的流程
下面这张图足以说明索引的流程

(1) 绿色表示索引过程,对要搜索的原始内容进行内容进行索引构建一个索引库,索引过程包括:确定原始内容即要搜索的内容—>采集文档—>分析文档—>索引文档
(2) 红色表示搜索过程;从索引库红搜索内容,过程为:用户通过搜索界面—>创建查询—>执行搜索,从索引库搜索—>渲染搜索结果
从互联网上,数据库,文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,信息采集的目的是为了对原始内容进行索引。
在Internet上采集信息的软件一般称为爬虫或蜘蛛,也成为网络机器人,爬虫访问互联网上的每一个网页,将获取到的网页内容存储起来。
Lucene不提供信息才加的类库,需要自己编写一个爬虫程序实现信息采集,也可以通过Nutch,jsoup,heritrix等一些开源软件实现信息采集。
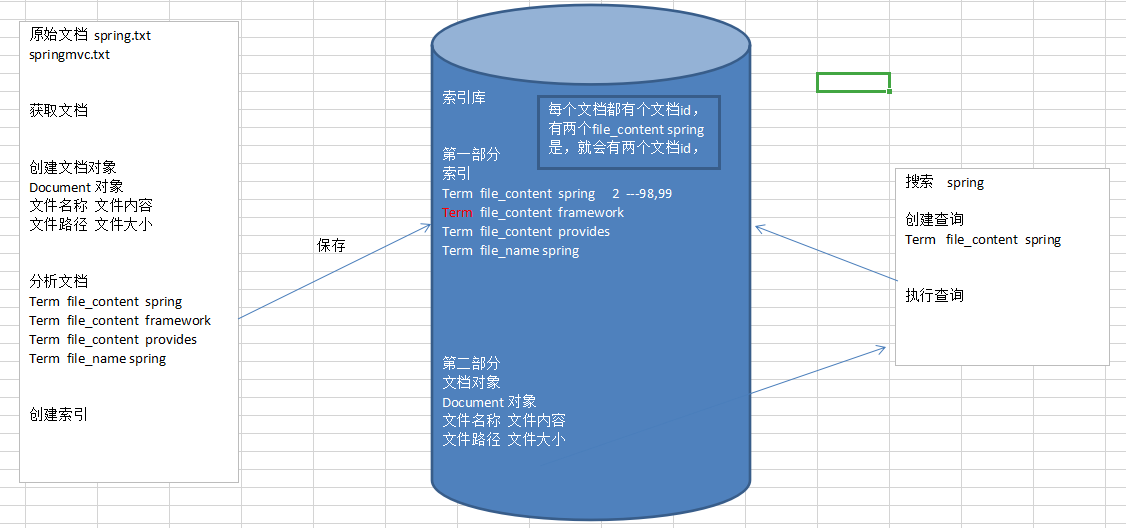
3.创建索引
根据上图,创建索引。获得文档暂时就不做了。
(1) 创建文档对象
获取原内容的目的是为了索引,在索引前需要将原始内容创建成文档,文档中包括一个一个的域(Field),域中存储内容。
可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称,file_path文件路径,file_size文件大小,file_content文件内容),如下图

注意:每个Document可以有多个Field,不同的Dcument可以有不同的Field,同一个Document可以有相同的域(Field)
每个文档有唯一的编号,就是文档Id
(2) 分析文档(分词)
将原始内容创建为包含域(Field)的文档(document),需要在对域中的内容进行分析,分析的过程是经对原始文档提取单词,将字母转为小写,去除标点符号,取出停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个个单词。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的Term。Term中包含两部分一部分是文档的域名,另一部分是单词的内容。相当于Trem<K, V> 例如:文件名中包含apache和文件内容中包含apache是不同的Term。
(3) 创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
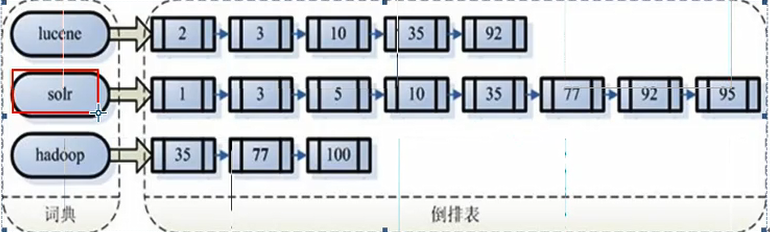
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
传统方法是根据文件找到文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫面方法,数据量大,搜索慢。
倒排索引结构是根据内容(词语)找文档:

倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表。它的规模较小,而文档集合较大。
4.查询索引
(1) 用户查询接口
全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索结果:比如百度搜索框
(2) 创建查询
用户输入查询关键字执行搜索之前需要限购件一个查询对象,查询对象中可以指定查询要搜索的Field文档域,查询关键字等,查询对象会生成具体的查询语法。
例如:语法 “fileName:lucene” 表示要搜索Filed域"fileName"的内容为"lucene"的文档
(3) 执行查询
倒排索引查询,搜索索引过程:根据查询语法在倒排索引词典表中分表找出对应搜索词的索引,从而找到索引所链接的文档链表。
例如:搜索语法为“fileName:lucene”表示搜索出fileName域中包含lucene的文档。
搜索过程就是在索引上查找域为fileName,并且关键之为lucene的Term,并根据term找到文档id列表。
搜索到的文档不止一个,所以是列表形式
(4) 渲染结果