一,问题描述
搭建的用来测试的单节点Kafka集群(Zookeeper和Kafka Broker都在同一台Ubuntu上),在命令行下使用:
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic topicForTest
创建了一个3个分区的Topic如下:(Topic名称为 topicForTest)

使用 Console producer/consumer都能够正常地向topicForTest发送和接收消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topicForTest bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topicForTest --from-beginning
但是在自己的windows 机器的开发环境下,使用kafka client JAVA API (0.10版本)中的KafkaConsumer 却无法接收消息,表现为:在poll()方法中阻塞了。
更具体一点地,是在:org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient类的awaitMetadataUpdate方法中长时间阻塞了。类似问题可参考:这里
然而,在windows机器上,使用telnet client 能够连接到 kafka broker 的9092默认端口。
后面发现是Kafka server中,配置文件 config/server.properties中 没有配置:advertised.host.name 或者 listener 参数。官网查了下这个参数的解释如下:
advertised.host.name Hostname to publish to ZooKeeper for clients to use. If this is not set, it will use the value for `host.name` if configured.
Otherwise it will use the value returned from java.net.InetAddress.getCanonicalHostName(). advertised.listeners Listeners to publish to ZooKeeper for clients to use, if different than the listeners above.If this is not set, the value for `listeners` will be used.
这里的原因是: JAVA API中的kafkaConsumer找不到Zookeeper去获取元数据信息。
The first time you call poll() with a new consumer, it is responsible for finding the GroupCoordinator,
joining the consumer group and receiving a partition assignment.
使用bin/kafka-verifiable-producer.sh --topic topicForTest --max-messages 200 --broker-list localhost:9092 向该Topic中写入200条消息。启动下面的程序测试:

import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class ConsumerTest {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.121.34:9092");
props.put("group.id", "mygroup");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "earliest");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(props);
kafkaConsumer.subscribe(Arrays.asList("topicForTest"));
while(true)
{
System.out.println("nothing available...");
ConsumerRecords<String, String> records = kafkaConsumer.poll(1000);
for(ConsumerRecord<String, String> record : records)
{
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
}
}
}
程序抛出的DEBUG异常如下:
2017-08-17 18:14:48.210 [main] INFO o.a.kafka.common.utils.AppInfoParser SEQ - Kafka version : 0.10.1.0
2017-08-17 18:14:48.210 [main] INFO o.a.kafka.common.utils.AppInfoParser SEQ - Kafka commitId : 3402a74efb23d1d4
2017-08-17 18:14:48.211 [main] DEBUG o.a.k.clients.consumer.KafkaConsumer SEQ - Kafka consumer created
2017-08-17 18:14:48.212 [main] DEBUG o.a.k.clients.consumer.KafkaConsumer SEQ - Subscribed to topic(s): topicForTest
2017-08-17 18:14:48.212 [main] DEBUG o.a.k.c.c.i.AbstractCoordinator SEQ - Sending coordinator request for group group_test109 to broker xxx:9092 (id: -1 rack: null)
.....
.....
2017-08-17 18:14:48.274 [main] DEBUG o.a.kafka.common.network.Selector SEQ - Created socket with SO_RCVBUF = 65536, SO_SNDBUF = 131072, SO_TIMEOUT = 0 to node -1
2017-08-17 18:14:48.275 [main] DEBUG o.apache.kafka.clients.NetworkClient SEQ - Completed connection to node -1
2017-08-17 18:14:48.337 [main] DEBUG o.apache.kafka.clients.NetworkClient SEQ - Sending metadata request {topics=[topicForTest]} to node -1
2017-08-17 18:14:48.396 [main] DEBUG org.apache.kafka.clients.Metadata SEQ - Updated cluster metadata version 2 to Cluster(id = xgdvTIvHTn2dL3cnEm-dRQ, nodes = [ubuntu:9092 (id: 0 rack: null)], partitions = [Partition(topic = topicForTest,partition = 0, leader = 0, replicas = [0,], isr = [0,])])
2017-08-17 18:14:48.398 [main] DEBUG o.a.k.c.c.i.AbstractCoordinator SEQ - Received group coordinator response ClientResponse(receivedTimeMs=1502964888398, disconnected=false, request=ClientRequest(expectResponse=true, callback=org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient$RequestFutureCompletionHandler@144d0b84, request=RequestSend(header={api_key=10,api_version=0,correlation_id=0,client_id=consumer-1}, body={group_id=group_test109}), createdTimeMs=1502964888230, sendTimeMs=1502964888338), responseBody={error_code=0,coordinator={node_id=0,host=ubuntu,port=9092}})
2017-08-17 18:14:48.399 [main] INFO o.a.k.c.c.i.AbstractCoordinator SEQ - Discovered coordinator ubuntu:9092 (id: 2147483647 rack: null) for group group_test109.
2017-08-17 18:14:48.399 [main] DEBUG o.apache.kafka.clients.NetworkClient SEQ - Initiating connection to node 2147483647 at ubuntu:9092.
2017-08-17 18:14:51.127 [main] DEBUG o.apache.kafka.clients.NetworkClient SEQ - Error connecting to node 2147483647 at ubuntu:9092:
java.io.IOException: Can't resolve address: ubuntu:9092
at org.apache.kafka.common.network.Selector.connect(Selector.java:180) ~[kafka-clients-0.10.1.0.jar:na]
at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:498) [kafka-clients-0.10.1.0.jar:na]
at org.apache.kafka.clients.NetworkClient.ready(NetworkClient.java:159) [kafka-clients-0.10.1.0.jar:na]
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.tryConnect(ConsumerNetworkClient.java:454) [kafka-clients-0.10.1.0.jar:na]
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator$GroupCoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:556) [kafka-clients-0.10.1.0.jar:na]
....[main] INFO o.a.k.c.c.i.AbstractCoordinator SEQ - Marking the coordinator ubuntu:9092 (id: 2147483647 rack: null) dead for group xxx
再来看ubuntu上的etc/hosts文件:
127.0.0.1 ubuntu localhost 127.0.1.1 ubuntu localhost
因此,只需要在config/server.properties里面配置 listeners 参数就可以了。
listeners=PLAINTEXT://your.host.name:9092
二,关于Kafka的一些简单理解
①目录结构
前面testForTopic一共有三个分区,因此在 log.dirs目录下关于该Topic一共有三个目录,每个目录下内容如下:
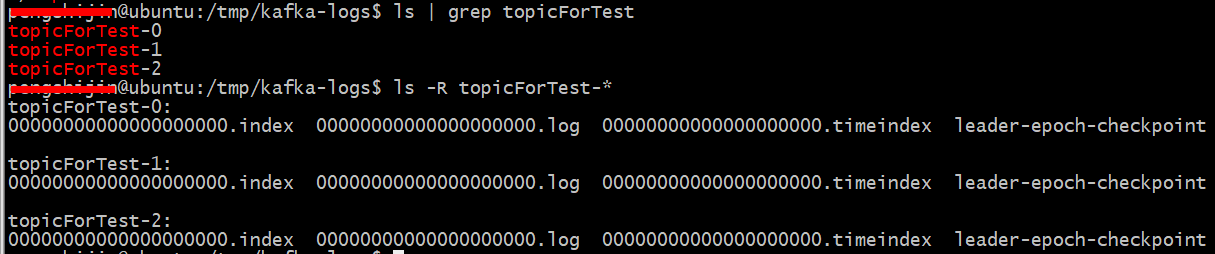
使用命令:./bin/kafka-topics.sh --list --zookeeper localhost:2181 可以查看当前Topic信息。
使用命令:./bin/kafka-consumer-groups.sh --list --bootstrap-server YOUR_IP_ADDRESS:9092 可以查看consumer group的信息
(如果提示:Error: Executing consumer group command failed due to Request METADATA failed on brokers List(ubuntu:9092 (id: -1 rack: null)))(ip地址/主机名/localhost 试试?)
使用命令:./bin/kafka-consumer-groups.sh --bootstrap-server YOUR_IP_ADDRESS:9092 --describe --group groupName 查看某个具体的group的情况

② Topic 、Partition、 ConsumerGroup、Consumer 之间的一些关系
一个Topic一般会 分为 多个 分区(Partition),生产者可以同时向这个Topic的多个分区写入消息,而消费者则以 组 为单位,订阅这个Topic,消费者组里面的 某个消费者 负责 消费 某个Partition。 感觉 Topic 像是逻辑上的概念。
一般是订阅了同一Topic的若干个Consumer 属于某个ConsumerGroup。对于一个ConsumerGroup而言,其中的某个Consumer负责消费某个Partition,则该Partition中的消息就不会被其他的Consumer消费了。如下图:
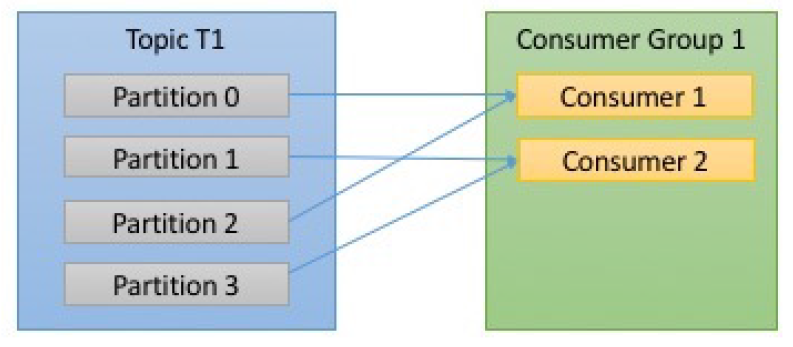
ⓐTopic T1有四个分区,即TopicT1中的消息存储在这四个分区中,它被ConsumerGroup1 这个组中的消费者订阅,其中Consumer1负责消费Partition0和2,Consumer2负责消费Partition1和3。正常情况下,Topic T1中被ConsumerGroup中的消费者 消费一次,也即:TopicT1中的某条消息被Consumer1消费了,就不会被Consumer2消费---对于ConsumerGroup组内成员而言,Consumer1消费了 消息A,Consumer2就不会消费 消息A了。
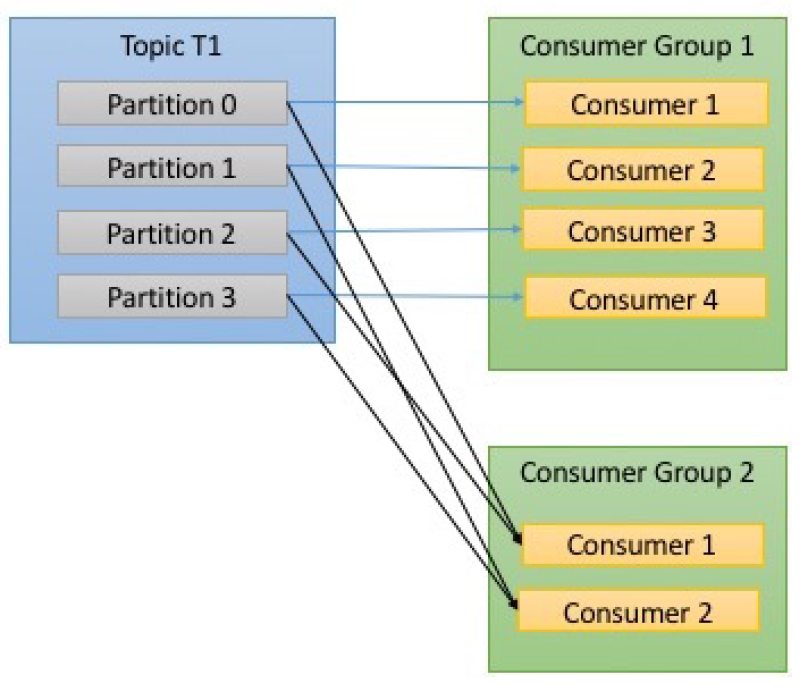
若要想让TopicT1中的消费被多个 消费者消费,可以再创建一个 消费者组ConsumerGroup2,ConsumerGroup2中的消费者 去订阅TopicT1 即可。如下图:TopicT1中的消息,都会被消费2次,一次是ConsumerGroup1中的消费者消费;另一次是被ConsumerGroup2中的消费者消费。
每个ConsumerGroup里面有个 group leader。group leader一般是最先加入到该消费者组的 消费者。group leader从 group coordinator那里接受分区信息,然后分配给各个consumer去订阅。
When a consumer wants to join a group, it sends a JoinGroup request to the group coordinator. The first consumer to join the group becomes the group leader. The leader receives a list of all consumers in the group from the group coordinator and it is responsible for assigning a subset of partitions to each consumer
ⓑConsumerGroup中消费者数量大于 Topic中的分区数量,则某个消费者 将没有 Partition 可消费。如下图:Consumer5,消费不到 任何消息。
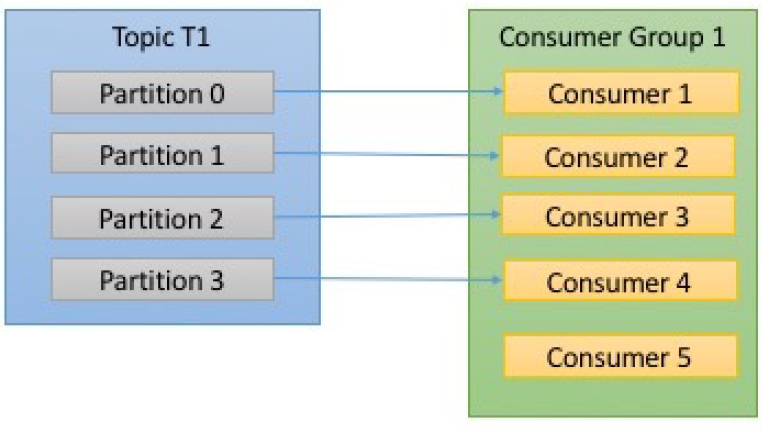
Partition rebalance:
从上面图片中可看出,消息的消费是以 Partition为单位的。若,ConsumerGroup新增了 几个消费者,或者减少了几个消费者,那么Kafka Broker就会重新分配Partition给Consumer。这个重新分配的过程就是 rebalance。比如说,ConsumerA 正在消费PartitionA,某个原因ConsumerA挂了,PartitionA中的消息就没有Consumer消费了。因此Broker发现ConsumerA挂了之后,就要把PartitionA交给另外还存活的Consumer去消费。
The event in which partition ownership is moved from one consumer to another is called a rebalance
rebalance过程会有很多问题,比如:1,在 rebalance这个过程中,Conusmer是不能消费消息的。
During a rebalance, consumers can’t consume messaged, so a rebalance is in effect a short window of unavailability on the entire consumer group
2,会造成消息被重复消费。比如ConsumerA 得到了 PartitionA 的几条消息,进行了一定的处理,然后还未 来得及 向Broker 确认它消费完了这几条消息(未commit),它就挂了。Broker rebalance之后,把PartitionA 交给了ComsumerB订阅,那么 ConsumerB 也会得到 ConsumerA 处理了 但未提交 的 那几条消息。那这几条消息 就被 重复消费了。
3,Broker是如何发现Consumer挂了的呢?
这是通过KafkaConsumer 中的poll(long )方法实现的。
③KafkaConsumer 的 poll(long )方法
poll方法干了哪些事儿?coordination、分区平衡、consumer与broker之间心跳包 keep alive、获取消息...
Once the consumer subscribes to topics, the poll loop handles all details of coordination, partition rebalances, heartbeats and data fetching
消费者必须不停地 执行 poll 方法,一是不断地从kafka那里获得消息,另一个是告诉kafka,我没有发生故障,与 broker是 keep alive的。
consumers must keep polling Kafka or they will be considered dead and the partitions they are consuming will be handed to another consumer in the group to continue consuming.
poll(long )方法有一个 long 类型的参数,这些参数受 consumer 参数配置的影响,也与具体的应用 如何 处理消息 有关。
This specifies how long it will take poll to return, with or without data. The value is typically driven by application needs for quick responses - how fast do you want to return control to the thread that does the polling?
消费者消费完消息后,不再消费了,要记得关闭。因为,consumer要离开了,那么就会造成 rebalance,consumer.close() 使得consumer主动 通知 Group Coordinator 进行 rebalance,而不是靠 GroupCoordinator去等待一段时间发现 Consumer离开了(Consumer不再执行poll方法了),然后再进行 rebalance。
consumer.close();
④Kafka 中的一些配置参数
Broker的配置参数;Producer的配置参数;Consumer的配置参数
auto.commit.interval.ms The frequency in ms that the consumer offsets are committed to zookeeper.(consumer 隔多久提交 offsets --消费指针)
group.id A unique string that identifies the Connect cluster group this worker belongs to.
heartbeat.interval.ms
session.timeout.ms ....这些参数的设置与具体的应用相关,也会影响 rebalance时机,具体不是太了解。
具体的配置参数可参考:Kafka配置参数解释。
参考文献:
书籍:Kafka_ The Definitive Guide
原文:http://www.cnblogs.com/hapjin/p/7396063.html